AI解説
著者版PDF: https://asgaard.ece.ualberta.ca/papers/Conference/SCAM_2023_Siddik_Do_Code_Quality_and_Style_Issues_Differ_Across_(Non-)Machine_Learning_Notebooks_Yes.pdf(再現用コード・データ: https://github.com/saeedsiddik/NotebookCodeStyleIssue) 情報源: 上記PDF全文(12ページ、本文・式・図1〜3・表I〜V)を
pdftotextで抽出して精読・検証済み。図は同PDFをページ画像にレンダリングして該当領域を切り出して掲載(図1=p4上、図2=p5左、図3=p7上)。数値はすべて本文・表から転記。
一言で
「ノートブックのコードは品質が低い」と言われてきたが、その低品質はノートブックという書き方そのものが原因なのか、それとも機械学習(ML)コードを書いているせいなのかを切り分けた大規模実証研究。Kaggle の 246,599 本の Python ノートブックを Pylint(静的解析)にかけ、ML / 非ML に分けてコード品質スコアとコードスタイル問題(PEP-8 違反)を比較する。結論:ML ノートブックの方がコード品質が低く、スタイル問題の分布も統計的に有意に異なる。とくにパッケージ/import 関連の問題が ML で顕著。コードを実行せず lint だけで測る純粋な静的分析であり、実行時間・メモリ等のランタイム資源は一切測っていない点に注意。
背景・問題
- ノートブックは対話的実行と出力可視化で人気だが、先行研究で「コード品質が低い」ことが繰り返し報告されてきた(Wang ら: ノートブックは Python スクリプトより PEP-8 適合度が低い/van Oort ら: ML プロジェクトはスタイル問題が多い)。
- だがノートブックの多くは ML コードを含むため、低品質の原因が「ノートブックという書き方」なのか「ML 機能を使っていること」なのかが切り分けられていなかった。
- 問題(problem)= この交絡(ノートブック性 vs ML性)が未分離で、低品質の真因が不明なこと。これが分かれば、ノートブック品質改善の研究努力をどちらに向ければよいかを絞り込める。
課題(この研究がやること)
問題そのものを解くのではなく、ML ノートブックと非ML ノートブックを大規模に静的解析で比較し、コード品質スコアとスタイル問題が両者で違うかを実証的に明らかにすることが本研究の課題(task)。具体的には次の2つの RQ に答える。
- RQ1: コード品質スコア(rating)は ML と非ML でどう違うか?
- RQ2: コードスタイル問題は ML と非ML でどう違うか?
用語と測り方(PEP-8 / Pylint)
- PEP-8: Python のコードスタイルガイド。これに照らした違反を「コードスタイル問題」と呼ぶ。
- Pylint: PEP-8 違反を静的に(コードを実行せずに)検出するツール。問題を6カテゴリ(Convention, Error, Fatal, Information, Refactor, Warning)に分類する。本研究は Pylint の品質スコア算出に使われる4カテゴリ(Error / Convention / Warning / Refactor)に絞る。
- Error (E): プログラムが誤動作しうる深刻な問題(構文エラー、未定義変数、未サポート演算子など)。
- Convention (C): PEP-8 の命名・空白・行長などの規約違反。バグになりにくい。
- Warning (W): 誤動作はしないが潜在的問題(非推奨関数、例外無視、return 後の else など)。
- Refactor (R): 読みやすさ・保守性の問題(docstring 無し、関数が大きすぎ、変数名が非記述的など)。
- Fatal は除外: Pylint は Fatal(構文エラー等)に当たると解析を中断するため、結果を偏らせないよう Fatal を含むノート(ML 28本・非ML 2本)は分析から除外。
-
コード品質スコア(rating, 0〜10): 4カテゴリの問題数を重み付けして算出。本文の式(LaTeX 禁止のため記号で表記):
Rating = max(0, 10 - ((5*E + R + W + C) / SLOC) * 10)ここで
SLOCは解析対象の実コード行数。Error は他カテゴリの 5 倍重い(バグになりうるため)。例: SLOC=50 で E=2, R=0, W=10, C=5 ならmax(0, 10 - (10+0+10+5)/50*10) = 5。
手法(やったこと)

図1: 方法論の全体像。Kaggle データセットを「ML ライブラリを使うか?」で ML / 非ML に二分し(上段)、各ノートを nbQA 経由で Pylint にかけて品質スコア算出(RQ1)とスタイル問題抽出(RQ2)を行う(下段)。
- データ: Quaranta ら(KGTorrent)の Kaggle 公開データセット。246,599 本の Python ノートブック(2015年11月〜2020年10月公開)。
- ラベリング: 文献から得た ML ライブラリ一覧を、各ノートの
import/from文と照合。1つでも ML ライブラリを使えば ML、そうでなければ非ML。結果は ML 177,252 本(71.9%)/非ML 69,347 本(28.1%)。なお import の有無で判定するだけで、その ML 機能が実際に呼ばれたかは確認しない(妥当性脅威の一つ)。 - 規模差: ML ノートは典型的に大きい(中央値 SLOC 75 vs 非ML 43)。Mann–Whitney U 検定で SLOC 分布は有意差(p<0.05, Cliff’s d=0.41=中程度)。
- 解析: Pylint 2.14.0 を nbQA(標準 Python lint をノートに適用するツール)経由で実行。出力から (ファイル名・品質スコア・スタイル問題) を抽出し SQLite に格納。検出問題は総計 2,773,937 件(ML 由来 77.9% = 2,159,994 件/非ML 由来 22.1% = 613,943 件)。
- 統計:
- 品質スコア・SLOC の分布差 → Mann–Whitney U 検定(連続・非正規・独立)+ Cliff’s delta(効果量: negligible<0.147≤small<0.330≤medium<0.474≤large)。
- スタイル問題の分布差 → Pearson のカイ二乗検定(行=問題種別、列=ML/非MLでの出現数の分割表)+ Cramér’s V(効果量: weak<0.2≤moderate<0.6≤strong)。多重比較のため Bonferroni 補正(有意水準 0.05/4)。
- どの問題が差を生むか → カイ二乗の標準化残差(Pearson 残差)で事後分析。残差が >3 または <-3 を「高い」とみなす(表では >1 / <-1 を抜粋)。
RQ1 の結果:品質スコアの差
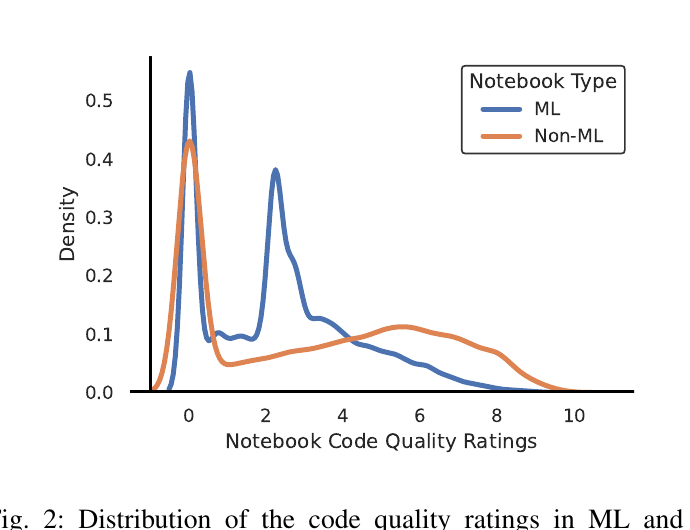
図2: ML(青)と非ML(橙)のコード品質スコア分布(密度)。両者とも 0 付近にピーク(Pylint の下限が 0)。ML には 2.3 付近に第2のピークがあり、これは「ML ノートはほぼ必ず Error を 1 件以上持つ」ことが Error の重み 5 倍で品質を急落させるためと著者は説明。
- 品質スコアは ML が低く、分布も有意に異なる(効果量は small)。中央値は ML 2.2 / 非ML 3.3。
- Mann–Whitney U 検定で p=0.0、Cliff’s d=0.15(small)。
- 歪度: ML 0.603(右に歪む=低スコア寄り)/非ML 0.228(歪みなし)。
- 尖度: ML -1.367/非ML -0.214(どちらも負)。非ML の方が平らなピーク。
- 著者の推測: ML の隆盛でソフトウェア工学の素養が薄いユーザが流入し、コード規約を守れていない可能性。
RQ2 の結果:スタイル問題の差
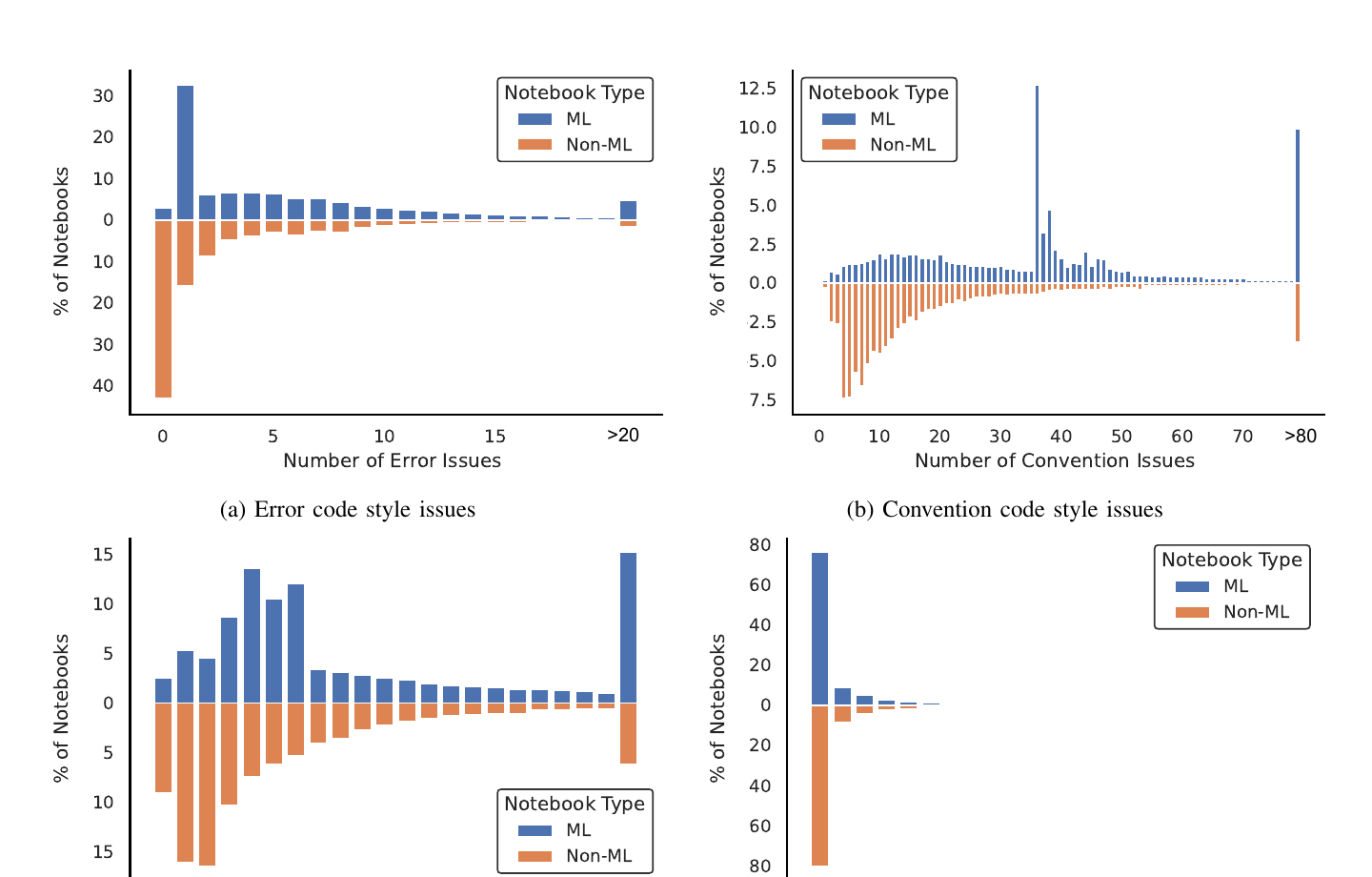
図3: カテゴリ別((a)Error / (b)Convention / (c)Warning / (d)Refactoring)の、1ノートあたり問題数の分布(上=ML、下=非ML の鏡像表示、縦軸=ノート割合%)。Error・Refactoring・Convention で ML 側が右方向に厚い分布になっているのが読み取れる。
結論: 4カテゴリすべてで分布が有意に異なる。Error・Warning・Refactoring は non-weak(≥moderate)な効果量。パッケージ/ライブラリ取り扱い関連の問題が ML で著しく多い。
(1) Error — ML で顕著(中程度の効果量 V=0.43)
- 1ノートあたり Error 数の中央値: ML 4 / 非ML 1。
- ML の 97.1% が Error を1件以上持つ(非ML は 56.9%)。理由は ML の 96.1% が E0401 import-error を1件以上持つから。
- top4 Error のうち3つがパッケージ取り扱い関連で、ML でほぼ2倍。
- E0401 import-error: 残差最大 5.28。ML 66.38% vs 非ML 35.10%(モジュールの import 失敗)。
- E1101 no-member: 残差 4.42。ML 8.61% vs 非ML 2.14(約4倍)。
- E0611 no-name-in-module: 残差 1.91。ML 4.86% vs 非ML 2.09。
- 逆に E0602 undefined-variable は非MLで多い(残差 -4.83、ML 13.43% vs 非ML 46.28%)。
- 背景: ML は専用ライブラリ依存が多く、環境非互換で import が失敗しやすい。1ノートの平均パッケージ数は ML 6.05±2.90 vs 非ML 3.44±2.28。
(2) Convention — 弱い効果量(V=0.16)
- 中央値: ML 36 / 非ML 11。38問題のうち標準残差 >1 / <-1 は4つ(>3 は無し=突出した1問題は無い)。
- C0103 invalid-name: 残差最大 1.52。ML 28.87% vs 非ML 21.77%。
- C0303 trailing-whitespace: 残差 -1.36(非ML寄り)。なお最大1ノートで 9,919 件という外れ値ノート(ハードコード値だらけで 9,900 件の trailing-whitespace)あり。
- C0413 wrong-import-position(パッケージ関連): 残差 1.29。ML 13.93% vs 非ML 9.87%。
- C0114 missing-module-docstring: 残差 -1.03。
(3) Warning — ML で顕著(中程度の効果量 V=0.26)
- 中央値: ML 6 / 非ML 3。残差 >3 が1つ、>1 / <-1 が7つ。
- W1406 redundant-u-string-prefix: 残差 3.64(ただし頻度は低く全Warningの2.39%)。
- W0611 unused-import(パッケージ関連、最頻 Warning=全体の24.10%): 残差 2.21。ML 25.73% vs 非ML 16.70%。ML はパッケージが多い分、未使用 import も多い。
- W0104 pointless-statement: 残差 -2.57(非ML寄り)。
(4) Refactoring — 中程度の効果量(V=0.34、全問題のうち1.48%と少数)
- 51種のうち残差 >1 / <-1 が10種。
- R1725 super-with-arguments: 残差 12.77 と全カテゴリ通じて飛び抜けて大きい。ML 5.70% vs 非ML 0.19%(約30倍)。PyTorch/TensorFlow など継承・多段サブクラス化が多い ML コードでは
super()に明示引数を渡す書き方が一般的で、これを Pylint が refactor 候補として警告するため(TensorFlow 公式も明示引数を使う例があり、著者は「ML には不適なルールの典型例」と位置づける)。 - R0402 consider-using-from-import(パッケージ関連): 残差 2.80。ML 10.01% vs 非ML 4.24%。
- R0902 too-many-instance-attributes: 残差 2.50。
- R1725 super-with-arguments: 残差 12.77 と全カテゴリ通じて飛び抜けて大きい。ML 5.70% vs 非ML 0.19%(約30倍)。PyTorch/TensorFlow など継承・多段サブクラス化が多い ML コードでは
含意
- PEP-8 開発者向け: 全カテゴリで ML/非ML が有意に違い、R1725・E0401・E1101 などが ML で多い。原因は「ML 開発者がスタイルを軽視」よりも「一部の PEP-8 ルールが ML コードに合っていない」可能性が高いと著者は主張。R1725 super-with-arguments はその好例で、ML 向けに発火条件を見直すべき。コードの種類ごとに異なる PEP-8 ガイドラインが要るかもしれない。
- 研究者向け: E0401 import-error のようなパッケージ関連問題は ML で多く、Pylint を大規模に回すとき実行環境を復元しないと ML コードでは偽陽性が増える。SnifferDog のような環境復元ツールの併用を推奨。
妥当性への脅威
- 内的: (a) 静的解析ゆえ実行環境を復元しておらず、差の大きい問題が依存関係系に偏った可能性(SnifferDog 等での再現を推奨)。(b) Pylint 依存(Pyflakes 等別ツールでの再検証を推奨)。(c) E0401 等は誤った環境設定による偽陽性との指摘もありうるが、デフォルト設定が「他人のノートを使う」最も代表的なケースなのでそのまま採用。(d) ML 判定は import 文照合のみで、実際に ML 機能が呼ばれたかは未確認。(e) Error の重み 5 倍は Pylint の設計判断をそのまま踏襲(将来研究との比較可能性のため)。
- 外的: Python ノートのみ(ただし計算ノートの 93% は Python)。Kaggle のノートのみ。GitHub 等他プラットフォームでの一般化は未検証。
結論
- ML ノートブックは PEP-8 基準で非ML よりコード品質が低い。
- 4カテゴリすべてのスタイル問題が ML で有意に多く発生。
- パッケージ/ライブラリ取り扱い関連の問題が ML で著しく多い。
- ML 機能の使用は低品質コードの重要な一因だが、同時に PEP-8 が ML コードに必ずしも適さないことも示唆。ML コードに合うようスタイルガイドを改良する研究を提言。
このノートの位置づけ(読み手メモ)
- 実行時資源は一切測らない静的分析。lint で検出できる静的なスタイル/品質問題(命名・import・docstring・継承の書き方など)の出現頻度を ML/非ML で比べただけで、セル実行時間・メモリ・CPU/GPU は対象外。ランタイム資源データセットの観点では「品質の静的側面」を扱う対岸の研究として参照する位置。
- 先行研究 [grotov2022comparison](ノートブック vs スクリプトの大規模比較、スタイル違反 約1.4倍)と問題意識が近いが、本研究は軸を ML vs 非ML に取り替えている点が新規(ノートブック性とML性の交絡を分離)。
Q&A
(まだなし)
自分のコメント
(まだなし)