AI解説
DOI: https://doi.org/10.1145/3486001.3486249(ACM Digital Library) 情報源: 本文全7ページ(PDF)を取得して通読。図1〜5・表1〜2・アルゴリズム(カーネルの3フェーズ)まで本文から確認した。著者: Elias Werner, Lalith Manjunath, Jan Frenzel, Sunna Torge(TU Dresden / ZIH)。実装は公開: https://github.com/scorep/scorep_jupyter_kernel_python。
一言で
データサイエンス(DS)の開発で広く使われる Jupyter に、HPC(高性能計算)由来の計測フレームワーク Score-P を統合し、ノートブックのセル実行をプロファイル/トレースできるようにする取り組み。そのために IPython の標準カーネルを置き換える独自カーネルを設計・実装した。鍵は「セルごとに新しい Python プロセスを起動して計測の開始/終了点を作り、失われる対話性(前セルの定義・変数)を自前で復元する」という設計。文字レベル GPT(NLP)に適用し、収集データを Cube(プロファイル)と Vampir(トレース) で可視化した。2セルでの計測オーバーヘッドは 12.55 秒だった。

補足図(AI生成): 本論文の流れの要約。Jupyter のセル実行を独自カーネルが新プロセス+Score-P で計測してトレース/プロファイルを取り、HPC 領域の既存ツール(Cube・Vampir)で可視化する、という「DS と性能解析の橋渡し」。詳細な内部構造は本文の図2を参照。
背景・問題
データ量の増大により、IoT・モバイル・医療など多様な領域でデータサイエンス(DS)・データ駆動 AI のアプリケーションが立ち上がった。これらの研究開発は計算集約的である一方、開発環境の計算資源は限られ、さらにモバイル等のターゲット環境の資源制約も開発時に考慮しなければならない。したがって性能分析は開発プロセスの重要な柱であるべき——という認識が出発点。
ここで本論文は用語をはっきり区別する。「性能(performance)」とはハードウェア寄りの計測値、すなわち実行時間・メモリ使用量・消費電力を指す。F1スコアや Accuracy のような ML 指標は「性能」と呼ばない(明示的に避ける)。本論文が扱うのはあくまで前者。
そのうえで本論文が解こうとする問題は次の通り:
- DS コミュニティには、実行時間・資源使用量を調べるためのツール支援が欠けている。
- Jupyter 標準の magic コマンド(
%prun・%timeit)は粗く、関数の文脈(スレッドや呼び出し元)を返さない。%prunはグラフ表示がなく、Python プロファイラ依存なので CUDA など非 Python 関数には使えない。 - TensorFlow Profiler のようなフレームワーク固有のプロファイラはあるが、そのフレームワーク専用でツールを再利用できない(フレームワークを変えると分析者に見える情報が変わる)。
- 一方 HPC 領域には Score-P のような確立した計測フレームワークがあり、標準化された形式でデータを出すので複数の解析ツール(Vampir・Cube・TAU・Periscope)を使い分けられる。だが Score-P はこれまで DS/ML の文脈で手が届かなかった。
研究目標(本文の言葉): 「最先端の手法でアプリケーションの性能分析を行えるよう、性能分析ツールを DS コミュニティにどう組み込めるか?」
つまり問題=DS の開発現場に、再利用可能で網羅的(holistic)な性能分析の手立てがない。本論文の課題(やること)=確立した HPC ツール Score-P を Jupyter に橋渡しする、独自カーネルの設計・実装・評価。
前提知識:Jupyter のアーキテクチャと性能計測ワークフロー
Jupyter の構成(図1):ブラウザ(ユーザがセルを編集)↔ ノートブックサーバ(HTTP/Websocket、*.ipynb に保存)↔ カーネル(言語固有の実行担当)。Code セルを実行するとサーバがセル内容をカーネルへ送り、結果を受け取って保存・表示する。カーネルは差し替え可能で、メッセージキューにより一度に1セルだけ逐次実行される。本論文はこの「カーネルを差し替えられる」性質を突く。
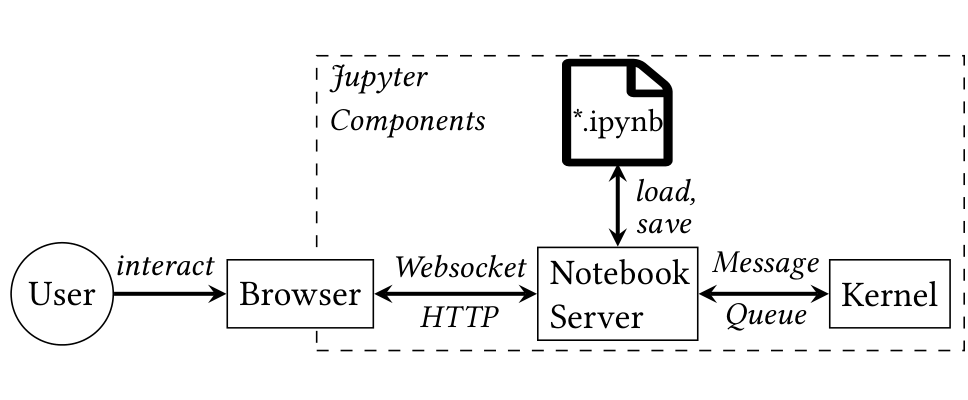
図1: Jupyter の一般的なインフラ。ユーザ⇄ブラウザ⇄(HTTP/Websocket)ノートブックサーバ⇄(メッセージキュー)カーネル、ノートブックサーバが *.ipynb をロード/セーブする。
性能計測の2段ワークフロー:①プロファイル=関数ごとの実行時間など累積サマリを作る、②トレース=プログラムが定義領域に「いつ」出入りしたかを時系列で記録する。Score-P は HPC 向けに開発された確立フレームワークで、スケーラブル、プロファイル/トレース両対応、複数形式で出力(→ Vampir/Cube/TAU/Periscope へ)。MPI・pthreads・CUDA をネイティブ対応するが、Python のイベント収集には拡張「Score-P Python bindings」が必要。利用には対象アプリへのインスツルメンテーション(計装)が要る。
提案手法:Score-P と Jupyter の融合(FUSING SCORE-P AND JUPYTER)
二つの既存インタフェースを組み合わせる:(1) Jupyter ラッパーカーネルインタフェース(標準 IPython カーネルの土台を使いつつ、言語実行の定義を上書きできる)、(2) Score-P Python bindings(Score-P を呼び出し Python のトレース/プロファイルを行う Python モジュール)。
設計上の核心問題:「常時走るカーネル」に「開始/終了点」をどう作るか
ねらいはノートブック全体ではなく、ユーザコードを含むセルのプロファイル/トレース。だが Jupyter カーネルは継続的に走り続けるプロセスであり、Score-P はアプリの開始点と終了点を必要とするため、素朴な統合ができない。本文は2案を比較する:
- 案1:Score-P API の init/finalize を明示的に呼ぶ。→ ただし Score-P イベントの非自明な同期が追加で必要になる。
- 案2:セルごとに新しいプロセスを起動して単一セルを実行し、明確な開始/終了点を得る。→ ただし新プロセスを起こすと前のユーザ入力・実行結果が失われ、Jupyter の対話性が壊れる。
著者らは案2を採用し、失われる対話性を必要な機能を自前で再実装して模倣(”meme the interactivity”)する。これが本カーネルの設計思想。
カーネルの3フェーズ(図2)
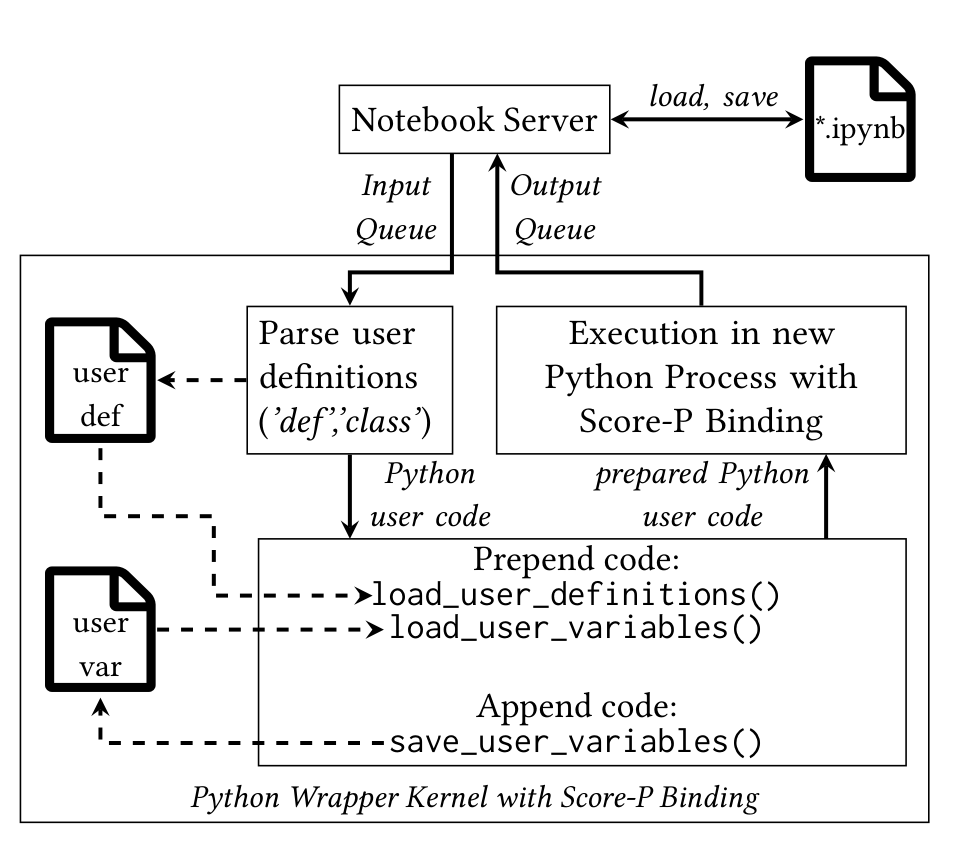
図2: カーネルの内部。入力キューから受けたユーザコードを、(1) ユーザ定義の抽出(user def ファイルへ)、(2) ロード/セーブ関数の前後付加、(3) Score-P バインディング付き新 Python プロセスでの実行、の3段で処理し、結果を出力キューへ戻す。
- ユーザ定義のパース:ユーザコードから
import・def(関数定義)・class(クラス定義)を探し、user defファイルに保存して後続セルで使えるようにする。後のセルが同名の定義を出したら上書き同期する(表1の例:t3 でdef A()が新しい中身に置き換わる)。 - ユーザコードへの前後付加:
- 先頭に
load_user_definitions()を付け、user defから過去の定義をロード。 - 先頭に
load_user_variables()を付け、user varファイルから変数を読み、起動プロセスのシンボルテーブルに加える。 - 末尾に
save_user_variables()を付け、実行後に Python のglobals()でシンボルテーブルを取得→変数・オブジェクトをパースしてuser varに保存・同期する。 - この永続化処理が、扱うデータサイズに応じた実行時オーバーヘッドを生む(後述)。
- 先頭に
- 新プロセスでの計測実行:準備済みコードを Score-P Python bindings 付きの新 Python プロセスで実行。トレース/プロファイルを生成しつつ、本来の結果はノートブックサーバへパイプして返す。生成物は Vampir・Cube 等で表示できる。
表1(user def の同期)の要点:t1 で def A(A1版)→ t2 で class B 追加 → t3 で def A(A2版)が前の def A を上書き。セルをまたいだ定義の整合をファイルで保つ仕組み。
ユーザから見た使い方(図3)
セル冒頭に %%execute_with_scorep マジックを置くだけで、そのセルが Score-P 計測付きで実行される。加えて %%scorep_python_binding_arguments(バインディング引数)・%%scorep_env(Score-P 環境変数)でオプション設定。マジックの無いセルは標準カーネルで実行(=Score-P なし)。計測の有無をセル単位で選べる。
図3: 利用者視点のノートブック例。1・2セル目で Score-P 環境変数とバインディング引数を設定、3セル目が %%execute_with_scorep 付きでユーザコードを計測実行、4セル目はマジック無し(標準カーネルで実行)。
評価
実験機: 2×Intel Xeon E5-2680 v3 / 64GB RAM / Nvidia Tesla K80 GPU 1基。
対象アプリ:文字レベル GPT(fairy-tales コーパス)
- NLP の代表として 文字レベル GPT(前の文字列から次の1文字を予測し、コーパスの作風を真似て文章生成)を学習する課題を選定。
- コーパス: 人気の英語昔話 87 編(ユニークトークン 2154 語、500 Kb)。
- モデル: デコーダのみ Transformer 8層、マスク付き self-attention、512次元の単一隠れ層、計8 attention heads、約2500万パラメータ。オリジナル GPT(12層・768次元・12ヘッド)より小規模。
- 大半のボイラープレートはスクリプトファイルに分離(それも本カーネルで実行されるので計測対象)、ノートブックにはコーパス読込・学習初期化・重み保存・テキスト生成のみ残す。セル概念により段階(データ読込/学習/テスト)ごとに実行・観測できる。
プロファイルの可視化:Cube(図4)
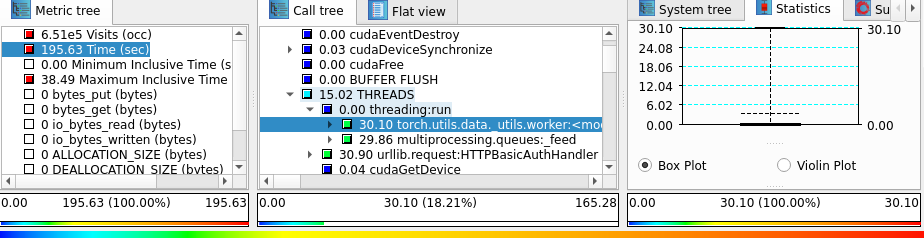
図4: Cube のプロファイル表示。左でメトリック(time)を選び、中央に各領域の累積時間を注記したコールツリー、右に選択領域の箱ひげ統計。色は青(小)→赤(大)。
Cube はプロファイルデータ表示ツール。3カラム構成:左=メトリック選択、中央=各領域に値を注記したコールツリー、右=変数ビュー(図種を選べる)。色スケールは青(小)→赤(大)。time を選ぶと各関数の累積時間が見える(子関数の時間は親から除外されるので、例えば threading:run 自体にはほとんど時間が乗らない)。右の箱ひげ図は選択コールパスの最小/最大/中央値/四分位を示す(領域内の分布の都合で四分位が中央値と重なる)。
トレースの可視化:Vampir(図5)

図5: Vampir のトレースタイムライン。複数スレッド/デバイスを行ごとに表示。CUDA=赤、PyTorch=黄、I/Oセレクタ=緑、スレッド待機=青、通信端点=灰。先頭にCUDA/PyTorchの初期化(約7.5秒)、以降CUDAとPyTorchが交互。
Vampir はトレース(イベントの時系列記録)表示ツールで、集約データでは見つからないボトルネック発見に使う。図5は CUDA+PyTorch の複数スレッドのタイムライン(左→右に時間進行)。色分け:CUDA=赤、PyTorch=黄、I/Oセレクタ=緑、スレッド待機=青、通信端点=灰。マスタスレッドの先頭に CUDA/PyTorch 初期化フェーズ(約7.5秒)、その後 CUDA と PyTorch の呼び出しが交互に続く。CUDA は CUDA[0:7]・CUDA[0:15] で利用、Orphan thread 1 は I/O 計算。Orphan thread=Score-P がスレッドの開始/終了を通知されなかったスレッド(Score-P Python bindings が Python 内部のスレッド起動を計装していないためと推測)。
オーバーヘッド計測(表2)
標準 IPython カーネルと本 Score-P カーネルで2セル(①昔話コーパスの読込、②学習のセットアップ)の実行時間を比較。実際のモデル fitting は時間がばらつき計測を歪めるため除外。
| データ読込 | 学習(セットアップ) | 合計 | |
|---|---|---|---|
| 標準 IPython | 0.01s | 1.43s | 1.44s |
| Score-P Python | 0.71s | 13.28s | 13.99s |
→ 合計が 1.44s → 13.99s、すなわち +12.55 秒。相対オーバーヘッドは大きいが、数時間かかる学習を回すなら無視できる水準。オーバーヘッドは主に永続化すべきデータサイズに依存し、データセット/アプリにより変動する。
まとめ・将来課題
- 性能分析を DS 開発の早い段階に、開発環境を変えずに組み込む手法を提示。カーネルがセル実行中に性能イベントを生成し Score-P に渡す。標準 IPython カーネルの置き換えなので導入が容易。実装は公開(GitHub)。
- 現状はセルごとに別トレースファイルに記録される。将来は 複数セルを1トレース/プロファイルにまとめる multi-cell tracing、Apache Spark のような他パラダイム向けの Java 対応、分散アプリ(Jupyter を大規模クラスタのインタフェースにする場合)への対応、ノートブック内へのトレース/プロファイル可視化の直接埋め込み、永続化の別手法によるオーバーヘッド削減を計画。
関連研究との関係(メモ)
- 本論文は 性能分析(SLR §5.2.4)の関係マップ で「①計測して人に見せる ― Score-P 文化圏」の起点に位置づけている。
- 同じ TU Dresden / Score-P 文化圏の後継が werner2024jumper(JUmPER)(SC24-W)。本論文の「とにかく計測を載せる」設計に対し、JUmPER は (a) 常時の粗粒度モニタリングと (b) 必要時のみの細粒度 Score-P 計装を切り替える二段構えへ洗練し、「探索的プログラミングの体験を壊さない」ことを重視する——本論文の約12.55秒のオーバーヘッドや「セル別トレース」という限界が、後継の改良動機と読める。
- Score-P の Python 対応そのものは本論文が依存する 「Advanced Python Performance Monitoring with Score-P」(Gocht et al., 参考文献[6]、同グループ Frenzel が共著) が担う。本論文はその Python bindings を Jupyter カーネルに統合した位置づけ(このノートにはまだ無いので本文中はプレーンテキストで言及)。
Q&A
(自分がAIに実際に質問したことだけを Q/A 形式で残す。まだなし。)
自分のコメント
(ここは自分で都度書く欄。)