AI解説
情報源:対象論文の本文全文(PDF・全9ページ、Abstract〜References)を通読して記述。掲載している図表(Fig.1〜6・Table I/II)も論文オリジナルを PDF から切り出して載せている。本文に書かれていない事項は補わない。著者の GitHub 実装コードは情報源にしていない。
一言で
JUmPER は、Jupyter のセル実行に性能計測を組み込んだ Jupyter カーネル。セルを実行するたびに CPU / GPU / IO / メモリといったシステムメトリクスを自動収集し、実行したユーザコードとひもづけて保存して、Jupyter 内の magic コマンドでその場で対話的に可視化する(粗粒度モニタリング)。さらに必要なセルだけ Score-P によるコード計装を有効化して、trace / profile などの詳細な性能イベントも取れる(細粒度分析)。計装モードで生じるカーネルのオーバーヘッドを、並列 marshalling と in-memory(pipe)通信で削減しつつ、探索的プログラミングの体験を壊さないことを重視している。先行研究 Werner et al. 2021(Bridging) の Score-P カーネルを拡張したもの。
背景・動機
- 機械学習(ML)アプリケーションの分析やリソース効率の良いデプロイには、CPU・GPU 使用率などの計算性能が重要。HPC センターの高速ハードウェアが ML の成功を支えており、効率的で持続可能なシステムにするにはリソース利用の分析が欠かせない。
- 従来のソフト開発と違い、ML コミュニティは探索的プログラミングでワークフローを作る。これにはジョブ実行中もユーザをループに留める対話的 HPC が要り、JupyterHub のような仕組みが Jupyter インタフェース経由で対話的に HPC リソースへアクセスさせている。
- しかし Jupyter には性能調査の手段が乏しい。時間の計測だけではユーザコードの挙動はわからず、フレームワーク依存の手法では ML ワークフロー全体を捉えられず、しかも Jupyter に統合されていないため使い勝手が悪い。結果、Jupyter コミュニティには使いやすく包括的な性能エンジニアリングのツール支援が欠けている。
- 一方 HPC コミュニティには Score-P・HPCToolkit・Pika・Vampir など性能エンジニアリングの蓄積がある。粗粒度のシステムメトリクス監視でハードウェアのボトルネックの当たりをつけ、細粒度の性能イベント追跡でユーザコードを深く見る、という二層の分析を、Jupyter の対話的 HPC・探索的プログラミングにシームレスに組み込むことが求められている。
問題と課題(区別して整理)
- 問題(解きたいこと):データサイエンス/ML の探索的プログラミング中に、性能エンジニアリングが手軽に行えないこと。フレームワーク専用 Profiler(TensorFlow / PyTorch Profiler)は ML ワークフローの多様性に対し汎用性に欠け、汎用の Score-P(Python bindings・Jupyter カーネルもある)は適切な設定・インストールと Vampir 等の外部可視化ツールを要して敷居が高い。
- 課題(この研究がやること):Jupyter のカーネルとして性能計測を組み込み、(1) 常時オンの軽量なモニタリングと (2) 必要時のみの Score-P 計装という二段構えを、Jupyter の対話的な使い勝手・開発環境を変えずに提供すること。あわせて、計装モードで生じるカーネル実行オーバーヘッドの削減も課題に含む。
関連研究(位置づけ)
- 粗粒度の監視ツール:htop・Pika・各種 Jupyter プラグインはシステム全体や特定プロセスの CPU/GPU 使用率を集めるが、ユーザコードには踏み込まない。
%prun・%timeitはコード片の実行時間を測れるがグラフ表示がない。 - 細粒度の分析ツール:TensorFlow / PyTorch Profiler は性能データとモデル構造を見られるが単一フレームワーク専用で一般性に欠ける。Score-P はフレームワーク非依存で、(1) profiling(関数ごとの実行時間・メモリ等の要約の蓄積)と (2) tracing(関数の出入りなどイベントを時系列で記録)を支える。Score-P Python bindings/Score-P Jupyter カーネルもあるが、適切な設定・インストールと Vampir 等の外部ツールが要る。
- 可視化:trace / profile を Jupyter 内で表示する試み(PiPit、Oden et al.)もあるが、著者らの知る限り大量の性能イベントを高速・包括的に表示できるのは Vampir のみ。簡易な初期把握には前者でも足りる。
- → そこで JUmPER は、(1) システムメトリクスによる粗粒度の洞察(適切なグラフ付き)と(2) Score-P による細粒度の洞察(+可視化)を統一インタフェースで提供する。
提案手法:2モードを持つ Jupyter カーネル
JUmPER は Score-P Python カーネルを拡張した Python 実行カーネルで、設定は Jupyter 慣習どおり magic コマンドと環境変数で行う。次の二層のインタフェースを持つ(Fig.1)。
- Monitoring(常時オン):CPU 使用率・GPU 使用率・IO バイト/操作・メモリ使用率を記録。
- Instrumentation(必要時のみ):Score-P で性能イベントを記録。
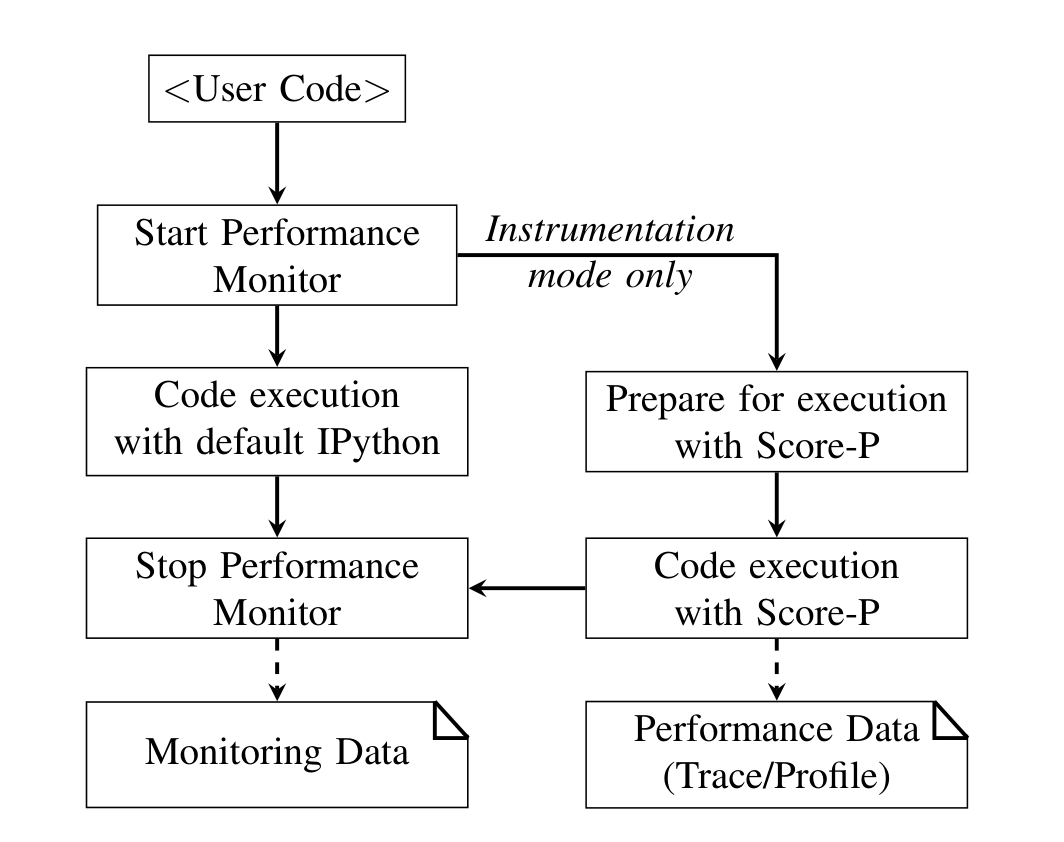
原論文 Fig.1:性能モニタリングは常時有効でシステムメトリクスを集める。Score-P は計装モードでのみ使われ、trace / profile などの追加データを与える(右側のパスは計装モードのみ)。
(1) Monitoring モード(常時)
- セルを実行すると、まず別の Python プロセスで性能モニタを起動し(セルごとに個別に起動)、その間に既定の IPython でユーザコードを実行する。終了後にモニタを止めてデータを回収する。
- 収集頻度は環境変数
JUMPER_REPORT_FREQUENCYで指定。メトリクス収集には psutil と(Nvidia GPU 用に)pynvml を使う。%%set_perfmonitorでモニタを差し替えられるモジュール式インタフェースを提供し、既定は単一ノード用だが、ユーザ定義メトリクスやマルチノード構成にも対応できる。 - 実行後、直前セルの性能サマリ(実行時間、CPU/メモリ/GPU 使用率の mean/max/min、I/O 特性)を自動表示する。
- 性能データとあわせて、実行したユーザコードの履歴を index とタイムスタンプ付きでカーネルのプロセスメモリに保存する。従来の HPC 監視ツールと違い、計測データがユーザコードへの参照を保持するので、タイムスタンプだけに頼らずコードを行単位でボトルネック分析できる(Jupyter の探索的プログラミングに沿う)。
- オーバーヘッドは無視できる程度(k 秒ごとに集めるだけ、k はユーザ制御)。
(2) Instrumentation モード(必要なときだけ)
%%execute_with_scorepセル magic を付けたセルでのみ有効化。Score-P はアプリの開始点と終了点を要するため、ユーザコードを新しいプロセスで実行しなければならない。- 素朴にプロセスを分けると、それまでの変数・関数定義などのインタプリタ状態が失われる。そこで親カーネルのインタプリタ状態(メモリ上の Python オブジェクト=グローバル辞書)を、転送可能な形式に変換(marshalling、pickle 等)して Score-P プロセスへ渡し、向こうで読み戻し(unmarshalling)してから計装実行する。実行後は逆向きに marshalling/unmarshalling して親カーネルへ状態を戻す(Fig.2)。
- この受け渡しはユーザから隠蔽されるので、探索的プログラミング体験を損なわずに trace / profile が得られる。計装モードでも (1) のモニタリングは併用され、粗粒度と細粒度のデータを一緒に提供する。Score-P の環境変数・Python bindings 引数も追跡して計装プロセスへ渡す。
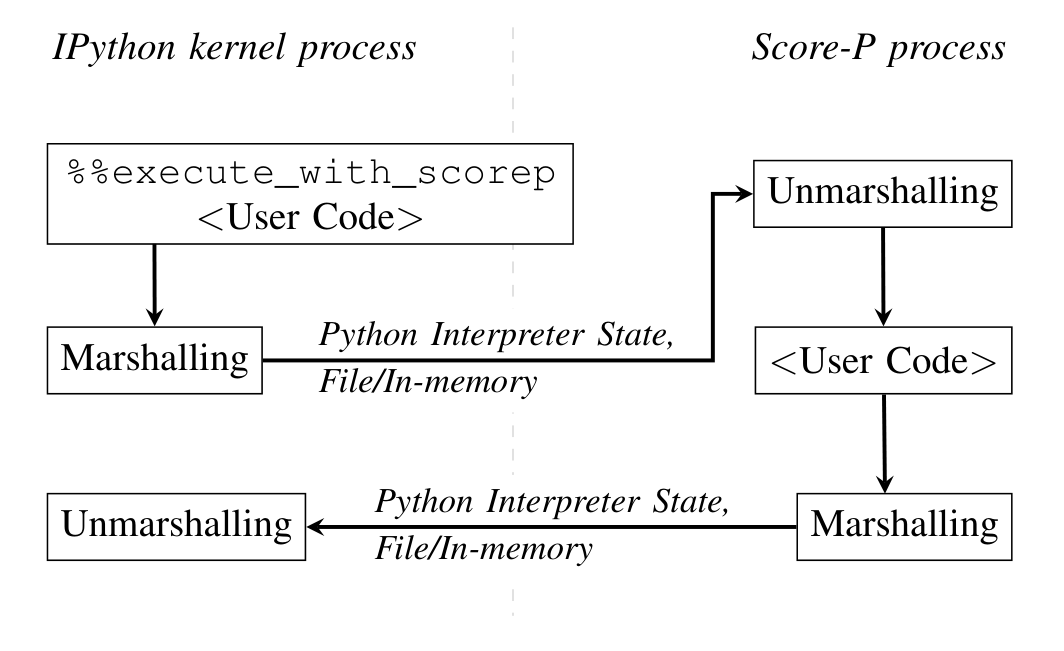
原論文 Fig.2:%%execute_with_scorep で実行する際、IPython カーネルプロセスと Score-P プロセスの間で、Python インタプリタ状態を marshalling/unmarshalling して受け渡す(往路で渡し、復路で戻す)。転送はファイル経由かメモリ内(pipe)で行える。
Multi-cell モード・write-file モード
- Multi-cell モード:意味的な理由でコードを複数セルに分けつつ、アプリ全体の計算性能を一望したい場合に、連続する複数セルをまとめてモニタリング/Score-P 計装する。
%%enable_multicellmode/%%finalize_multicellmode/%%abort_multicellmodeで制御。 - Write-file モード:Jupyter セルから Python スクリプトをエクスポートする。
%%execute_with_scorepを付けたセルだけ Score-P 計装を有効に、それ以外は無効にしたスクリプトと、Score-P 環境変数を設定して Python を Score-P 付きで起動するシェルスクリプトを生成する。Jupyter 本来のスクリプト書き出し機能と整合し、デプロイ後の追加計測に役立つ。%%start_writefile/%%end_writefileで制御。
カーネル実行オーバーヘッドの削減
計装モードでは、インタプリタ状態の永続化(marshalling)に伴うオーバーヘッドが生じる。先行研究と違い全セルではなく Score-P で実行するセルだけ永続化が要り(他セルは稼働中の IPython にそのまま渡す)、モニタリングのオーバーヘッドも無視できる。永続化のコストを抑えるため2つの手を打っている。
1. 並列 marshalling
- Python の multiprocessing で marshalling 操作を複数プロセスに分散する。インタプリタ状態を表すグローバル辞書を n 分割するが、オブジェクトのサイズは不均一なので、貪欲法で割り当てる(Algorithm 1):オブジェクトをサイズ降順にソートし、各オブジェクトを現時点で合計サイズが最小のワーカ集合に加えていく。最適分割は NP-hard なので貪欲法は最適とは限らない。
- unmarshalling(読み戻し)の並列化は難しい。Python の GIL が同一プロセスメモリへの状態ロードの並列化を妨げるため、現状は逐次(n 分割を順に処理)。GIL が解放される Python 3.12 以降では並列 unmarshalling の余地があり、さらにオーバーヘッドを下げられる可能性がある。
2. In-memory(pipe)通信
- カーネルプロセスと Score-P プロセスの間で、marshalling 済み状態をファイル(ディスク)ではなくパイプ(メモリ内)で転送する。ファイルシステムへの依存をなくせるので、高速ストレージのない環境で有利。ただしパイプは同期的な read/write(読み手と書き手が接続して転送)なので計算オーバーヘッドは増えるが、メモリ内転送で全体は速くなるはず。追加メモリが要るのが制約。
- in-memory とファイルベースの両方を残し、
%%marshalling_settingsで切り替えられる。同コマンドで marshalling バックエンド(pickle / dill / cloudpickle / 自作の並列 marshalling)も切り替えられる。
ユーザインタフェース
設定・操作は magic コマンドと環境変数で行う(Table I)。可視化は matplotlib(ズーム・移動できる対話的グラフ)と itables(index/タイムスタンプ付きのコード履歴)を使い、表示メトリクスはドロップダウンで選べる。Multi-cell モードではグラフのどの部分がどのセルかも示す。計測データは %%perfdata_to_json / %%perfdata_to_variable で JSON や Python 変数に書き出せる(ここでは VSCode/PyCharm の独自 UI ではなく標準の Jupyter Web インタフェースを前提)。Score-P の trace / profile は Vampir(小さい trace なら Pipit)で表示する。

原論文 Table I:主な magic コマンド(コード履歴・グラフ表示、エクスポート、marshalling 設定、Score-P 引数、multi-cell、write-file)と環境変数(JUMPER_SAMPLING_RATE:メトリクス収集のサンプリングレート、JUMPER_MIN_REPORTS:セルを保存するのに要るデータ点数=import や関数定義のような軽いセルを捨てて計算負荷の高いセルに絞るための設定)。
マルチノード対応
性能モニタはモジュール式で、Slurm のようなバッチスケジューラ環境では srun でジョブ割り当て内の各ノードに接続してメトリクスを集めるカスタムモニタを定義でき、ssh で分散ノードに繋ぐ構成も可能。ただしプロセスレベルのメトリクス監視は並列化機構の知識(並列プロセスの ID 取得)が要り難しい。著者らの ZIH JupyterHub では直近1年で 92% が単一ノード利用、単一ノードジョブのうち 60% が GPU を1つ以上、37% が複数 CPU、21% が両方を使う。よって本研究は単一ノードで複数 CPU・1つ以上の GPU を使うジョブを主対象とする。マルチノードでは純粋なシステムメトリクスより並列部分間の相互依存が重要になり、その場合は MPI ベースのマルチノードに対応する Score-P を使う Instrumentation モードが有効(多くの ML フレームワークは各プロセス起動時に MPI_Init すれば対応可能)。
評価
実験は TU Dresden ZIH の JupyterHub(AMD EPYC 7352 の 8コア・64GB RAM・3.5TB ローカル NVMe・Nvidia A100 GPU 1基)で実施。ここでは Jupyter セッション全体が単一の Slurm ジョブとして動くため、複数割り当て間の状態永続化は不要で JUmPER を容易に統合できる。
(1) 並列モンテカルロ・シミュレーション
π を推定する単純な例。independent な反復を Python multiprocessing で複数コアに分散する。最初のセルで compute_pi と import を定義し、次のセルで 10⁹ 反復を4コアに分散して呼ぶと、JUmPER のサマリが CPU 使用率がおよそ 50%(半分のコアしか使っていない)と表示。そこで次のセルで同じ反復数を8コアに分散するとほぼ 100% になる。Fig.3 はコード履歴と性能データの表示例で、同じコードを再実行しても index は上書きされず別タイムスタンプの新エントリが追加される。コードを index ごとに pretty-print でき、セル[11](4コア・約50%)とセル[12](8コア・ほぼ100%)の CPU 使用率グラフを見比べられる。コード履歴と計測データをセルごとに並べて持てることが、対話的 HPC での性能エンジニアリングの肝になる。
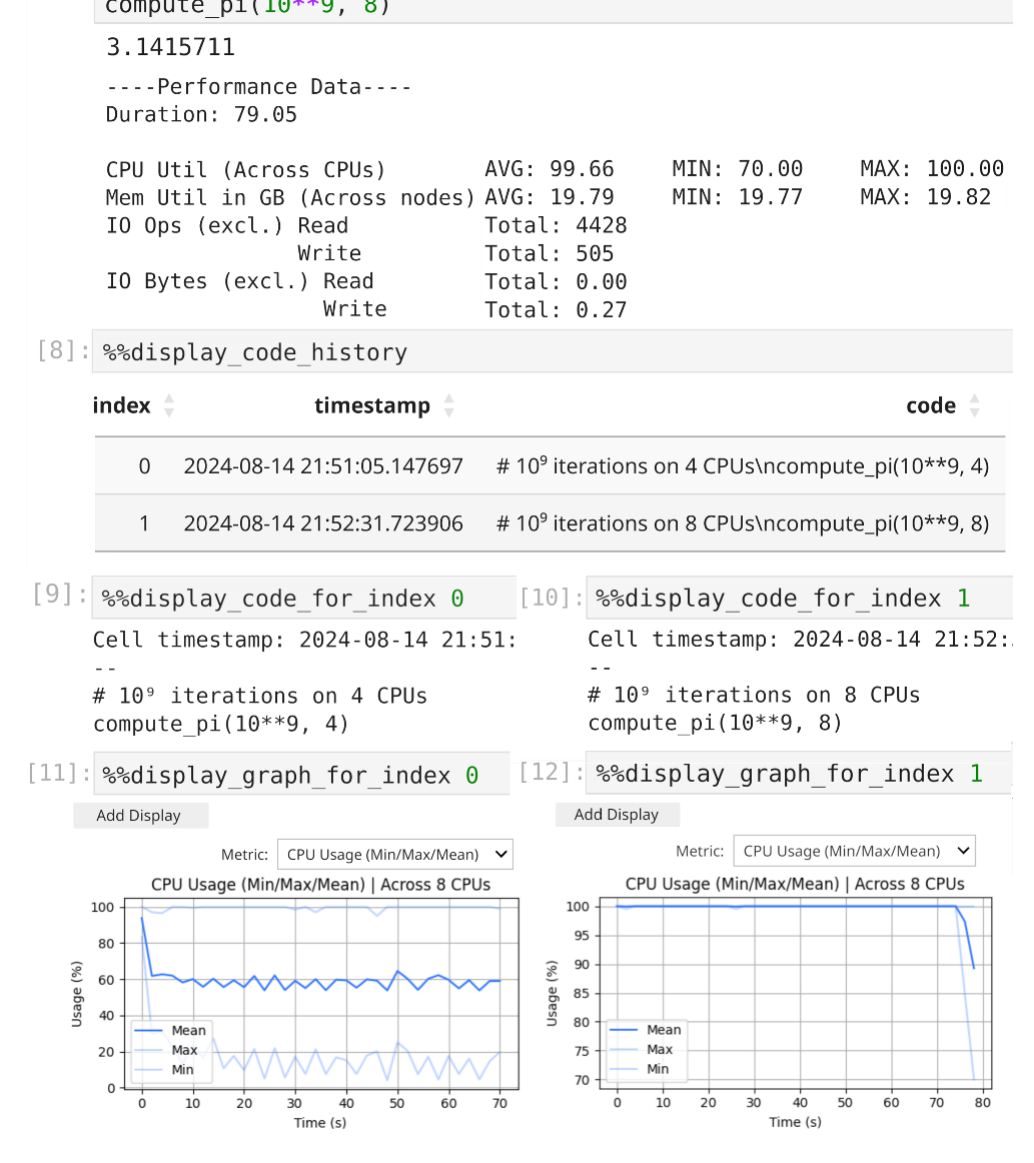
原論文 Fig.3:2つのセル実行に対する各種 magic コマンドの出力。セル実行後の性能サマリ、%%display_code_history のコード履歴(index・タイムスタンプ)、%%display_code_for_index のコード表示、%%display_graph_for_index の CPU 使用率グラフ(4コア時は約50%、8コア時はほぼ100%)。
(2) GPT 風 ML モデルの学習
PyTorch で小さな GPT 風モデルを1エポック・縮小データセットで学習する例(先行研究 Werner et al. 2021 の NLP 例)。学習セルに %%execute_with_scorep を付ける。%%display_graph_for_last の出力(Fig.4)では、GPU 使用率が高い一方、一部 CPU は稼働・他はアイドル、主記憶は約 28GB 使用、データの読み(学習入力)と書き(モデル保存)が見える。
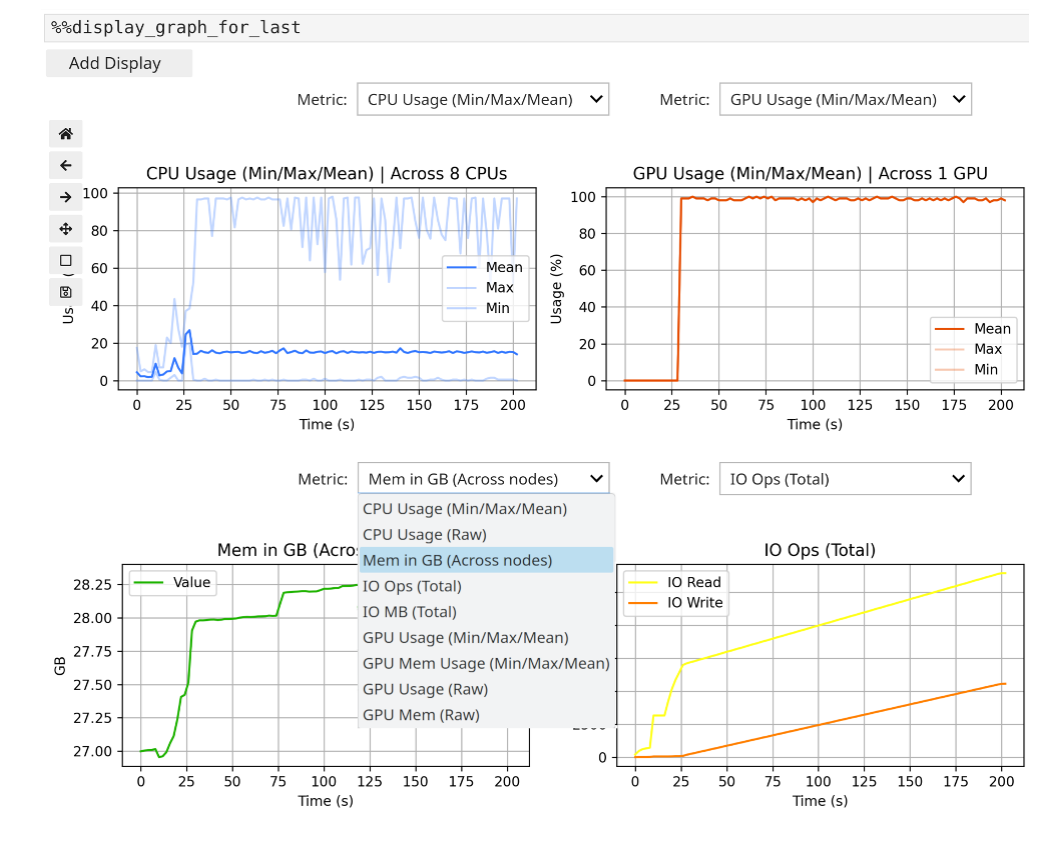
原論文 Fig.4:ML モデル学習後の %%display_graph_for_last 出力。CPU 使用率(左上)、GPU 使用率(右上、ほぼ100%)、メモリ使用量(左下、約28GB)、I/O 操作(右下)が対話的グラフで表示され、メトリクスはドロップダウンで選べる。
さらに学習セルの性能データを Score-P で記録し、Vampir で表示したのが Fig.5。タイムライン(x 軸)×複数スレッド(y 軸)で、CUDA カーネル(赤)、PyTorch 関数(黄)、CPU 上の CUDA 同期(紫)、I/O セレクタ(緑)、スレッド待機(青)が色分けされる。初期化後、CUDA カーネルが GPU 上で計算(CUDA[0:7] スレッド)、PyTorch 演算は CPU 上で周期的に CUDA 同期しながら実行され、Orphan thread 1 が I/O を担う。Orphan thread とは、Score-P Python bindings が Python 内部のスレッド管理を捕捉しないため、Score-P がスレッドの開始/終了を知らされていないスレッドを指す。
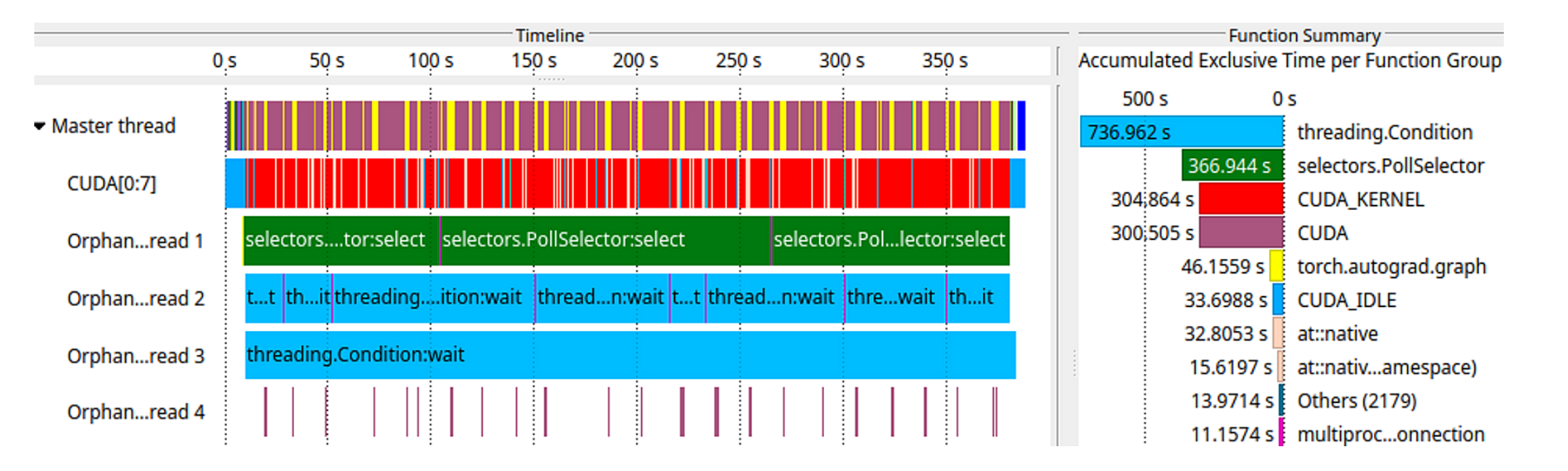
原論文 Fig.5:PyTorch による ML 学習の trace を Vampir で表示(左:タイムライン、右:関数グループごとの累積排他時間)。
(3) オーバーヘッド削減の評価
- モニタリングモード:モンテカルロ例で、10Hz までのサンプリングでもオーバーヘッドは < 1s。多くの場合 1Hz / 0.5Hz で十分。
- 計装モード:オーバーヘッドの原因は2つ。(a) Score-P 計装そのもの(GPT 風学習で計装あり 368s/なし 343s = 7%、フィルタ機構で制御可能)、(b) インタプリタ状態の永続化処理。本研究は (b) の削減に注力。永続化の評価環境は AMD EPYC 7702 の 1–16コア・256GB メモリ・200GB ローカル SSD、各実験 20 回平均(標準偏差は無視できる)。
- 並列 marshalling(Fig.6):marshalling はほぼ線形にスケール(コア倍増で時間ほぼ半減)。例えば 96GB では 123s(1コア, 1×)→66s(2, 1.83×)→33s(4, 3.67×)→18s(8, 6.83×)→10s(16, 12.1×)。ただしこの実験はオブジェクトがサイズ的に均等分布する設定で、実アプリでは分布が偏り並列化が有効とは限らない。一方 unmarshalling は逐次のためコア数によらずほぼ一定で、Amdahl の法則上のボトルネックになる。ただしネイティブの unmarshalling は marshalling より速く、1コアでは概ね marshalling 3/5・unmarshalling 2/5 の配分。それでも並列 marshalling は全体のオーバーヘッドを大きく減らす。
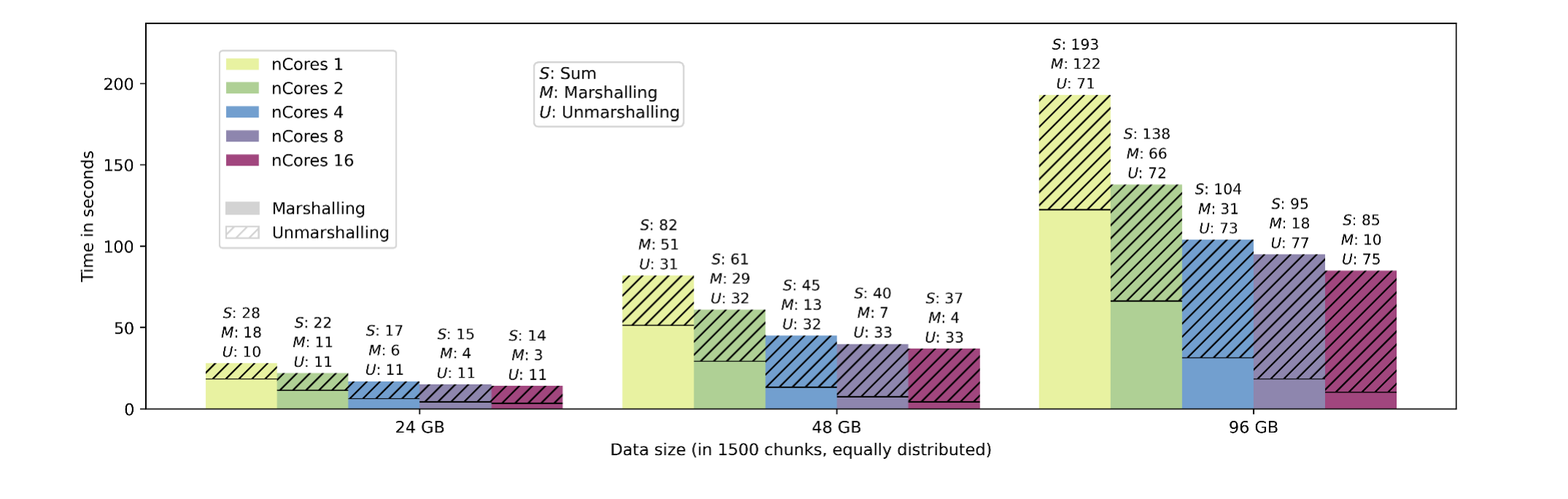
原論文 Fig.6:ディスク/ファイルベースの並列 marshalling の実行時間(並列度 1–16 コア × データサイズ 24/48/96GB)。S=合計、M=marshalling、U=unmarshalling。marshalling 部分(M)は並列度を上げると縮むが、unmarshalling 部分(U)はほぼ一定。
- In-memory 通信(Table II):24GB のデータについて、in-memory と(SSD ベースの Lustre・InfiniBand 接続の)ファイルベースを比較。低並列度では in-memory が有利(1コアで 25s 対 31s)だが、16コアではファイルベースの方が速い(5s 対 4s)。理由は Python のパイプ管理のオーバーヘッドや、ディスク書き込み時のキャッシュ効果が考えられる(要追加調査)。in-memory は中間結果をメモリに保持するためより多くのメモリを要する。両者の有効性はハードウェアとユースケース次第で、どちらも JUmPER の UI から切り替えられる。
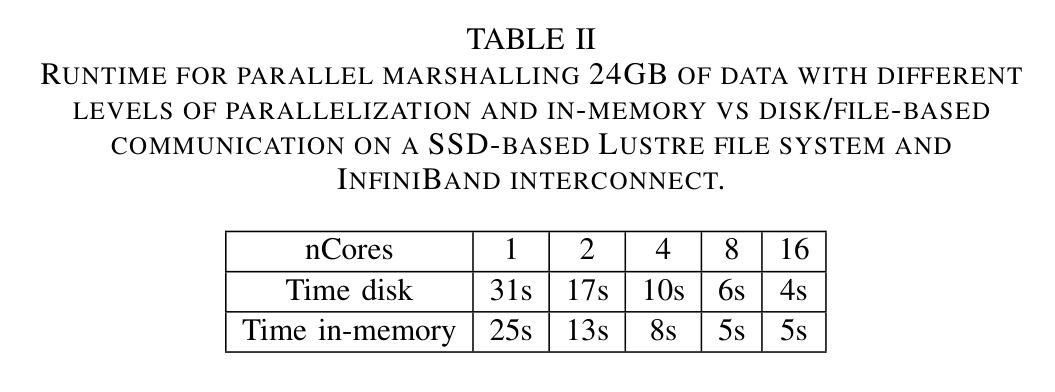
原論文 Table II:24GB を並列 marshalling した際の実行時間(1–16 コア、ディスク vs メモリ内)。低並列度では in-memory が速く、16 コアではディスクが速い。
先行研究との関係
- 細粒度の計装機構は、著者ら自身の先行研究 Werner et al.(2021)”Bridging between data science and performance analysis: tracing of Jupyter notebooks”(AIMLSys 2021) の Score-P Jupyter カーネルを拡張したもの。本論文の GPT 風 ML 学習の評価例もこの先行研究のものを踏襲している。
- Score-P の Python 対応は Gocht et al.(2021, Python bindings)、可視化は Vampir(Knüpfer et al. 2008)、Score-P 本体は Knüpfer et al.(2012)に基づく。粗粒度監視の関連として Pika(Dietrich et al. 2020)・HPCToolkit、trace 可視化の関連として Pipit・Oden et al.(2024)を挙げている。
まとめ・今後
- JUmPER は、実行ユーザコードと監視性能データを一緒に集めて Jupyter 内で対話的に可視化し、必要に応じて Score-P による細粒度分析も行えるカーネル。モンテカルロ(並列 CPU)と ML 学習の例で機能を示し、並列 marshalling と in-memory 通信で計装時のオーバーヘッドを抑えた。伝統的 HPC とデータサイエンスの橋渡しを狙う。カーネルと並列 marshalling は GitHub(
score-p/scorep_jupyter_kernel_python)で公開。 - 今後は、エネルギー効率メトリクス(perun / Muriedas et al.)や AMD GPU(pyrsmi)の追加、ZIH HPC の他監視系から Lustre I/O などを取り込むカスタムモニタ、Slurm など非ローカル環境でのリソース割り当ての推奨(割り当てたハードが効率的に使われていなければ自動通知)、さらに LLM を使ったコード効率改善(Niu et al. 2024 の議論を踏まえ、性能情報と組み合わせてよりリソース効率の良いコードを提示)を計画している。
Q&A
(まだなし)