AI解説
情報源: 本文・図表とも arXiv プレプリント版(GigaScience 採択版とほぼ同一内容)を全文精読。PDF https://arxiv.org/pdf/2308.07333(arxiv:2308.07333)。OUP の出版版 https://doi.org/10.1093/gigascience/giad113 は本文 HTML がボット保護で取得できず、数値の突き合わせには arXiv 版テキストと PDF を用いた。図はすべて arXiv 版 PDF をページごとにラスタライズして切り出した(OUP からの図ファイル直取得はできなかった)。本文中で「( )」内に併記されている小さい数字は 2021 年の初回実行時の対応値(再掲)で、本ノートの主数値は 2023 年再実行版を採用する。
一言で
PubMed Central に索引される生物医学論文が GitHub で公開している Jupyter ノートブックを、全自動で集めてそのまま再実行し、エラーなく走るか・出力が原著と一致するかを大規模に測った実証研究。結論は厳しく、再実行を試みた 15,817 本の Python ノートブックのうち、最後までエラーなく走ったのはわずか 1,203 本(7.6%)、原著と同じ結果を再現できたのは 879 本(5.6%)にとどまった。失敗の最大要因は依存関係(モジュール)まわりである。
この論文が測るのは「再実行できるか」「出力が一致するか」という再現性であって、実行時間・メモリ・CPU/GPU といったランタイム資源プロファイルは測っていない(資源として記録されているのはパイプライン全体の総実行時間と環境フットプリント推定だけ。後述)。
問題(problem)と課題(task)を分ける
- 問題(解くべき問題): 計算ノートブックを使う生物医学研究の計算再現性が、大規模には検証されていない。論文に「コードは GitHub にある」と書いてあっても、それが実際に再び動いて同じ結果を出すのかは誰も体系的に確かめていない。
- 課題(この研究がやること): PMC 論文に紐づく公開 Jupyter ノートブックを機械的に収集し、可能な限り原環境に近い conda 環境で再実行し、成否・出力一致・例外の種類を定量化する全自動パイプラインを作って回す。さらに失敗パターン(どの例外がどれだけ起きるか)を分析し、再現性を上げるための示唆を出す。
注意: この研究はノートブックを手で直して再現を試みることはしていない(手動修正は系統的にはやらない方針)。あくまで「公開された状態のまま自動で再実行したらどうなるか」を測っている。
パイプライン(収集 → 環境構築 → 再実行 → 差分)
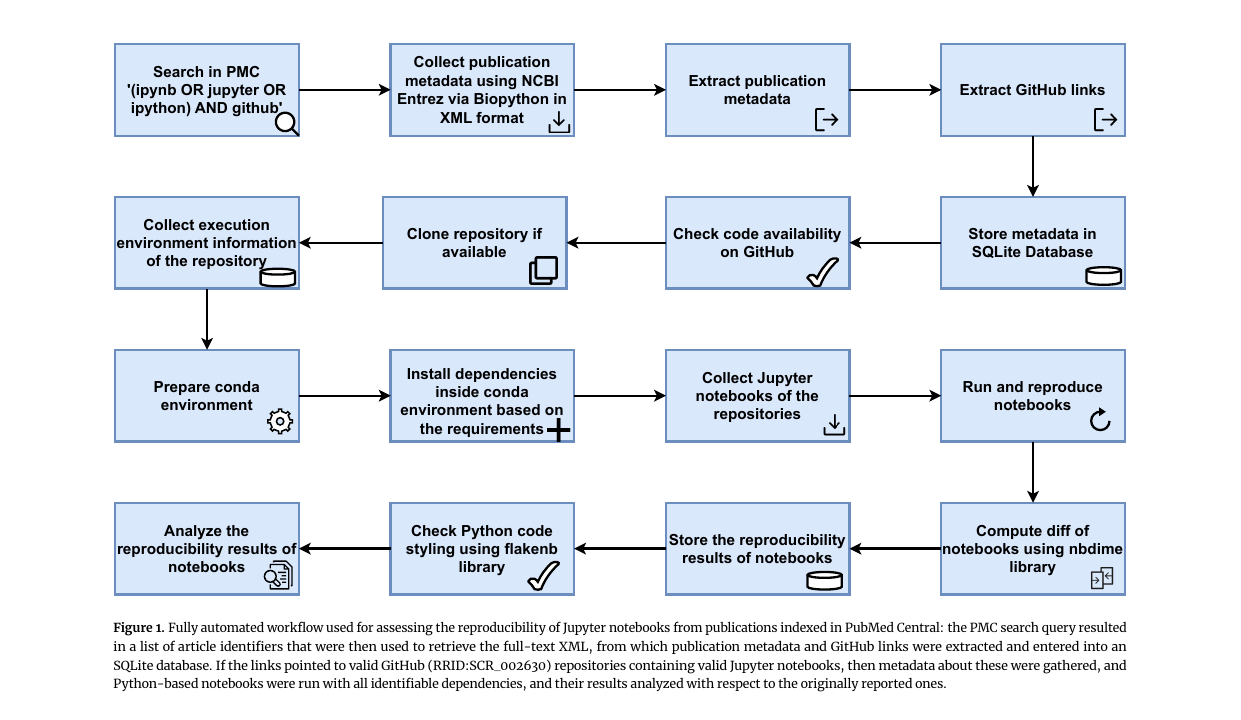
Figure 1: 全自動ワークフローの概念図。PMC を検索 → 全文 XML から論文メタデータと GitHub リンクを抽出 → SQLite に格納 → 有効な GitHub リポジトリをクローン → conda 環境を用意して依存をインストール → ノートブックを再実行 → nbdime で原著出力との差分を計算 → flake8nb でスタイルもチェック、という流れ。
具体的な手順は以下の通り。
- 収集: 2023年3月27日に PMC を
(ipynb OR jupyter OR ipython) AND githubで検索。全文 XML から GitHub リンクを抽出。 - リポジトリ検証: GitHub API で情報取得 → クローン → 有効な Jupyter ノートブックの有無を確認。
- 依存の検出:
requirements.txt/setup.py/pipfile(およびpipfile.lock)から依存情報を抽出。 - 環境構築: ノートブックに宣言された Python バージョンに基づいて conda 環境を用意し、上記ファイルの依存をその中にインストール。依存ファイルが無いリポジトリについては、anaconda の標準データサイエンスパッケージ群(scikit-learn, numpy, matplotlib, pandas など)を入れて実行を試みる。
- 再実行: ノートブックを再実行し、nbdime ライブラリで原著に記録された出力との差分を取る。コードは先行研究(Pimentel らの大規模研究、および可視化ツール ReproduceMeGit)のパイプラインを改変したもの。
- 解析: 例外の種類・頻度、再現成功率、ノートブック構造などを集計。
依存インストールが成功しても実行で失敗するものが多数ある点に注意(インストール成功 ≠ 実行成功)。
計算環境と総実行時間(ここが「資源」に触れる唯一の箇所)
- 初回実行(2021年): Friedrich Schiller University の Ara クラスタの Skylake 標準ノード(2× Intel Xeon Gold 6140 18コア 2.3GHz、合計 192GB RAM)。2021年2月24〜28日、総計 117時間52分。
- 再実行(2023年): 同構成だがメモリ割り当てを 128GB に変更。2023年3月27日〜5月9日の約43日間(クラスタの停電・ストレージ障害・タイムアウトしないノートブックの除外などの中断を含む)。
- 環境フットプリントは Green Algorithms v2.2 で推定(ソフト開発・図生成・テスト実行などは含めない概算)。
これらはパイプライン全体の壁時計時間であって、個々のノートブック/セルの実行時間・メモリ・CPU/GPU 使用量を計測したものではない。セル粒度のランタイム資源プロファイルはこの論文には無い。
データセットの規模(数を正確に)
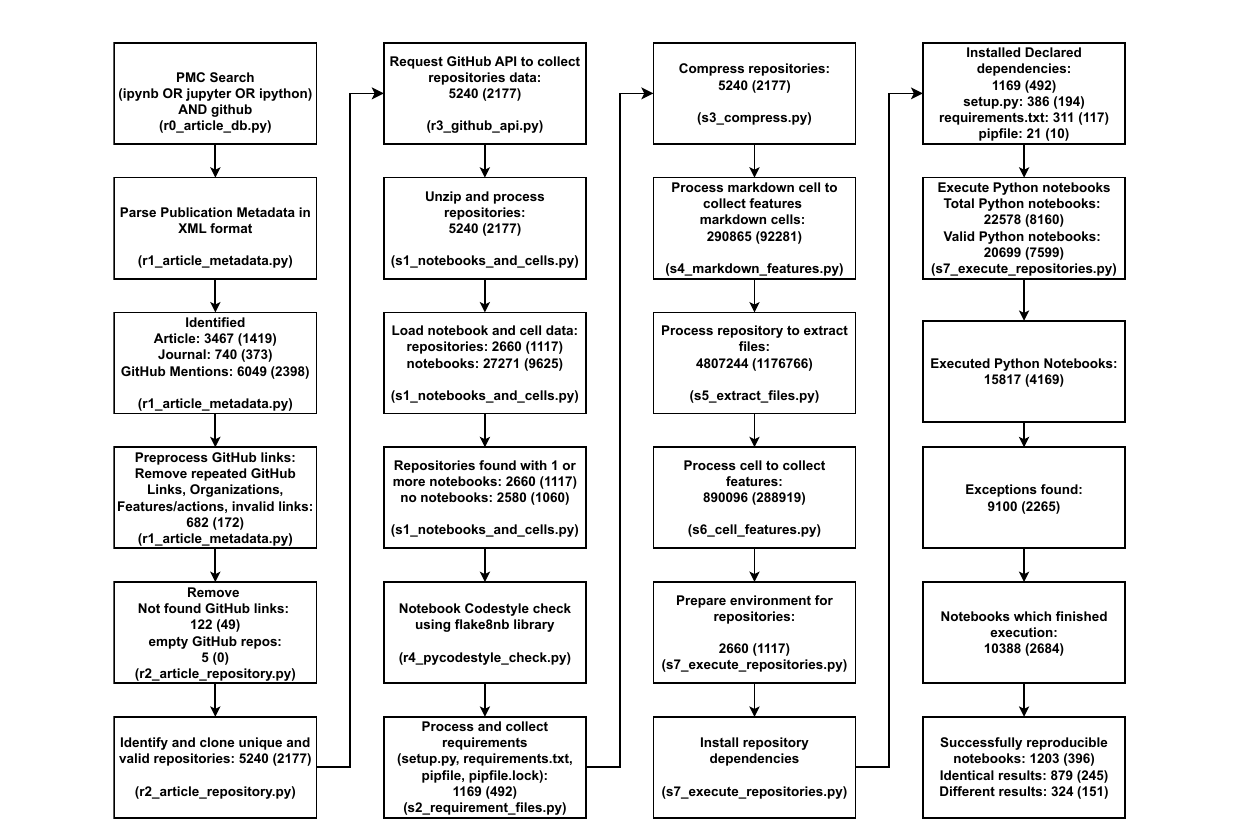
Figure 2: PRISMA フロー図に倣ったパイプライン各段の実数。各ボックスにステップの説明・通過したエンティティ数・対応スクリプト名が書かれている(括弧内は 2021年初回実行時の値の再掲)。左上の PMC 検索から右下の「再現成功ノートブック 1,203(うち一致 879・不一致 324)」まで、漏斗状に数が絞られていく様子が一目で分かる。
- 抽出した論文: 3,467 本(うち Journal 740、GitHub 言及 6,049 件)
- クローンした一意・有効な GitHub リポジトリ: 5,240。うちJupyter ノートブックを1本以上含むもの: 2,660(残り 2,580 はノートブック無し)。
- ダウンロードした Jupyter ノートブック総数: 27,271 本。
- 言語別: Python が 22,578 本(全体の約82.8%)で最多、次いで「Unknown(カーネル不明)」3,112、R 891、Julia 295、Matlab 134 など。
- 依存を宣言しているリポジトリ: 1,169(うち
setup.py386、requirements.txt311、両方 465、pipfileのみ 21)。ノートブック単位では 11,818 本(43.3%)が依存宣言ありのリポジトリに属する。 - 再実行を試みた Python ノートブック: 15,817 本(Python の…全体比で 58.15%) = 依存が宣言されていて自動再実行にかけられたもの。
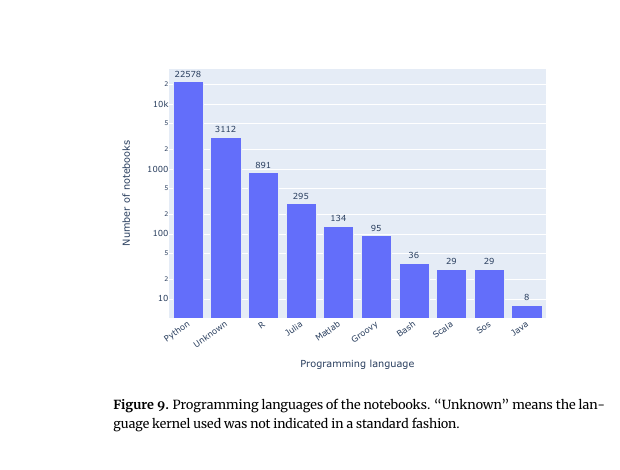
Figure 9: ノートブックのカーネル言語の分布(対数軸)。Python 22,578 が圧倒的で、Unknown 3,112、R 891、Julia 295、Matlab 134 と続く。「Unknown」はカーネル言語が標準的な形で記されていなかったもの。
中心的な結果: 再実行率・成功率・一致率
再実行を試みた 15,817 本を起点に絞り込むと次のようになる。
| 段階 | 本数 | 割合(15,817 基準) |
|---|---|---|
| 再実行を試みた Python ノートブック | 15,817 | 100% |
| 依存インストールに失敗 | 5,429 | 34.32% |
| 依存インストールに成功し実行へ | 10,388 | 65.68% |
| 実行したが例外で失敗 | 9,100 | 87.6%(10,388 基準) |
| エラーなく最後まで走った | 1,203 | 7.61% |
| └ 原著と同一の結果 | 879 | 5.56% |
| └ 原著と異なる結果 | 324 | 2.05% |
- 依存ファイルは構文崩れや競合があったわけではなく、インストール失敗の原因は不明だが、著者は高階の依存(宣言された依存のさらに依存)が原因と推測している。
- 「異なる結果」とは、再実行で得た出力が原著ノートブックに保存されている出力と nbdime 差分で一致しなかったもの。原著の出力が古い、データやライブラリのバージョン差、乱数シード、API 変更などで起こりうる。
- 補足:
different/(different+identical)の比は初回実行の 0.38 から再実行の 0.27 に下がった。つまり「最後まで走りさえすれば、出力が一致する確率は再実行のほうが高かった」。
失敗の内訳: 例外の種類と頻度
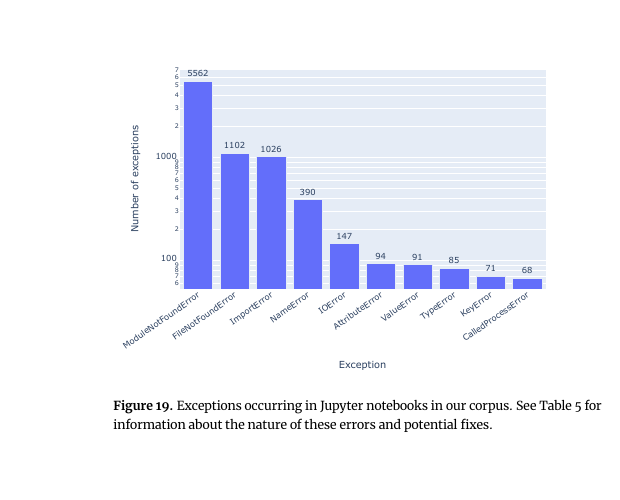
Figure 19: コーパス全体で発生した例外の種類別頻度(対数軸)。ModuleNotFoundError 5,562 が突出し、FileNotFoundError 1,102、ImportError 1,026、NameError 390、IOError 147、AttributeError 94、ValueError 91、TypeError 85、KeyError 71、CalledProcessError 68 と続く。
本文の数値(実行 10,388 本に対する割合):
- ModuleNotFoundError + ImportError 合算で 6,588 件(41.65%) — 最大の失敗要因。モジュールが見つからない/インポートできない。要は依存関係の問題。
- FileNotFoundError / IOError: 1,249 件(7.9%) — 絶対パスでデータを参照している、データファイルがリポジトリに含まれていない、など。
- NameError: 390 件(2.47%) — 宣言されていない変数を使っている(セルの実行順序依存など)。
- 全体として、走らせたノートブックの 86.29% が「10回より多く出現する例外」を返した(=ごく一般的な少数の例外種に集中している)。
- 図2 のとおり、実行に回した 10,388 本のうち 9,100 本(87.6%)が何らかの例外で落ちた。
失敗要因が依存 → ファイル/パス → 名前の順という構図は、再現性を上げるには「依存を正しくピン留めし、データを同梱し、セルを上から順に実行できる形にする」ことが効く、という示唆につながる。論文は付録の Table 5 に各例外の性質と直し方(例: ModuleNotFoundError はモジュールがリポジトリに含まれるか/環境に入っているか確認、FileNotFoundError はパスとファイル存在の確認、NameError は定義箇所のドキュメント確認・先行セルの実行)を整理している。
ノートブックの中身の特徴(再現性の文脈で)
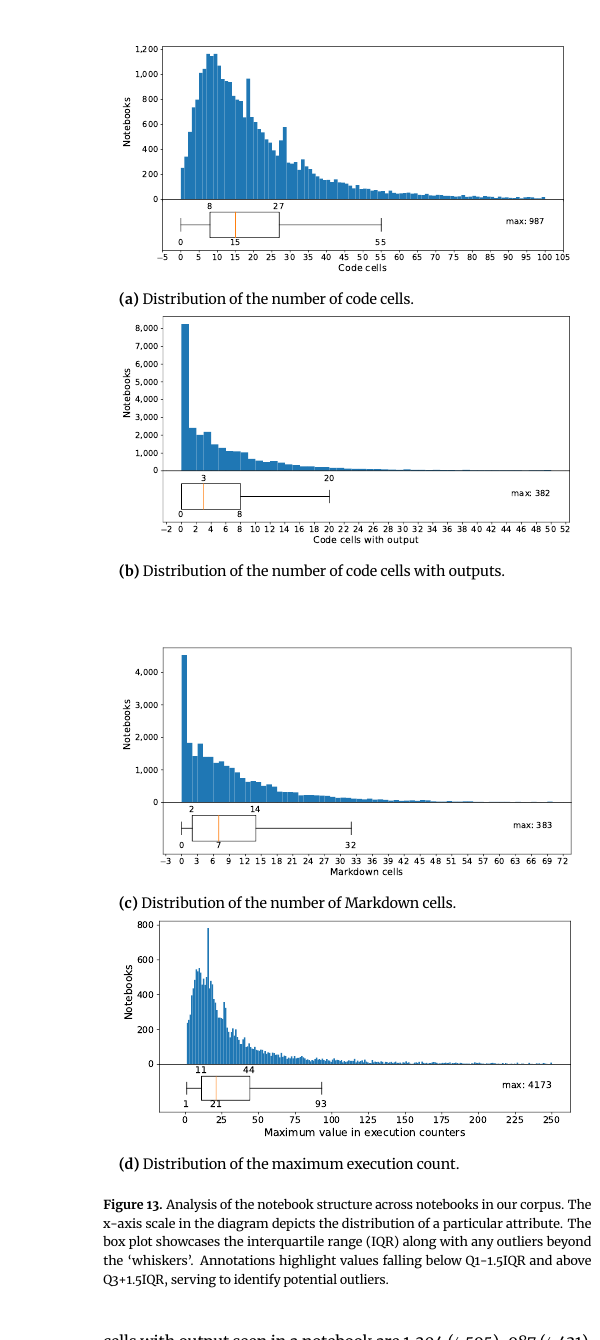
Figure 13: コーパス全体のノートブック構造の分布(4パネル)。各パネルはヒストグラム+箱ひげ図(IQR と外れ値)。(a) コードセル数(中央値15、Q3=27、最大987)、(b) 出力付きコードセル数(中央値3、最大382)、(c) Markdown セル数(中央値7、最大383)、(d) 最大実行番号(中央値21、最大4,173)。
- セル構成の中央値: 総セル 23、コードセル 15、出力付きセル 3、Markdown セル 7。最大実行番号の中央値は 21、最大は 4,173(=何度も書き換えながら回した痕跡)。
- 80.62%(18,178 本)に実行番号が付いている。実行番号は再実行順序の手掛かりになる(NameError の遠因として「順序依存」が示唆される)。
- Markdown を持つノートブックは 83.58%、うち 96.35% が英語。
- Python ノートブックの 96.85% が import を含み、96.35% が外部モジュールを使う。
切り口別の再現性
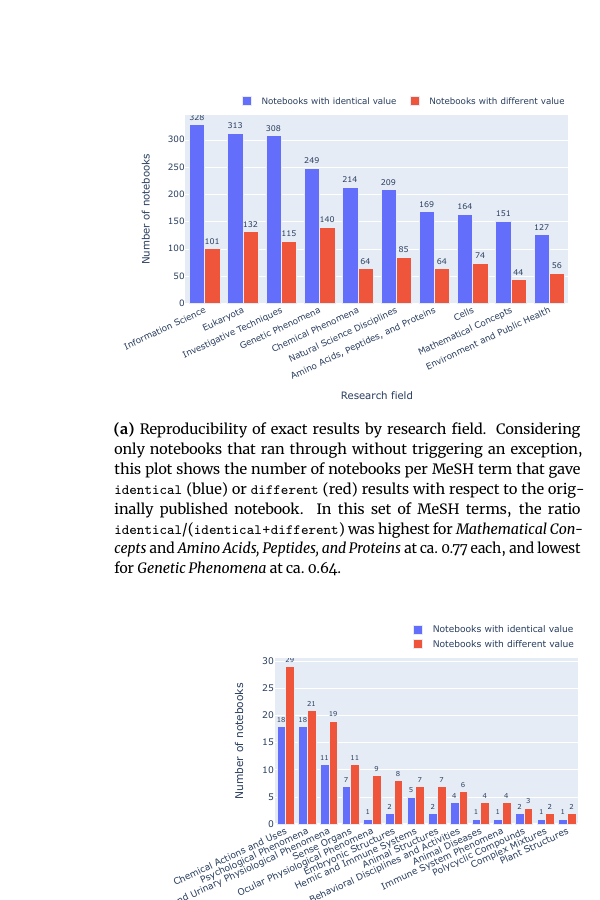
Figure 28(a): エラーなく走った 1,203 本について、MeSH 分野ごとに原著と一致(青)/不一致(赤)の本数を示す。identical/(identical+different) 比は Mathematical Concepts と Amino Acids, Peptides, and Proteins で約0.77 と最も高く、Genetic Phenomena で約0.64 と最も低い。
- ジャーナル別: 例外率が 50% を超えるジャーナル(Nature, Nucleic Acids Research)もあれば、低いジャーナル(iScience, BMC Bioinformatics)もある。例として iScience は 1,684 本中26例外(2%)、GigaScience は 405 本中116例外(29%)。
- 論文種別: Tools and Resources や Software のような技術寄りの論文種は平均より再現性が良く、OUP が出す生物系論文は悪い傾向。
- Markdown とコードの比率: Markdown が相対的に乏しい(比率が低い)ノートブックほど例外が出やすい。例えば FileNotFoundError の34%は Markdown セルゼロのノートブックで起きていた。
限界と位置づけ
- 手動修正をしていないので、ここでの「再現できない」は「公開された状態のまま全自動では動かない」という意味。人が直せば再現率は上がりうる(著者も多くは依存・パス・データ同梱の問題で改善余地が大きいと述べる)。
- 資源プロファイル(実行時間・メモリ・CPU/GPU)はセル/ノートブック粒度では測っていない。記録があるのはパイプライン全体の総時間と環境フットプリントのみ。再現性(成否・出力一致)と資源消費は別軸である点に注意。
- データセットとパイプラインは公開され、Python バージョン・MeSH・ジャーナル・論文種・エラー種で絞り込める「教育用教材の検索基盤」としての二次利用も提案されている。
Q&A
(まだなし)
自分のコメント
(まだなし)