AI解説
出版社版: https://doi.org/10.1145/3649838(Proc. ACM Program. Lang., Vol. 8, OOPSLA1, Article 121、全30ページ) 補足資料(データセット・解析結果): https://doi.org/10.5281/zenodo.7656049 情報源: 本文 PDF を全文精読。本文・全図(Fig.1〜10)・付録 A(探索木)・全テーブル(Table 1〜7)に基づく。図は PDF からレンダリングして掲載した。
一言で
計算ノートブックの「散らかる・再現できない」という悪評の正体を、著者は backtrack-involving dynamic patching(後戻りを伴う動的パッチ) だと突き止める。Kaggle の実リビジョン 1,307 件を解析し、これは悪習ではなく自然な需要であり、しかも手動でやると 1 割以上が安全でない(しかも沈黙エラーになりうる)ことを示す。そのうえで、過去の任意の状態へタイムトラベルして新しいコードで再開できるノートブックエンジン Multiverse Notebook を提案する。鍵は (1) セルを線形順序から解放し木構造+整合性規則で管理する実行モデル、(2) POSIX fork による cell-wise checkpointing、(3) ページ共有を最大化する aggressive tenuring(積極的テニュアリング)という専用 GC 戦略。Kaggle 由来の実探索 10 件で、一貫性を保証するための固有オーバヘッドは現実的に十分小さく、既存手法(素朴な再実行・dill 直列化)を大きく上回ることを示した。
背景・問題
計算ノートブック(Jupyter, Colab 等)はデータサイエンスの de facto 標準だが、ソフトウェア工学では悪名高い。Grus の有名な批判は2点——実行の隠れ状態(hidden states) と 悪いコーディング習慣の助長。ノートブックはセル列を上から下へ提示するが、セルはいつでも編集でき何度でも任意順で実行でき、その実行の積み重ねが現在状態を決める。結果、現在のコードから現在の状態が読めなくなり、振る舞いを推論できない。out-of-order 実行は再現性も損なう。
著者はこの諸問題の根を dynamic patching(動的パッチ=実行中のコードの一部を実行時に書き換えること)、とりわけ 概念的な後戻り(backtracking)を伴う動的パッチ に求める。Fig.1 がその典型で、「予測まで書いた後で、前処理(preprocessing)を後付けしたくなる」——過去のセルに戻って差し込む、という操作である。
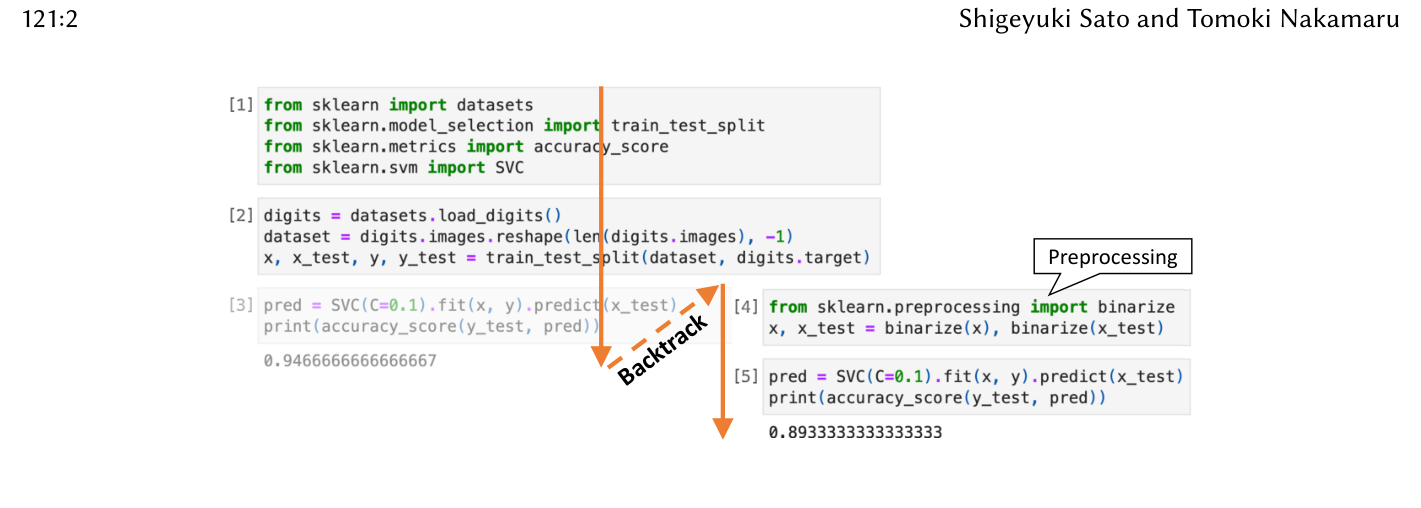
Figure 1. データサイエンスのプログラミングで起きる「後戻りを伴う動的パッチ」。予測(セル3)まで進めた後、後から前処理(セル4 binarize)を差し込みたくなり、過去(セル2の直後)へ Backtrack する。
ここで著者の主張は2つ。(1) ノートブックへの後戻り動的パッチはデータサイエンスにおける自然な需要である、(2) ゆえに安全性と効率の両方を提供する形で体系的に支援すべき。この 問題(解くべき困りごと)は「動的パッチをやめさせること」ではなく、「動的パッチは続けさせつつ、状態の一貫性を保つ手段が無いこと」だと位置づけ直すのがこの論文の出発点である。
§2 野生の後戻り(Kaggle リビジョン解析)
主張を裏づけるため、著者は Kaggle 上でデータサイエンティストが実際にどう改訂するかを定量解析する。これは後戻りに着目して実ノートブックの改訂を実証的に調べた初の研究であり、データセットも初提供だとする。
データセット構築
最も参加チーム数の多い 20 の research コンペから、票数上位 20 ノートブックの全バージョンを収集。次の条件を満たす版だけを valid とする:構文エラーなし/未処理例外で終わるセルなし/実行番号が 1 から全セルに連番で割り当て済み。これは「一時保存版」を除き、コード・実行ともに整合した版=探索の1試行の近似だけを残す狙い。隣接する2つの valid 版の対 (v1, v2) を revision(リビジョン) と呼ぶ。さらに比較容易化のため、コードセル以外を除去・コメント削除・black/isort で整形して正規化する。最終的に 132 ユーザの 204 ノートブック由来の 1,307 リビジョン。Fig.2 のとおり少数のノートブック/ユーザが多数のリビジョンを占めるが、外れ値として除かずバイアスを考慮して解析する。
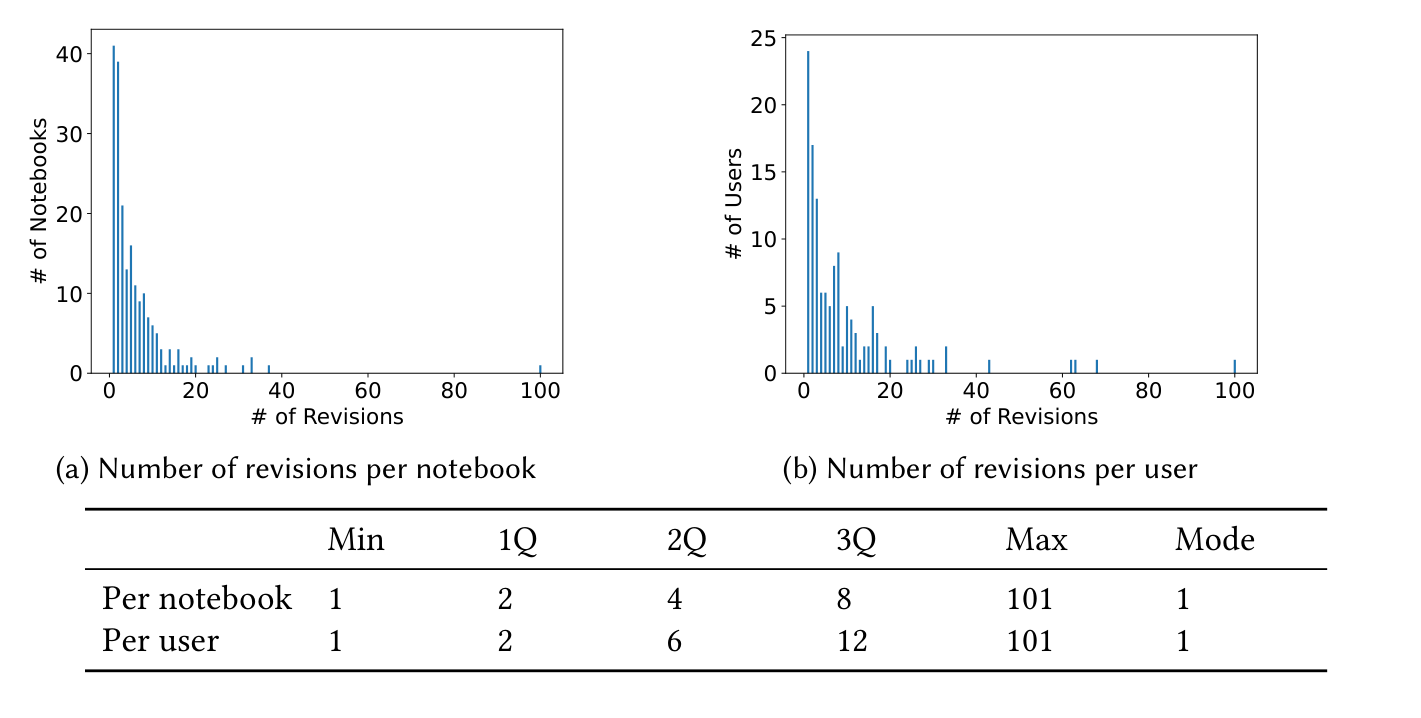
Figure 2. ノートブックあたり(左)とユーザあたり(右)のリビジョン数の分布。中央値はノートブックあたり4、ユーザあたり6だが、最大は101と裾が長い。
後戻りの指標
ノートブックをセル列とみなし(セルの等価は内容完全一致)、リビジョン (v1, v2) の 最長共通接頭辞 LCP を取る。計算的には v1 と v2 は LCP の直後から振る舞いが分かれる。v1 から LCP を除いた残りを backtrack part B、B の開始点を backtrack point と呼ぶ。backtrack length |B| は B のセル数、相対 backtrack length lB = |B| / |v1|。改訂の差分量は **対称差率 SDR = |
v1 △ v2 | / | v1 ∪ v2 | **(セルを集合とみなす)で測る。SDR は編集距離よりも「セルの上書き更新」に敏感。 |
結果1: 後戻りはノートブック全体に散らばる
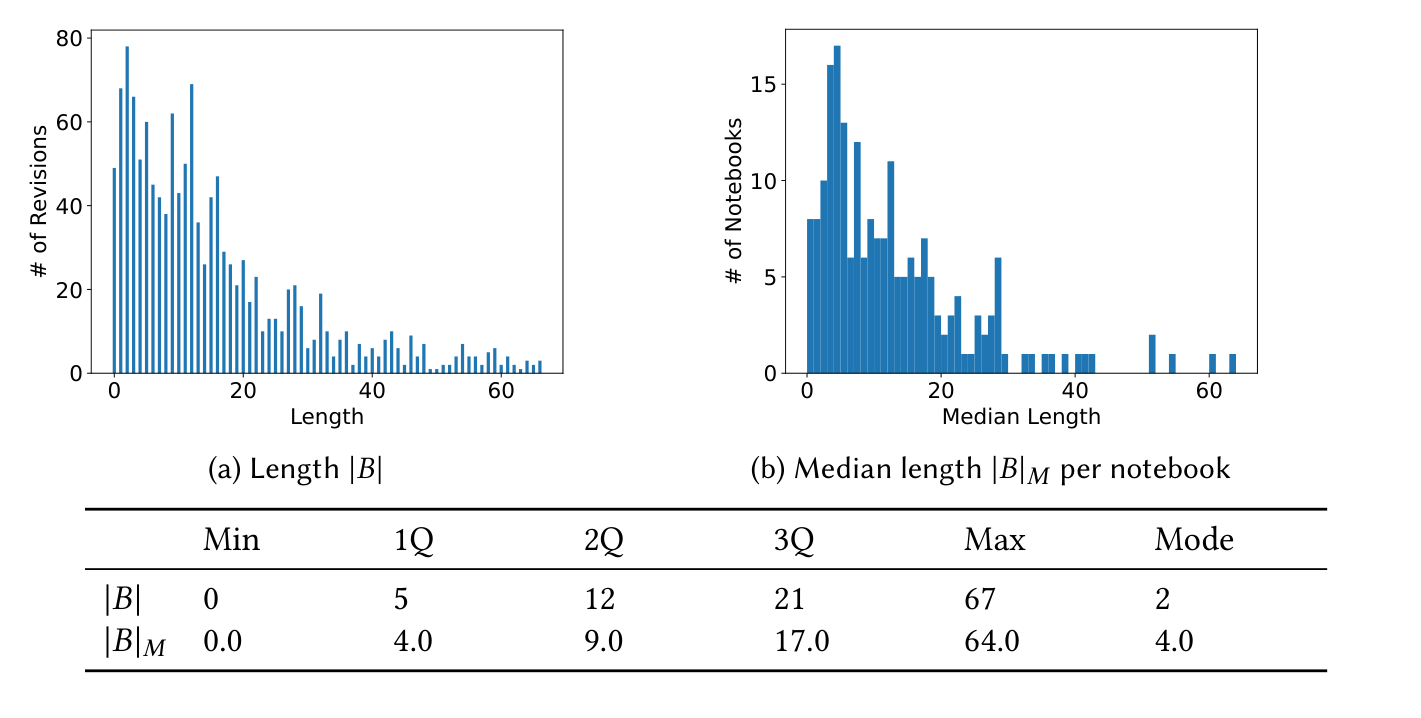
Figure 3. backtrack length |B| の分布(左)と、ノートブックごとの中央値 |B|_M の分布(右)。
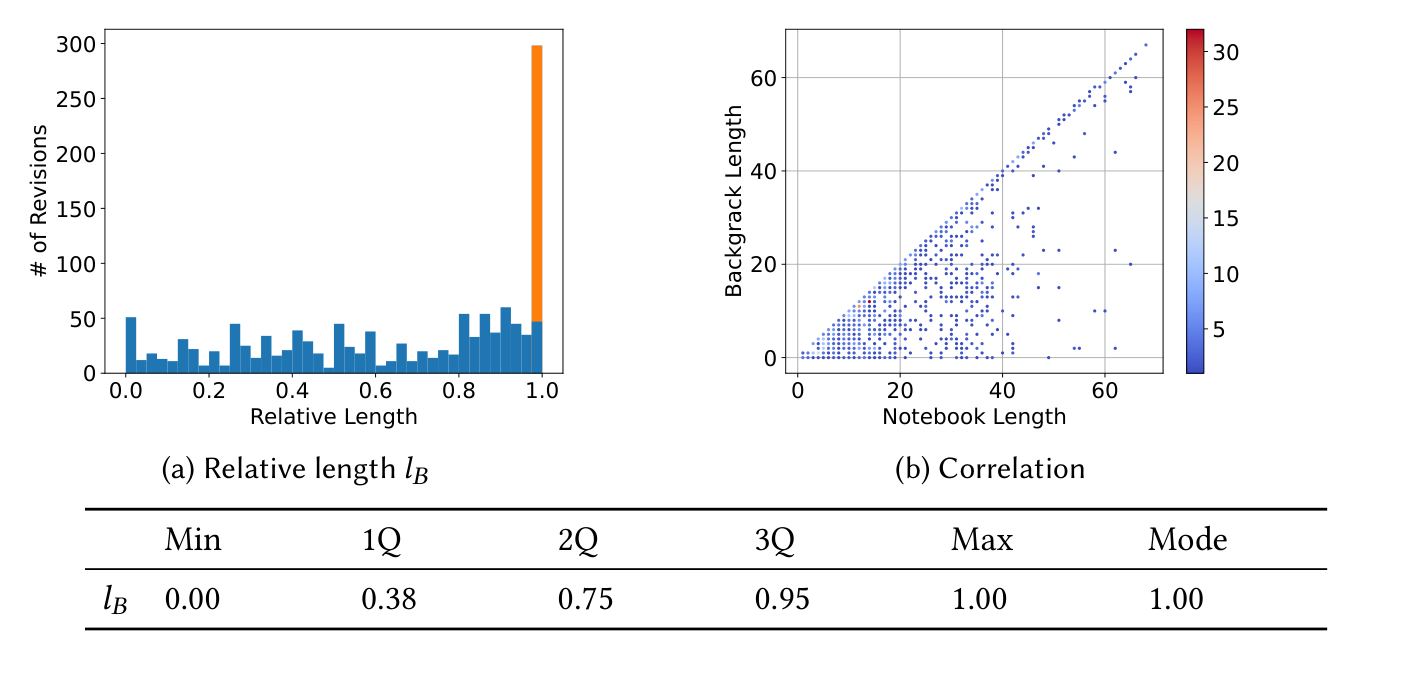
Figure 4. 相対後戻り長 lB の分布(左、オレンジは lB=1=先頭セル編集)と、|B| と |v1| の相関(右)。後戻り長はノートブック長とほぼ独立に散らばる。
1,258 リビジョン(96.3%)が |B| > 0、1,190(91.0%)が |B| > 1。|B| ≥ 12 が全リビジョンの半数を占めるなど、後戻り長は概して小さくない。lB を見ると先頭セルへ戻る(lB=1)ケースが目立つが、その 44.6% は import 文だけの変更であり外れ値として除くと、後戻り点はノートブック全体にほぼ一様ランダムに散らばる(Takeaway 1)。
結果2: たいてい 3/4 のセルは無傷 → LCP の再実行を避けたくなる
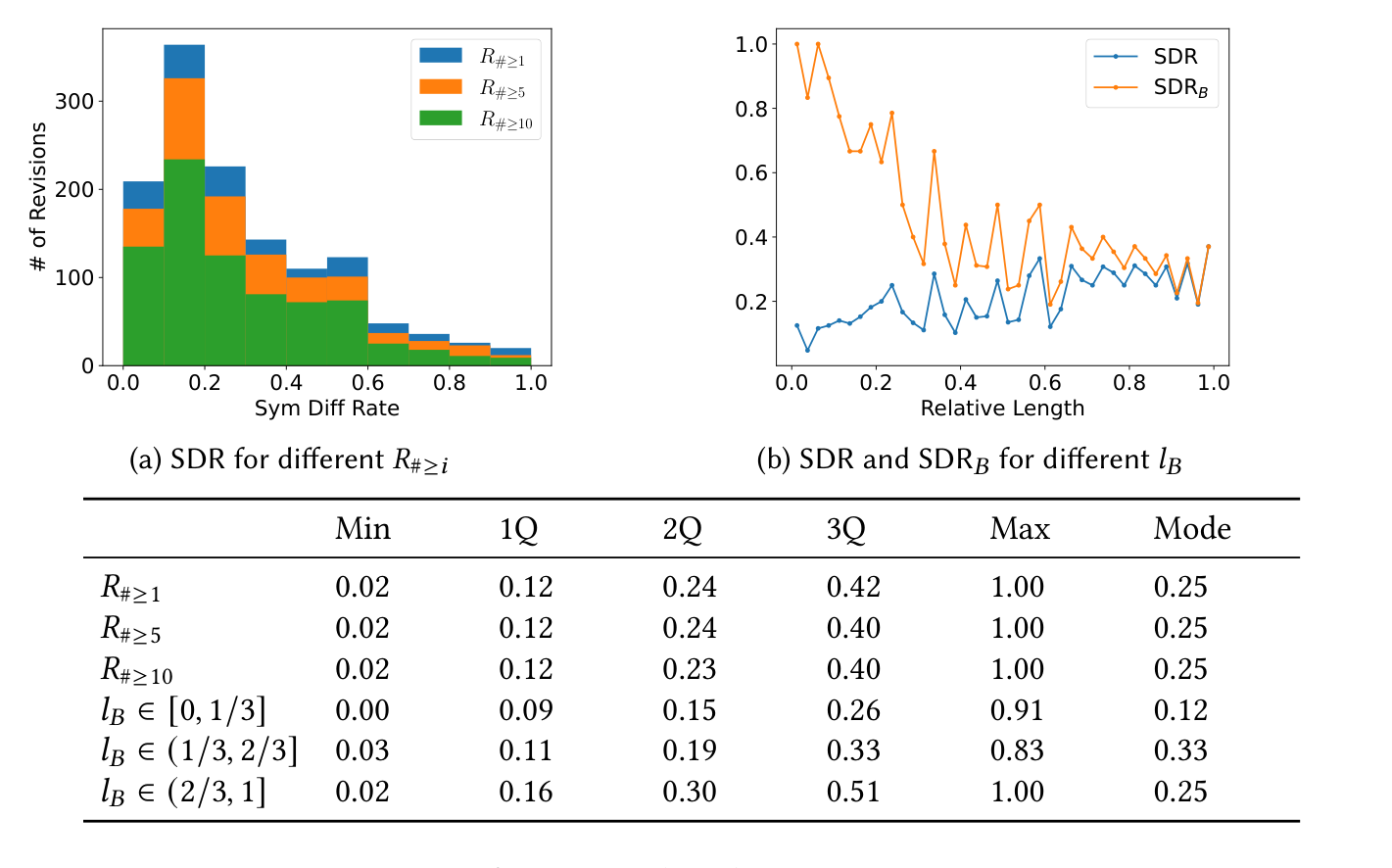
Figure 5. SDR の分布。左は履歴長別(R#≥i=少なくとも i リビジョンを持つノートブック群)、右は lB 別の SDR と「backtrack part に限った SDR_B」。SDR_B は lB≈0.5 まで急減し、その後ほぼ一定。
履歴長で分けても SDR 分布に大差はなく、典型的には約 3/4 のセルが無傷。後戻り点が下半分のときは backtrack part 内で更新が密に起きる。すなわち無傷の LCP を再実行するのは過度に冗長で、データサイエンティストは避けたくなる(Takeaway 2)。これが「LCP を再実行しない動的パッチ」への誘因になる。
結果3: 手動の動的パッチは1割超が安全でない(沈黙エラーも)
LCP-reusing dynamic patching を定義する:v1 実行後、インタプリタ状態をリセットせずに v2 の backtrack point 以降だけを実行する。これが「v2 を初期状態から全実行した結果と等価」なら、そのリビジョンは dynamic-patching-safe とする。全件の機械的判定は(実行に数時間かかる・乱数で結果が一致しない・データ/ライブラリが入手不能などで)困難なため、軽量な静的解析でふるい分け+手動検査を併用し、「明らかに unsafe」なものだけ(偽陽性ゼロ志向) をカウントした。
| 対象 | unsafe 件数 | 占有率 |
|---|---|---|
| Revision | 143 | 10.9% |
| Notebook | 53 | 26.0% |
| User | 37 | 28.0% |
Table 1. 明らかに unsafe なリビジョン/ノートブック/ユーザの数と割合。
少なくとも 10.9% のリビジョンが unsafe。しかもノートブック単位 26.0%・ユーザ単位 28.0% と、「一部の悪いノートブック/ユーザ」に偏っておらず広く起きている。明らかな場合だけ数えたので、実際はもっと多いはず。
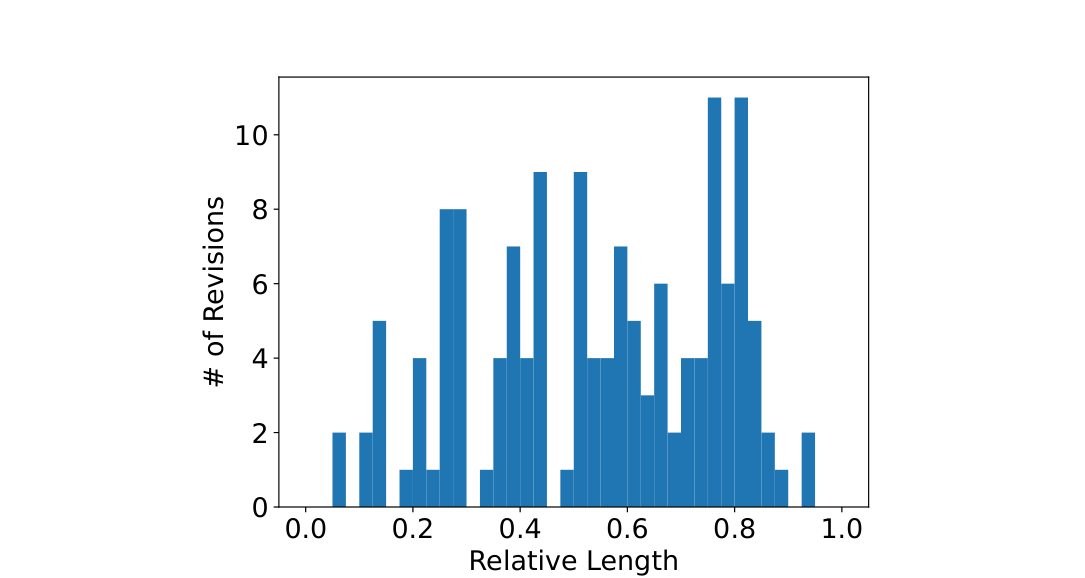
Figure 6. unsafe リビジョンの lB 分布。先頭・末尾付近の後戻りは安全になりやすく、中間(上下端から20%以上内側)への後戻りは unsafe 率が約22%=全体の約2倍。
unsafe の内訳(Fig.7):

Figure 7. unsafe リビジョンの代表例。ReSplit/ReTrain/NotRewound/VarDel など。
- ReUpdate(70件): LCP 再実行を省くと変数のデータが二重更新される(スケーリング、文字列化、行・列追加など)。
- ReSplit(12件): ファイルから読んだデータが二重に分割される(ReUpdate の一種だが量が多く別立て)。
- ReTrain(33件): 機械学習モデルが二重に学習される=エポック増・事前学習と等価になり、再起動後の再現が困難に。
- NotRewound(15件): backtrack part に破壊的更新があると、そのセルを消しても効果は巻き戻らず、LCP を再実行するか否かで結果が変わる。
- VarDel(13件): メモリ解放のための
delで、LCP 再実行を省くと参照できない変数が出る。
VarDel は NameError で即発覚するが、他は沈黙エラー(silent error)になりうる。誤ったデータ分析に気づかず重要な意思決定をしてしまう危険があり、目視だけの動的パッチは危険で非生産的(Takeaway 3・4)。著者自身、この手動検査が(自明に見える誤りでも)非常に骨が折れたと述べる。
結果4: ファイル I/O は後戻りで壊れない(実用上)
メモリ上の依存だけでなくファイル I/O 経由の依存も調べる。出力ファイルが後続セルで読まれる Read-of-Output、読まれない No-Read-of-Output、出力なし No-Output に分類(全件手動検査)。
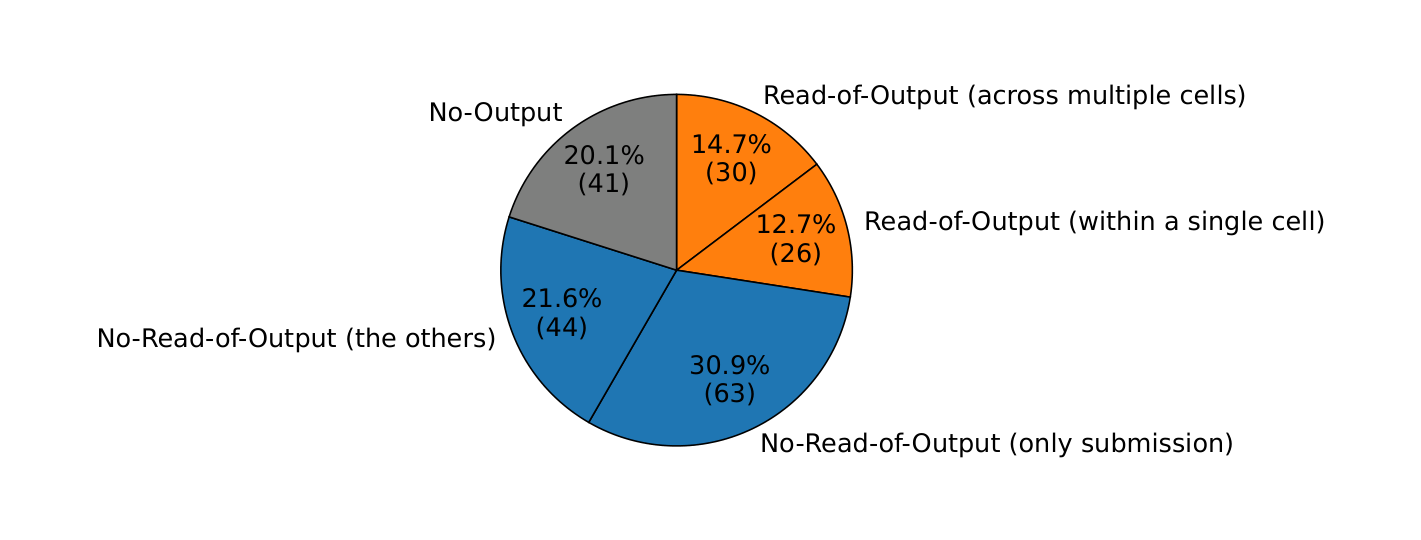
Figure 8. 204 ノートブックのファイル I/O 依存の内訳。Read-of-Output 27.5%、No-Read-of-Output 52.5%、No-Output 20.1%。No-Read-of-Output の過半は競技への submission ファイル。
後戻りで壊れうる依存は1件も見つからなかった(書き込みと読み出しの間に後戻り点が入らない)。ファイル出力の本質は「再利用成果物(ユーザ責任)」か「ログ(システムを通すべき)」に限られるという経験的仮説を支持する(Takeaway 5)。これが後述の「ファイル I/O はユーザ責任とする」設計判断の根拠になる。
§3 Multiverse Notebook の設計と実装
問題(動的パッチは自然な需要だが手動だと危険)に対し、課題=動的パッチを安全かつ効率的に体系支援するエンジンを設計・実装する。中心概念は time-traveling exploration(タイムトラベル探索):ユーザは過去の任意の実行状態へ飛び、そこから新しいセルで実行を再開できる。
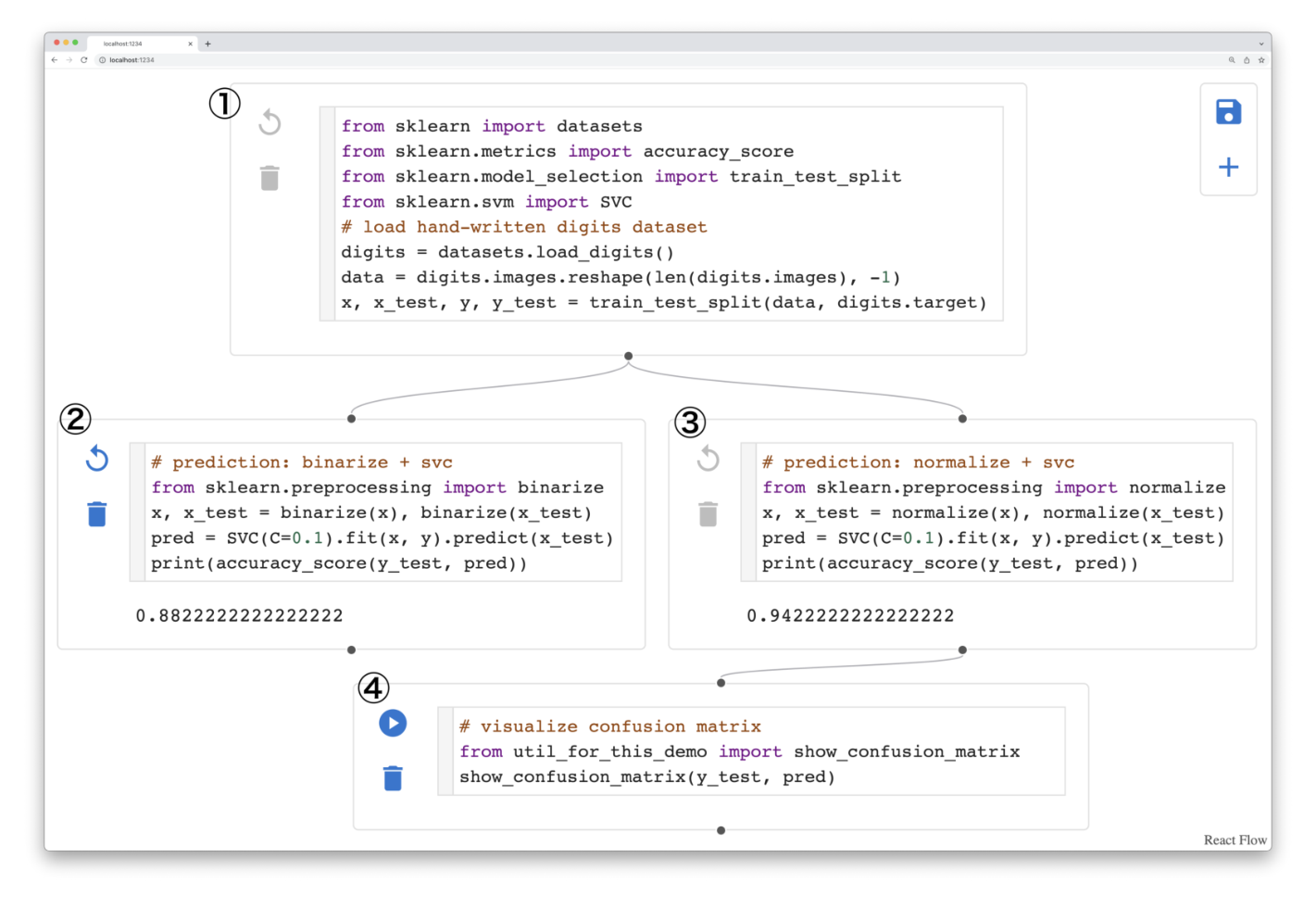
Figure 9. Multiverse Notebook の状態管理の可視化。実行済みセルの木として全状態を保持し、任意の既存セルの子として新しいセルを接ぎ木できる。①の直後へ戻って右の③を実行し、さらに④を実行した例。
設計原則
- Python エコシステムでの実用主義: 純粋関数型言語のほうがタイムトラベルには向くが、データサイエンティストは CPython 中心の巨大エコシステム(NumPy, scikit-learn など C 拡張)に住む。CPython は不可避の選択で、Multiverse Notebook はそこへの穏当な適応を目指す。
- cell-wise checkpointing(セル単位チェックポイント): 人間の観察はセル単位なので、セル単位のタイムトラベルで十分。長時間ループ内の無数のチェックポイントを気にせずに済み、単純かつ効率的。
- ファイル I/O との妥協: ファイルはチェックポイント対象に含めない。外部環境への副作用を完全に捉えるには OS レベルのサンドボックス等が要り高コスト。§2.4 の経験的知見(後戻りでファイル依存は壊れない)を根拠に、ファイル I/O はユーザ責任とし、タイムトラベルはメモリ上のデータだけを対象とする。
実行モデル: 木構造+整合性規則
既存環境は「状態とコードの整合に関係なくセルの線形順序を保つ」。Multiverse Notebook は逆に、セルを線形順序から解放して木構造で組織し、コードと状態の整合を保つ。整合性規則は4つ:
- すべての祖先セルが実行済みのときだけ、そのセルは実行可能になる。
- あるセルの状態を破棄すると、その子孫セルの状態もまとめて破棄される。
- セルの再実行は、そのセルの兄弟へのフォークとしてモデル化する。
- 新しくフォークされたセルは、祖先セルの状態だけを継承して走る。
規則1・2は親子の推移的関係で状態を整合に保ち、規則3・4はセル状態の更新時の整合を保つ。肝はタイムトラベルに対しても整合が崩れないこと——過去を更新しようとしても既存の未来はそのまま残り、過去を捨てればそこから既存の未来へは戻れない。

Figure 10. 実行モデルが生む固有オーバヘッド。(a) 既存環境では2番目と4番目のセルだけ再実行すれば済む。(b) Multiverse Notebook では3番目セルの既存状態は既存ブランチにしか無いため、新ブランチでそのコピーも実行する必要がある。整合性を効率より優先した結果の、設計由来の不可避なオーバヘッド。
POSIX fork によるチェックポイント
cell-wise checkpointing を POSIX fork で実装する。実行済みセルそれぞれにプロセスを割り当て、fork が作るプロセス木が、セル木の全状態を表す。あるセルを実行すると、その親セルの(実行済み)プロセスから新プロセスが fork してそのセルのコードを走る。プロセス木の根は CPython の初期状態。fork ベースが最適な理由:
- 状態隔離が POSIX 準拠 OS のプロセス隔離で自然に達成される。
- copy-on-write(CoW) により、チェックポイントの遅延もスナップショットの総空間も大幅に抑えられる。
- チェックポイントからの再開も、対応 CPython プロセスがそのまま走れるので即座。
要件は各セル末尾に fork の safe point を作れること:走っているスレッドが単一で、Multiverse Notebook 管理外の open file descriptor が無いこと。safe point の作成はユーザ責任とし(ライブラリごとに事情が違い、システム/CPython レベルでの自動化は事実上困難)、Multiverse Notebook は各セル末尾で条件をチェックし違反ならエラーを出す。セル内で走らせるコード自体は制限しない。
Aggressive Tenuring(積極的テニュアリング)
問題: ページ単位 CoW は CPython の GC と相性が悪い。CPython は参照カウントを主 GC とするため、参照が変わるとオブジェクトの居るページに書き込みが発生(カウント更新)し、さらに循環 GC がリスト・辞書を頻繁に走査してマークする。結果、Python レベルで何も変更していなくても多数のページが物理コピーされる。
解決: tenuring(世代間移動で GC から遠ざける)で緩和する。鍵となる観察は「あるセル末尾で生きているオブジェクトは、まだ存在しない将来の子孫セルからも参照されうる」こと。ここから極端だが理にかなった戦略を採る:
- 各セルに専用の GC 世代を割り当てる。
- 回収は「走っているセルの世代」のオブジェクトだけを対象にする。
こうすると tenuring は事実上 immortalizing(不滅化)になり、セル内寿命の一時オブジェクト以外は決して回収されない。ヒープはセル実行とともに単調に伸びるが、多数のオブジェクトが複数プロセス間で共有される本設定では総物理メモリを節約できる。これを aggressive tenuring と呼ぶ。ただしページが既存セルと完全共有されている限りはリークしないが、走るセルが既存ページへ書いてprivatize(私有化)するとリークしうる(私有化され到達不能オブジェクトだけを含むページは将来参照されないのに OS へ返らない)。
実装: CPython 3.10.5 へ約400行の C パッチ。3コンポーネントを改造——
- pymalloc:
fork後に新しい arena(1MB 領域)を要求させ、新セルは新鮮な arena で走る。さらに新 arena のアドレス範囲が既存 arena より必ず大きくなるよう保証。これで「オブジェクトが走行セル世代に属するか」をオブジェクトアドレスと親セル世代の末尾アドレスの比較だけで判定できる(数命令、ポインタ比較)。 - 参照カウント関数: 参照先が走行セル世代内にあるときだけ有効化(上記 pymalloc 改造のおかげで追加ガードは軽量)。
- 循環 GC: tenured オブジェクトを循環 GC 対象から外す。CPython 3.7+ の
gc.freeze(到達可能オブジェクトを循環 GC 対象から除外)を使い、fork(os.fork)時にgc.collect→gc.freezeを呼ぶ。
非移動(non-moving)GC と arena 単位テニュアリングのおかげでコピー無しで時間効率も良い。代償は各セル末尾の arena の未使用部分の空間ロスだが、評価で利得が上回ることを示す。
UI と限界
Multiverse Notebook は UI を木表示に限定しないコアエンジンであり、git の類推(branch=root-to-leaf のセル列、git-switch/git-cherry-pick/git-log --graph 的操作)が UI 設計に有望だとするが、UI 設計自体は将来課題。
限界:(1) ファイル I/O は何もしないので、古いセルから fork した新セルが、その後更新されたファイルを取り込んで不整合が起きうる(submission の上書きなど)。チェックポイントと協調するファイル I/O ライブラリの提供が解決策。(2) safe point 作成のユーザ責任は、サブシステム次第で難しい——例えば NVIDIA CUDA ランタイムは POSIX fork を非サポート(代替の Multi-Process Service はある)。プロプライエタリなライブラリにはユーザはほぼ手が出せず、Multiverse Notebook 上での使用回避しかない。
§4 評価
macOS マシン(Intel Core i9・128GB)上の Docker コンテナで実験。データセットから「動的パッチ unsafe・公開データ/ライブラリのみ使用」のノートブックを選び、Kaggle 記録の実行時間が長い順に10件採用(allunia, artgor, markpeng, namanj27, reighns, robikscube-ieee, robikscube-covid, umuto, vbmokin, xhlulu)。safe point のため一部はスレッド数を1に(OMP_NUM_THREADS=1)、GPU 利用行の除去などの軽微な改変を施す。各ノートブックのリビジョン群から後戻り点でフォークして exploration tree(探索木) を構成し、被験対象とする。

Figure A(付録A). 評価に使った10件の探索木。高さ・幅の形は多様で、allunia は高くて広く、vbmokin は高いが細い。artgor は約半数のセルが複製、xhlulu はほぼ固有。
固有オーバヘッド(§3.2.2 のコスト)
探索木を全実行した Multiverse Notebook と、素の CPython で最小限のセルだけ手動選択して実行した場合を比較(各値は15回測定の中央値)。
| Notebook | 最小実行 [s] | Multiverse [s] | 差 |
|---|---|---|---|
| allunia | 9.09 | 56.6 | +523% |
| artgor | 2.36 | 9.69 | +311% |
| markpeng | 1970 | 1960 | −1% |
| namanj27 | 212 | 190 | −10% |
| reighns | 54.2 | 88.5 | +64% |
| robikscube-ieee | 636 | 1050 | +65% |
| robikscube-covid | 204 | 221 | +8% |
| umuto | 9.85 | 9.80 | −0% |
| vbmokin | 234 | 278 | +19% |
| xhlulu | 232 | 224 | −4% |
Table 5. 固有オーバヘッド。Multiverse は概して遅いが、unsafe ゆえに最小実行側が共通セルの再実行を要する4件(markpeng, namanj27, umuto, xhlulu)では逆に速い。
重要なのは、この表は人的コストを含まないこと。最小実行のためのセル選択は、コードを読み「どのセルを走らせれば整合した出力が得られるか」を判断する作業で、著者の経験では root-to-leaf 1経路あたり最低1分かかった。表の規模のノートブックでこれを手動で行うのは「ひどく骨が折れる」。よって一貫性保証の固有オーバヘッドは現実的で十分に経済的と結論する。
POSIX fork チェックポイントの効率
探索木の総実行時間を3戦略で比較:No Checkpoint(素の CPython で全リビジョンの LCP を保守的に再実行=ベースライン)、Dill(dill でインタプリタセッションをセル単位に直列化。Weinman らの forkable notebook が採った方式)、Fork(提案)。dill には1時間の制限。
| Notebook | No Checkpoint [s] | Dill | Fork |
|---|---|---|---|
| allunia | 48.7 | 1170 (+2305%) | 56.6 (+16%) |
| artgor | 7.82 | 78.9 (+909%) | 9.69 (+24%) |
| markpeng | 2630 | 2120 (−20%) | 1960 (−26%) |
| namanj27 | 251 | Error | 190 (−24%) |
| reighns | 133 | 140 (+5%) | 88.5 (−33%) |
| robikscube-ieee | 1070 | >3600 (>+237%) | 1050 (−2%) |
| robikscube-covid | 229 | 1010 (+342%) | 221 (−4%) |
| umuto | 17.2 | 63.6 (+269%) | 9.80 (−43%) |
| vbmokin | 235 | 318 (+35%) | 278 (+18%) |
| xhlulu | 233 | 609 (+161%) | 224 (−4%) |
Table 6. 3戦略の総実行時間。Fork は No Checkpoint より概して大幅に短い(短縮は LCP 実行時間に依存)。Dill は全ケースで Fork に劣り、上部セルで読み込んだ大データを毎セル直列化するため特に遅い。namanj27 では dill が PyCapsule を直列化できず Error。
dill が遅い主因は、データサイエンス典型シナリオ(最初に大データをファイルからメモリへ読み、前処理・可視化で探索)で大データをほぼ毎セル繰り返し直列化してしまうこと。CoW が自然に行う差分スナップショットを dill は取らないので、RAM ディスクを使っても遅いままだろう。fork ベースは実世界のデータサイエンスで著しく効率的と結論。
Aggressive Tenuring の効果(時間・空間)
fork ベースの下で、No Tenuring(CPython 標準)/Lightweight Tenuring(gc.freeze だけ=循環 GC のみ無効化、素の CPython で実現可能な典型用法)/Aggressive Tenuring(循環 GC+参照カウントの両方を無効化、提案)を比較。空間は全プロセスの PSS(Proportional Set Size) で測る(共有領域はプロセス数で割る)。
Lightweight は名の通り軽量で時間・空間とも大きな悪影響なし(for ループ内で図を描く reighns 等で特に有効)。Aggressive は、わずかな時間オーバヘッド(概ね 1〜5%、参照カウント関数への追加ガード由来)と引き換えに空間で大きな利得:
- PSS 削減の幾何平均は No Tenuring 比 −22%(Lightweight は −5%)。時間は幾何平均 +2%。
- 削減率は二極化:allunia・robikscube-covid は 40% 超、namanj27・umuto は最大 2%。大削減群は文字列を含む pandas DataFrame の浅いコピーを頻繁に行う傾向。文字列は Python オブジェクトなので DataFrame をスライスすると全要素の参照カウントが +1 され、CoW が壊れる——ここを aggressive tenuring が止める。データサイエンスでは「読み込んだ DataFrame を覗いて特徴を掴む」が頻発するので、本戦略はよく効く。
- 例外的に allunia は時間でも得をした:絶対時間は約6秒と短いが 2.5GB のページフォルト(≒2秒分)が起きており、その劇的削減が時間オーバヘッドを上回った。
arena 戦略の空間オーバヘッドは利得に対し無視できる、と実験的に確認。
まとめ
3観点いずれでも Multiverse Notebook は、現実的か無視できる程度のオーバヘッドでユーザに大きな利得をもたらす。利得の量はケース依存で定量化は難しいが、データサイエンスの典型状況で実質的な利得がある。
関連研究との関係
論文自身の関連研究の整理(=本論文に書かれた内容)から、主要な差分を抜く:
- Fork It(Weinman ら, CHI 2021): 最も近い研究で、Jupyter を拡張してセルの流れを fork し状態隔離した代替案を作れる。決定的な違いは実行モデル——彼らは
dillで「どこでも fork 可能」にする一方、root-to-leaf 経路のセルは Jupyter 同様に状態を共有させる。結果、動的パッチに対するコード・状態整合は Jupyter 同様に脆い。著者は「彼らは木を UI モデルとして使い、本研究は木を計算モデルとして使った」と要約する(似て非なる)。→ ノート: Fork It(weinman2021forkit) - リアクティブ実行(Tempe, Observable, JetBrains Datalore): 編集ごとに影響コードを自動再実行して整合を保つが、現在の「宇宙」を即座に破壊的更新するので過去と未来の間をタイムトラベルできない。Datalore は CRIU(Linux のプロセスレベル checkpoint/restore)でリアクティブモードを実装するが、保存は毎回上書きで、クローンは初期状態から始まる(cell-wise checkpointing とは別物)。→ CRIU のノート: CRIU(
venkatesh2019criu) - Verdant: ノートブックの履歴(出力含む)を記録し過去版と比較できるが、設計上、動的パッチを安全にはしない。
- nbgather: 選んだ結果に依存するセルを集めてクリーンなノートブックを作る事後対策。Multiverse Notebook は不整合をそもそも防ぐ。両者は併用しうる。
- dynamic patching / checkpointing の系譜: 動的パッチは古典的にはソフトウェアの脆弱性・バグ修正のため(Hicks ら)。MVEDSUA は新旧版を同時に走らせ可用性を上げる手法で、本研究同様 POSIX
forkで版を実行時隔離する。checkpointing は time-traveling debugger(IGOR, dbd, Tardis)や in-memory DB(HyPer, Redis)で使われ、fork ベースは更新集約シナリオで最先端スナップショット法を上回るとの報告もある。worlds(副作用のスコープ制御の言語機構)はより豊かだが、C 拡張だらけの CPython では Python レベルで副作用を追えず実装困難——プロセスレベルのメモリ隔離が最も実現可能、というのが本研究の立場。 - メモリ管理: aggressive tenuring は pretenuring や NG2C(ユーザ指定世代)と「ユーザ情報に基づくテニュアリング」という点で近い。CPython の
gc.freezeや PEP 683 の immortal objects(固定参照カウント、PyPerformance で約3%減速=本論文のオーバヘッドと整合)とも関連。著者は、CPython がオブジェクト不滅化を入れても「フロンティアセルで作った生存オブジェクトを一括で効率的に不滅化できる」点で本技法は価値が残るとする。 - 実証研究: §2 は後戻りに着目した初のリビジョン実証研究。KGTorrent(Kaggle ノートブックの大規模ダンプ)等の既存データセットとは目的が異なる。→ ノート: KGTorrent(
quaranta2021kgtorrent)
最終節で著者は問いを投げる——ノートブック環境は何であるべきか。プログラミング環境(VS Code 的なエディタ)でも言語システムでもなく、その中間であるべきで、Multiverse Notebook はそこを目指す。設計・技法は言語非依存で R 等にも適用可能。fork ベース cell-wise checkpointing は一選択肢にすぎず銀の弾丸ではない(一時オブジェクトをセルを跨いで多数持ち越すと空間ペナルティが大きい、巨大オブジェクトは off-heap 専用処理が適切かも)とも釘を刺す。
Q&A
(自分がAIに実際に質問したことだけを Q/A 形式で残す。まだなし。)
自分のコメント
(ここは自分で都度書く欄。)
- 後続の Kishu(
li2025kishu、本論文では未引用)も「タイムトラベル」を狙うが、こちらはオブジェクト粒度の差分チェックポイントで、Multiverse の「プロセス木+fork」とはアプローチが対照的。状態管理の関心と接続したい。 - 自分の関心(セッション状態の移送・復元)から見ると、aggressive tenuring の「CoW を壊さないための GC 改造」は、状態をプロセス間/マシン間で共有・移送するときにも効く発想に見える。