AI解説
情報源:arXiv 全文(ar5iv HTML 版
arxiv.org/abs/2001.04592)を WebFetch で精読(手法・一貫性プロトコル・結果・図を確認)。 図は arXiv HTML 版の実画像(arch.png/causal-invalid.png)を取得して掲載。結果系の図(EPS)は本ノートに転載していない。
一言で
ステートレス前提の FaaS(AWS Lambda 等)に、低遅延の可変共有状態・関数間直接通信・効率的な関数合成を、オートスケール性を保ったまま持ち込む stateful FaaS プラットフォーム Cloudburst の提案。鍵は「論理的分離・物理的同居(LDPC)」=ストレージと計算を独立にスケールさせつつ、計算ノードに可変キャッシュを同居させて局所性を得る設計。状態は自動スケールKVS Anna に置き、ユーザの Python オブジェクトを格子(lattice)に透過的に包んで協調不要の競合解決を行う。さらに DAG を跨いだ分散セッション一貫性(Repeatable Read/Causal)プロトコルを与える。関数合成・局所性・通信で AWS Lambda/Step Functions 比 1〜3桁の性能改善。
背景・問題
現行 FaaS は「孤立した・ステートレスな関数」しかうまく扱えない。本研究が指す問題は 3 つ。
- 関数合成が遅い:Lambda は1呼び出しに最大20msのオーバーヘッドがあり、入れ子呼び出しで線形に積み上がる。5段の呼び出しで対話的サービスの許容遅延(~100ms)を食い潰す。Step Functions はさらに重い。
- 直接通信ができない:FaaS は inbound 接続を禁じるため、関数間通信を S3/DynamoDB 経由に強いる。ExCamera や numpywren は静的に確保した調停サーバ(単一マシンや Redis)に頼り、弾力性を犠牲にしている。
- 低遅延の可変共有状態がない:クラウドストレージ(S3)は一貫性が弱く遅く高い。例えば
f(x, g(x))は f と g が同じバージョンの x を読めず非決定的な結果になりうる。共有状態のために別途 Redis 等を立てると、結局スケール・耐障害の問題が戻ってくる。
→ 課題(やること):オートスケール性を保ちつつ、低遅延の可変共有状態・関数間通信・関数合成・一貫した状態管理を実現する stateful FaaS を設計・実装する。
設計原理:LDPC(Logical Disaggregation with Physical Colocation)
中核の洞察は「分離(ストレージと計算を独立に課金・スケール)と同居(”熱い”データを実行器の近くに物理配置)は両立できる」こと。これによりオートスケールの独立性を保ったまま、計算ノードの可変キャッシュで低遅延ローカルアクセスと wire-speed の関数間通信を得る。ただし、1つの DAG 合成が複数マシンに跨ると正しさが問題になる——これが 分散セッション一貫性 という新しい課題を生む。
提案手法:Cloudburst の構成
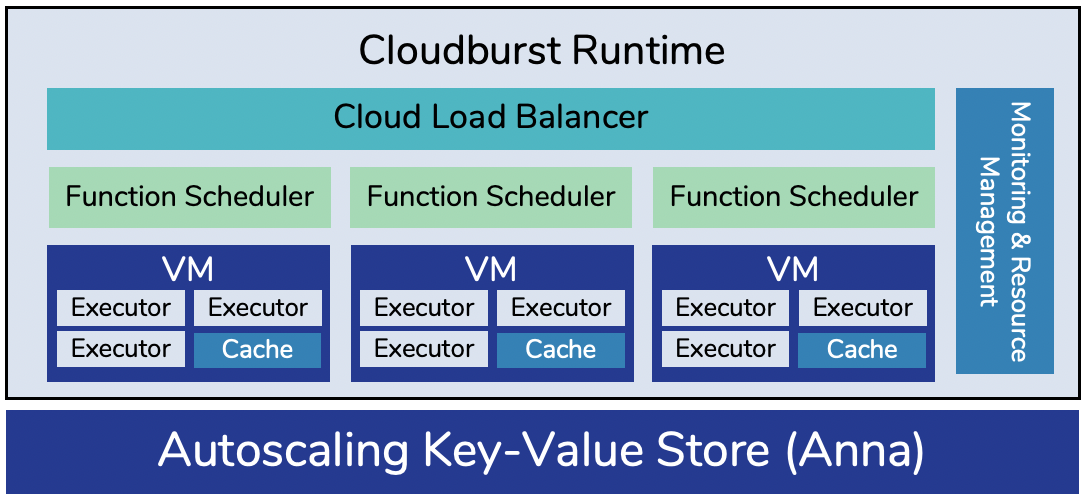
Figure 3:Function Executor(ローカルキャッシュ同居)、Scheduler、KVS(Anna)、Resource Management System の全体像。
- Function Executor:常駐の Python プロセス。関数を取得・デシリアライズし、引数中の KVS 参照を並列に解決、DAG では各呼び出し後に下流関数を起動。ローカル指標(キャッシュ済み関数・CPU・遅延)を KVS に publish する。
- ローカルキャッシュ:各実行VMに同居(Executor とは IPC でアクセス)。Executor とリモートの Anna KVS の間に入り、更新は即ローカルで ack→非同期で Anna にマージ送信、読みミスは非同期で Anna から取得。定期的にキャッシュ済みキーのスナップショットを Anna に publish し、Anna は「キー→キャッシュしているノード」の索引を保つ。
- Scheduler:関数登録と呼び出しを処理。クラウドLB(AWS ELB)でステートレスにロードバランス。登録関数(Anna に格納)・DAG トポロジ・呼び出し回数・キャッシュ索引(各 Scheduler ローカル)を管理し、Scheduler 間の協調は不要。
- Resource Management:KVS 集約の指標を監視。流入率≫完了率なら関数を複製(pinning)、CPU>70%でノード追加、CPU<20%でノード解放。クラスタスケールは Kubernetes が担う。
ストレージ:Anna KVS と格子(lattice)
状態は自動スケールKVS Anna に置く。値は格子——結合則・交換則・冪等を満たす merge 演算を備えた構造——で、協調なしの自動競合解決と複数一貫性レベルを可能にする。Cloudburst では Anna が永続状態ストアであると同時に、移動する関数インスタンス間のメッセージを中継する DHT 的オーバーレイにもなる。
プログラミングモデルと関数合成
ユーザは Python 関数を register し、引数は通常の Python オブジェクトか KVS 参照(実行時に透過的に解決)。結果は同期的にクライアントへ返すか、CloudburstFuture として KVS に格納する。関数合成は DAG(Spark/Dryad に類似)として登録でき、DAG が一貫性のスコープ(セッション)になる。システムAPI(Table 1)には get/put/delete、関数間直接メッセージング send/recv、get_id() があり、一意IDを既知のKVSキーに広告して IP:port に変換、TCP 直送(失敗時は Anna の inbox にフォールバック)する。
スケジューリングと耐障害性
スケジューラはキャッシュ索引を見て、KVS 参照を含む引数ならそのキーを最も多くキャッシュしているExecutorを選ぶ(局所性)。高負荷(>70%)ノードは避ける。耐障害性は、ストレージは Anna の複製で k-耐障害、計算はマシン障害時に DAG 全体をタイムアウト後に再実行(非冪等な副作用はプログラマ責任)。
一貫性:分散セッション一貫性
課題
直列化(合意による linearizability)はサーバレスの弾力的メンバシップと相容れない。そこで Anna の格子に基づく協調不要の一貫性を採る。だが Anna は「固定IPのクライアント単位」の一貫性しか持たない。f(x, g(x)) のような DAG が複数マシンに跨ると、各キャッシュが提供する一貫性を揃える必要がある。これが分散セッション一貫性。
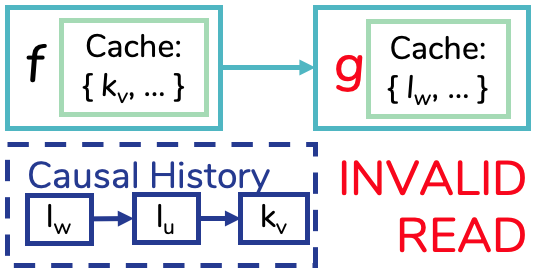
Figure 4:別マシン上の2つの関数が、互いの causal cut を知らずに因果不整合なデータを読む例。
格子のカプセル化
不透明な Python オブジェクトをランタイムが格子に透過的に包むので、ユーザコード無改変で Anna の競合解決が働く。
- Last-Writer-Wins (LWW) 格子:協調不要のグローバルタイムスタンプ(ローカル時計+ノードID)+値。merge はタイムスタンプが大きい方を残す。結果整合を与え、Repeatable Read 用のタイムスタンプにもなる。
- Causal 格子:ベクタ時計(
⟨id, clock⟩の集合。id=実行スレッドID、clock=単調増加の論理時計)+依存集合(このキーが依存するキー群)+値。merge はベクタ時計が dominate する版を残す(全要素で≥かつ少なくとも1つで>)。並行なら各要素のペアワイズ最大・依存集合の和・値の和をとる。
一貫性保証
- Repeatable Read(RR):線形 DAG で、ある関数がキー
kを読むとき、DAG 内の直近更新(あれば)か、なければ DAG 内で最初に読まれた版k_vを見る。protocol(Algorithm 1)は、初回読みでキャッシュが版タイムスタンプ付きスナップショットを作り、下流関数呼び出し時に上流キャッシュのアドレスと版タイムスタンプを伝播、下流が正しい版を持たなければ上流キャッシュに問い合わせる。DAG 完了時に sink が上流へスナップショット破棄を通知。 - Causal Consistency:関数
fが読む版k_vは、fとその祖先が読んだ版の依存集合Dに対しk_v ↛ k_i ∈ D(D 中のどの版に対しても古くない=並行か新しい)を満たす。各キャッシュは因果カット(causal cut)を保ち、Executor が read set の依存(キーとベクタ時計の対)を下流へ送り、上流キャッシュが版スナップショットを保持して跨ノードの因果を担保する。
評価
us-east-1a で、Scheduler を c5.large、Executor を c5.2xlarge(Python 3コア+キャッシュ1コア)で評価。
- 関数合成(
square(increment(x))):Cloudburst は AWS Lambda 比 約5×高速、2関数合成でも単関数と遅延がほぼ変わらず、Step Functions より約82×高速。「商用サーバレスを1〜3桁上回り、サーバ型 Python(Dask)並みの遅延」。 - データ局所性(10配列の和、1KB〜80MB):8MBで Cloudburst(Hot) は Cold 比 約10×、Lambda+Redis 比 約25×、Lambda+S3 比 約79×高速。
- 低遅延通信(gossip 集約):Cloudburst gossip は Lambda+DynamoDB gather 比 約3×、サーバ型 Redis gather 比でも99パーセンタイルで40%速い。Cloudburst gather は Redis 比22×・DynamoDB 比53×。
- オートスケール:初期 3,300 req/s → 飽和検知でEC2増設(~2.5分)→ 4.4K → 6.7K req/s。負荷が止むと 20秒でスレッドを 360→2、5分でEC2を 120→60 に縮小。
- 一貫性のコスト(Fig.8, Table 2):中央値遅延は各モードでほぼ均一。99パーセンタイルは LWW 比で DSRR 1.8×、分散セッション因果(DSC)は最悪9×(5関数DAGで版スナップショット取得に最大4往復)。4,000 DAG 実行で SK 904件・MK +35件・DSC +104件・DSRR 46件の異常を検出・防止できた(LWW は定義上0件=何も守らない)。
- ケーススタディ:MobileNet 推論パイプラインは native Python(~210ms)に対し Cloudburst 225ms(+15ms)で、SageMaker・Lambda を上回る。Redis 製 Twitter クローン Retwis は44行の変更で移植でき、Redis ベースラインに対し穏当なオーバーヘッドでスムーズにスケール。
関連研究との関係(本リポジトリ内)
Cloudburst は「状態を外部 KVS に逃がしつつ、実行器近くのキャッシュで低遅延化する」設計で、本リポジトリでは Wukong(同じくサーバレス並列だが DAG スケジューリングが主眼)と対をなす——Wukong はスケジューリングの分散、Cloudburst は状態共有と一貫性にフォーカスする。状態保存・移行の系譜(ElasticNotebook・Kishu など)とは層が異なるが、「実行と状態を分離して扱う」という発想で接続する。
将来課題:DAG 間の隔離(トランザクション分離相当)と非冪等関数の耐障害性、より賢いオートスケール(warm pool 等)、ストリーミング、コンテナ隔離を超えたセキュリティ。