AI解説
情報源:論文 PDF(4頁)を精読。著者:Yi Zhang, Zachary G. Ives(University of Pennsylvania)。デモ論文(VLDB 2019 demonstration track)であり、システムの設計・検索手法・デモの流れが中心で、定量評価の節は持たない。 本ノートは SLR(Siddik 2025) の §5.2.2 Computational Environments in Notebooks で挙げられた論文の1本。
一言で
Jupyter のバックエンド(ストレージ層)を「データレイク管理システム」に置き換え、ノートブック内で生まれる表(データフレーム)を自動でインデックス化し、ユーザが手元の表を“クエリ”として与えると、データレイク中の関連する表をランク付きで返すシステム。キーワード検索ではなく、既存の表とその来歴(provenance)を手がかりに関連表を探す点が新しい。狙いは、研究室など共同環境でのデータセット/データ生成物の再利用と来歴追跡を、ソフトウェア工学における共有ライブラリのように促進すること。
背景・問題(problem)
データサイエンスでは探索的データ分析(データを集めて結合・洗浄し、仮説を立てて検証、を繰り返す)が中心で、Jupyter 等のノートブックがその“IDE”になっている。再現性のために「ノートブックをversion管理・再現可能にする」研究は進んできた。しかし論文の問題意識は一歩先にある:
- ノートブックを「データファイルを読み書きするコード手順の文書」と見るのでなく、データレイク中のオブジェクト(表)に対して働く(共有・パラメータ化された)計算ステップの集合と見るべきだ。
- 標準のノートブックソフトは、セルがどんな副作用(状態・生成ファイル)を次セルや別ノートに渡すかを扱わず、セルのバージョン履歴・実行順も完全には保存しない。結果として、誰かが既に2つのデータセットを結合済み/特徴量を抽出済みでも、それを発見・再利用できない。
課題(task / やること)
Jupyter のバックエンドを置き換え、UIを拡張して、ノートブックを「データレイクへの計装・管理点」にする。具体的には、ノートブックが読み込む外部ファイル・計算途中の中間生成物・バージョン付きセル/ノート内容・検索用インデックスを取り込み、手元の表を例(query-by-example)として関連表を検索・推薦し、選んだ表(や生成ワークフロー)をノートに新セルとして挿入して再利用できるようにする。
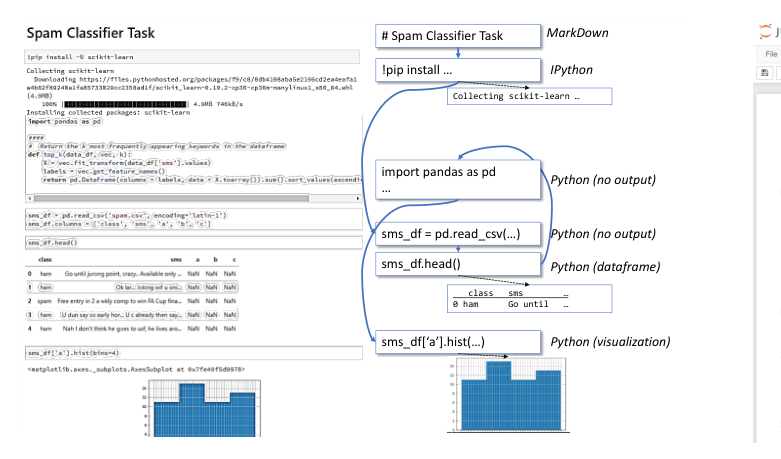
Figure 1:計算ノートブックの例と、それをデータモデルへ抽象化した表現(MarkDown/IPython/Python出力=データフレーム・可視化など、セル列を構造化して捉える)。
「関連表を探す」4つのユースケース
論文は関連表検索の動機を4例で示す:(1) 訓練データの拡張(同じセンサ/ツールで別セッションに取った表を足して訓練・検証集合を大きくする)、(2) オントロジー経由のリンク(生命科学等で accession number 等の識別子が別DB/オントロジーの項目を参照し、追加フィールドを持ち込める)、(3) 特徴量の拡張(他者が別のやり方で特徴量設計した表を推薦)、(4) データに対するワークフロー探索(ある表がどう読み込まれ・洗浄され・分析されたかの例を探す)。
システム構成
Juneau は Jupyter のバックエンドを置換し UI を拡張する。バックエンドの「データレイク管理」サブシステムは、関係ストアとKey-Valueストアを統合して次を捕捉・インデックスする:(1) ノートが読み込んだ外部ファイル、(2) セル(計算ステップ)が生む中間データ生成物、(3) バージョン付きのセル/ノート内容、(4) 表と来歴を高速取得するインデックス。
セル実行のたびに、Juneau はカーネルから新規/変更された表(データフレーム)を取得し、バックエンドにインポート&インデックスする。ユーザはノート内の任意の表を選んで検索エンジンに問い合わせ、データレイク中の関連表を得る。検索は共通スキーマや結合可能性だけでなく、来歴(provenance)ステップの類似も考慮しうる。
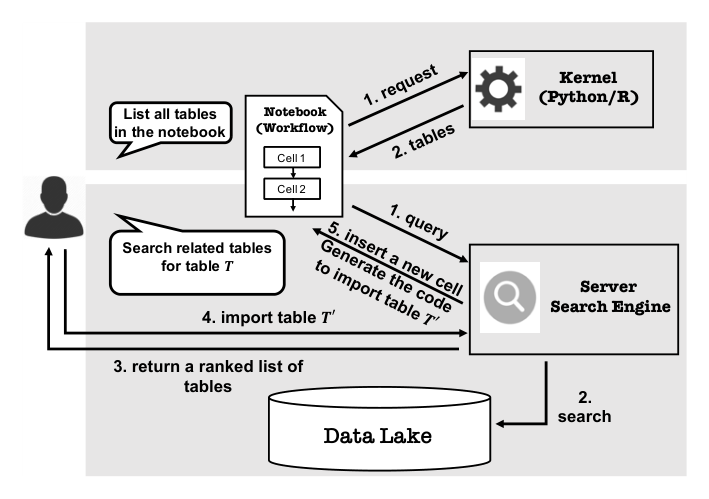
Figure 4:アーキテクチャ。ノートUI⇄カーネルでセルを実行 → Juneau が表をData Lakeへ取り込み・インデックス。ユーザが表 T で「関連表検索」すると、Server(Search Engine)が ①query→②search→③ランク付き表リスト返却→④表 T' をインポート→⑤ T' を読み込むコードを生成して新セル挿入、という流れ。
検索・インデックスの技術(本論文の主眼)
3クラスの表検索を狙う:追加の訓練/検証データ(同スキーマ・類似計算ステップだが行の重なりは小)、リンク可能な表(結合できる概念的に関連した基底表)、代替特徴量(基底データから派生し特徴抽出した他者の表。列の重なりは小が好ましい)。これらを1つのランキング関数で扱い、効率化のため top-k しきい値アルゴリズム(TA, Fagin ら)を拡張して、ランキング成分を適応的に優先する。ランキングは主に3成分:
- スキーマ・マッピング:クエリ表と対象表の列対応を、列インスタンスの類似で検出。Aurum 同様の sketch で高速化し、検出済みマッピングを再利用。
- キーに基づく行マッピング:候補スキーマ・マッピング上で、推定したキー/外部キー関係を使って行対行の対応(行類似度)を出す。
- 来歴(provenance)類似:表を生むワークフロー(ノート)を表間のデータフローグラフとして表し、内容・位置・依存で近似マッチング → グラフ間の編集距離で類似度を算出。行の重なりが小さくても意味的に近い表を拾える。
TAベースのアルゴリズムは「最も効率的な成分」から計算を始め、残りを推定することで、無関係な表に重い計算(来歴類似など)を費やすのを避ける。
デモの流れ
公開 Kaggle コンペ(住宅価格、整形外科患者の生体力学的特徴ほか)のノートブック群をクロールし、それらが生む中間表を全て Juneau のデータレイクに格納した上で、次の3ステップを実演する。
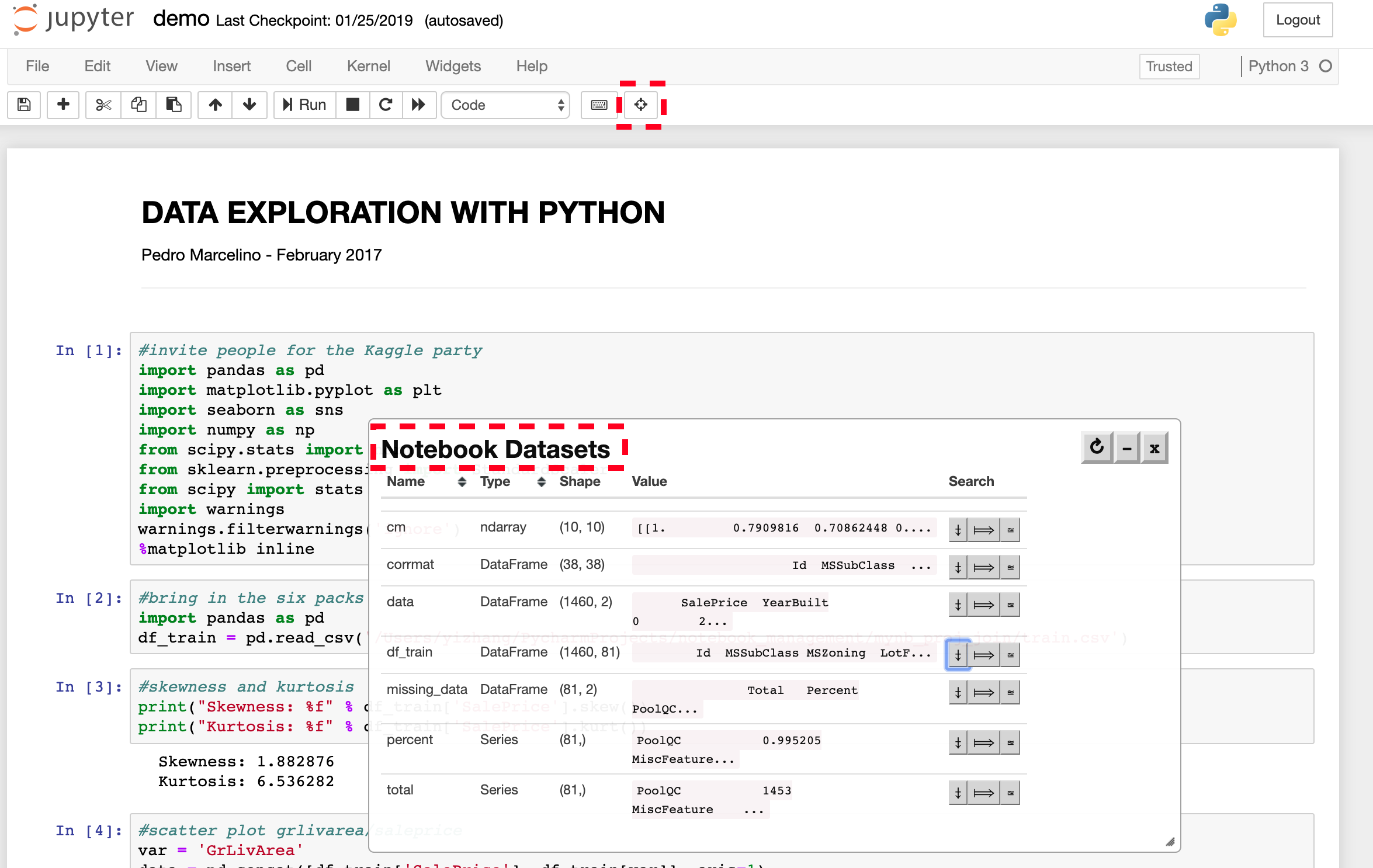
Figure 2(Demo Step 1):ツールバーの「Show Notebook Datasets」を押すと、現ノート内の全データセット(表・配列・データフレーム)の抜粋が一覧される。
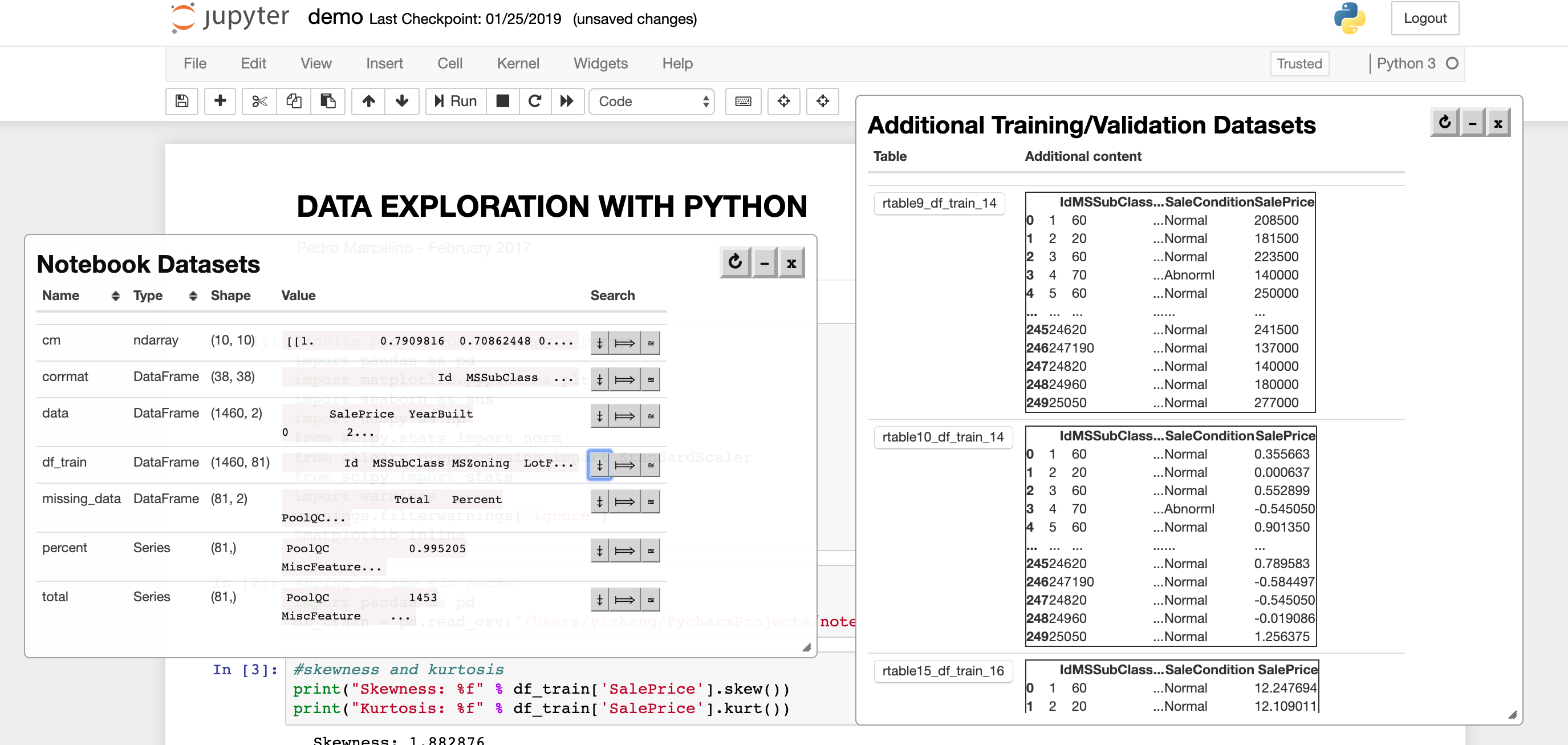
Figure 3(Demo Step 2):ある表と検索モード(例では “D”=訓練/検証データの拡張)を選ぶと、関連する表のランク付きリストが即座に返る。ランキングは利用パターン(多くのノートに取り込まれた表ほど上位、=表の人気度)も加味する。
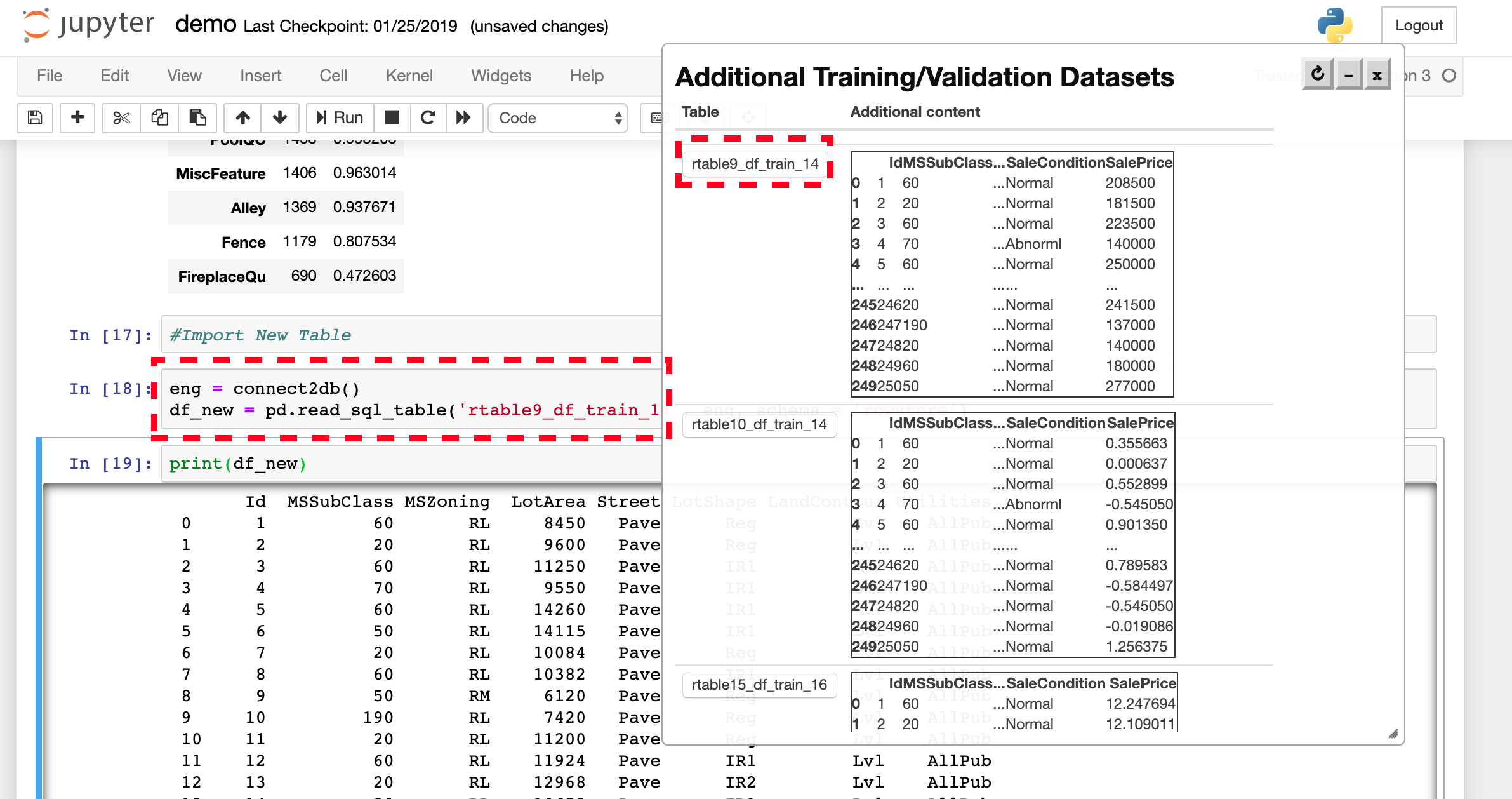
Figure 5(Demo Step 3):気に入った表をクリックすると、Juneau がその表を読み込む新セルをノートに追加する。ユーザは「表を実体(materialized)として取り込む」か「その表を生成したセル列(ワークフロー)ごと取り込む」かを選べる。
デモではさらに、得た表に対する典型操作(k-分割交差検証で分類器を訓練・評価、可視化、クラスタリング)を提示し、検索でどれだけの作業(行数・セル数)が省けたか、同様の作業をした Kaggle 競技者が何人いたかも見せる。
位置づけ・まとめ
論文の主張:(1) 重要なデータサイエンス課題(関連データの発見・再利用)をDB技術で解けること、(2) Juneau がデータレイク管理の視覚的・直感的ツールであること、(3) 内容ベース+来歴ベースの新しい検索・インデックスを提供すること。関連研究(データリンク発見、unionable/related table 探索 Aurum・Table Union Search 等)に対する新規性は、来歴情報・コード・より一般的な検索を、ノートブック環境の中から一体で扱う点にある。