AI解説
情報源: 全文取得済み(著者版PDF、NSF Public Access Repository https://par.nsf.gov/servlets/purl/10064423)。本ノートの数値・記述はこの本文に基づく。CHI 2018 Honourable Mention 受賞論文(Paper 32、全12ページ)。
一言で
計算ノートブック(特に Jupyter Notebook)が、設計意図どおりに「分かりやすい計算ナラティブ(computational narrative)」を語るために使われているのか、それとも単にデータを探索(exploration)するためだけに使われているのかを、3つの研究で実証的に調べた論文。結論は「探索と説明(explanation)の間に緊張関係がある」。多くのノートブックは説明テキストに乏しく、説明はしばしば別メディア(スライド・メール・README)で行われる。UCSD が公開した約123万ノートブックのコーパスの元論文でもある。
注意: これは静的・量的(および質的)な利用実態調査であり、セルの実行時間・メモリ・CPU/GPU といった実行時資源は一切測っていない。測るのはセル数・コード行数・マークダウン語数・テキスト/コメントの有無・実行順序などのノートブックの中身の構造である。
問題と課題の切り分け
- 問題(解くべき問題): データ分析は反復的・探索的で、分析者は「どの版のコードがどの結果を生んだか」を追いにくく、コードを「使い捨て」とみなして注釈を付けない傾向がある。その結果、分析の追跡・共有・再現・レビューが難しくなる。計算ノートブックはコード・可視化・テキストを1文書にまとめてこれを解決するはずだった。
- 課題(この論文がやること): 「ノートブックは実際に説明・共有のために使われているのか、それとも探索のためだけか」を、(1) 大規模量的分析、(2) 学術ノートブックの質的分析、(3) インタビュー、の3研究で評価し、設計上の機会を示す。
背景
データ分析は Tukey 的な「データを見て何を語っているか探る」反復・不正確な営み。分析者は obtain → clean → profile → analyze → interpret のサイクルを回し、何度も dead end に当たる(Kandel ら, Guo ら)。判断(judgment)が多く入るほど非同期メディアでの共有に向かなくなる(Harper & Sellen, IMF の観察)。再現性のためには最低限コードの配布が要るが(Peng)、分析者自身が手順を再構成できないことも多い。
計算ノートブックは Knuth の literate programming の系譜にあり、Jupyter / RNotebooks の登場で爆発的に普及した。Project Jupyter はノートブックを「計算ナラティブを構築・共有するためのエンジン」と位置づけた(Perez & Granger)。ナラティブとは「順序づけられ、つながりを持った一連の出来事」であり、順不同の集まりや断片の寄せ集めはナラティブではない。情報可視化の分野では narrative visualization の研究(Segel & Heer の7ジャンル、Hullman らの sequence 研究など)が蓄積されてきたが、ノートブックのナラティブは「洞察」だけでなく「どうやってその洞察を得たか」まで伝える必要がある点で既存の可視化ナラティブとは異なり、その実態は未解明だった。
下図は、論文が「良い例」として挙げる、コード・可視化・テキストが計算ナラティブとして織り合わされたノートブック(Study 2 の対象の1つ)。
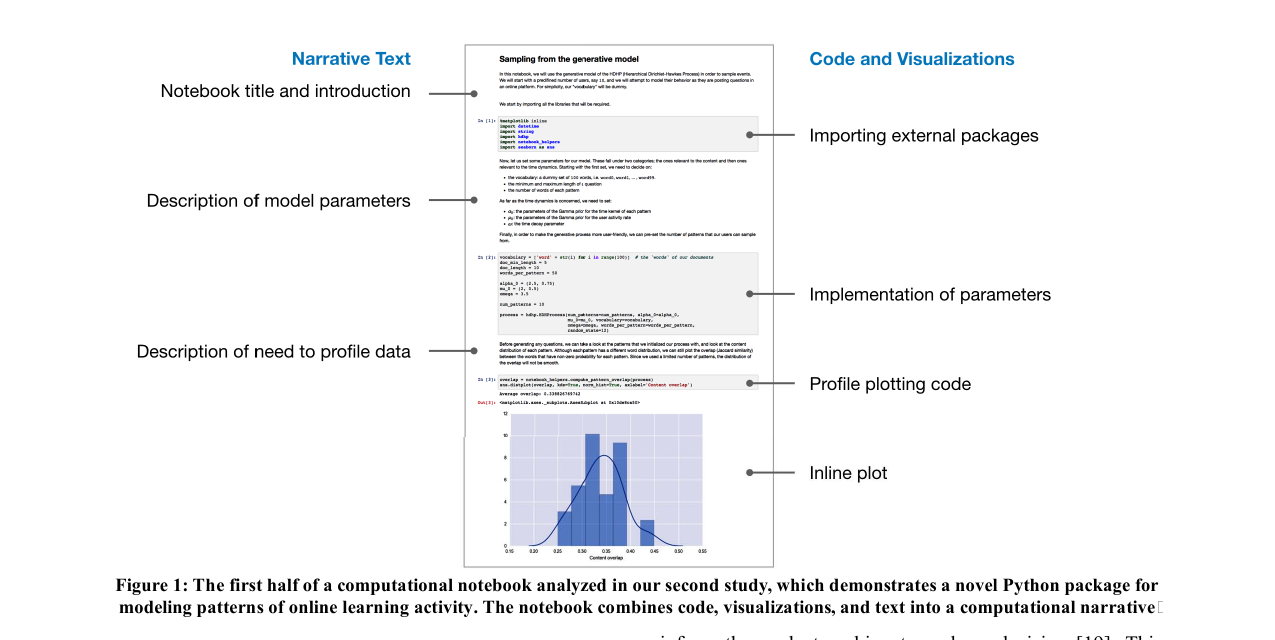
Figure 1: Study 2 で分析したノートブックの前半。オンライン学習活動のパターンをモデル化する Python パッケージを提示するもので、左の「Narrative Text(タイトル・導入、モデルパラメータの説明、データをプロファイルする必要性の説明)」と右の「Code and Visualizations(パッケージのインポート、パラメータ実装、プロファイル描画コード、インラインプロット)」が交互に織り合わさっている。多くの実際のノートブックはこうなっていない、というのが本論文の主張。
Study 1: GitHub 上の計算ノートブックの量的分析
ナラティブが使われているかを大規模に見るため、GitHub 上で公開されている Jupyter Notebook を分析した。
- 収集: 2017年7月、fork されていない公開 Jupyter Notebook を検索。当時 GitHub 上に 1,294,163 個あり、そのうち 1,227,573(約95%)についてノートブック本体・リポジトリ情報・READMEを取得できた。取得できなかったものの多くは不正な JSON か空ファイル。以降の数値はこの約123万(1.23M)ノートブックに対する割合(=UCSD が後に公開したコーパスの母体)。
利用者・リポジトリ
- 公開ノートブックを持つ GitHub ユーザは 100,503人。これは全 GitHub ユーザの約0.4%、推定600万 Jupyter ユーザの1.7%にすぎない。
- ユーザあたりノートブック数は指数分布。24.5%のユーザは1個のみ、27.4%は10個以上。ノートブックの81.4%は「10個以上持つユーザ」に属する。
- Jupyter Notebook を含むリポジトリは 191,402個。39.1%が1ノートブックのみ、14.6%が10個以上。ノートブックの66.4%は「10個以上含むリポジトリ」に属する。
言語・パッケージ
- 言語指定のある85.1%のうち、圧倒的に Python(96.3%)、特に Python 2.7(52.5%)。R と Julia は各1%程度。
- Python/R/Julia のノートブックの89.1%が外部パッケージをインポート。Python で多いのは Numpy(67.3%)・Matplotlib(52.1%)・Pandas(42.3%)で、データサイエンス・可視化への強い偏り。
長さと内容(重要)
- セルの99.8%は markdown か code(raw はごくわずか)。セル数・テキスト量・コード行数はいずれも対数正規分布だが、27.6%のノートブックはテキストを一切持たず、可視化かコードだけで構成されていた(=「4つに1つは説明テキストなし」という abstract の主張の根拠)。逆にコードを持たず全部テキストなのは2.2%だけ。
- テキストありのノートブックでも、中央値は218語(本論文のアブストラクトより少し多い程度)。最長は55,000語(『グレート・ギャツビー』より長い)。
- コード行数の中央値は85行。最長は40万行超(NASA のスペースシャトル主飛行ソフトより多い)。
下図がこの分布と、ノートブック内でのテキスト/コードの位置を示す核心図。
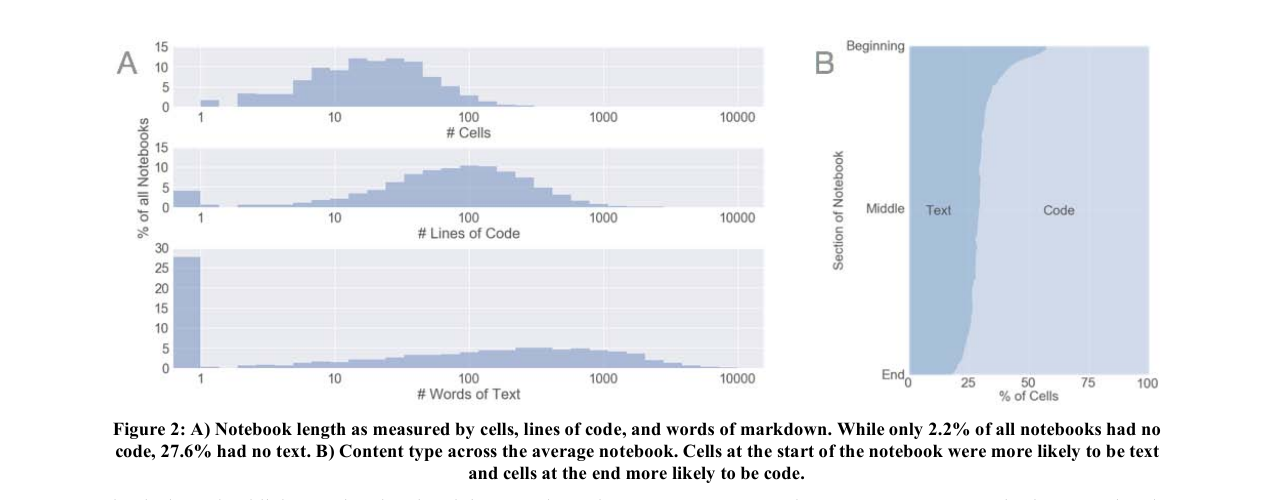
Figure 2: A) セル数・コード行数・マークダウン語数で測ったノートブックの長さの分布。コードなしは2.2%、テキストなしは27.6%。一番下のヒストグラムで「語数0(テキストなし)」が突出している点に注目。B) 平均的ノートブックでの内容タイプ。先頭セルほどテキスト(Text)になりやすく、末尾に向かうほどコード(Code)が増える。
構成・実行・出力
- テキストの72.7%がヘッダーを使い(ヘッダー60.2%、URL 31.6%)、コードの62.1%がコメントを使う(Table 1)。先頭セルはテキストになりやすいが、後半セルの大半はコードに割かれる。
| 要素 | 全ノートブックに占める割合 | |
|---|---|---|
| テキスト | 72.7% | |
| ヘッダー | 60.2% | |
| URL | 31.6% | |
| コード | 97.8% | |
| コメント | 62.1% | |
| 関数 | 37.3% | |
| クラス | 12.3% |
Table 1: ノートブックの構成要素。テキストはヘッダーで、コードはコメントで構成されることが多い。
- 出力ありのノートブックのうち43.9%が非線形な実行順序(上から下に素直に実行していない=前のセルに戻って再実行した痕跡)。これは探索の反復性を反映する。clean run してから公開した人もいるため下限値。
- 85.0%のノートブックが少なくとも1セルに出力を持つ(stream 68.5%、executed result 58.1%、displayed data 45.5%)。
- リポジトリの58.5%に説明、73.0%に README があるが、GitHub ホストのプロジェクトサイトは4.5%のみ。リポジトリ説明の頻出語は learning, project, machine, udacity, course, deep, nanodegree, neural, kaggle, model で、機械学習と教育への偏り。
Study 1 の結論
多くのノートブックはナラティブではなく「スクリプトとゆるい注記の寄せ集め」。テキストは先頭に偏り、末尾には結論テキストがほとんどない。個々のノートブックは単独では完結せず、同一リポジトリの他ノートブックや README と組み合わさって使われる。
Study 2: 学術ノートブックにおけるナラティブの質的分析
学術分析なら、協働・透明性・再現性のために説明テキストが多いのではという仮説を検証。
- サンプリング: README に DOI または arXiv リンクを持つリポジトリを GitHub で検索。得られた858リポジトリから、化学・物理・言語学などキーワードで分野横断に52リポジトリ(221ノートブック)を意図的サンプリング。
- コーディング: 221ノートブックを反復的にコーディング(ジャンル、テキストの構成・利用、コードコメントの構成・利用)。2人が50個をオープンコーディングし、Cohen’s Kappa で60%超の一致率を得てから分担。
- 重複除去: 上位2リポジトリ(52・26ノートブック)は先頭で1〜2パラメータだけ変えて同一セル群を流す「ほぼ同一」のものだったため除外。残り 50リポジトリ・145ノートブックで分析。
- これら145は Study 1 の GitHub コーパスより長い: 中央値で 31セル(Study 1 は18)、102コード行(85)、329語(218)。
結果
- リポジトリ内容: 52中43で notebooks が内容の大半(平均81.6%のバイト数)。README の多くは「コードが何をするか」(33)と「セットアップ手順」(33)を書くが、分析の推論(reasoning)を論じたのは7、結果(results)は10にとどまる。
- テキストの使い方: 導入テキストセルを持つのは55%だが、結論テキストセルを持つのはわずか3%。ヘッダー使用は86%、ヘッダー以外の説明テキストありは77%。ヘッダー外テキストを持つもののうち、88%は分析ステップ(手順)の記述に使うが、推論の説明は34%、結果の議論は38%のみ。
- コードコメント: 82%がコメントを持つ。そのうち99%は「コードが何をするか」、50%は代替コードをコメントアウトしてフロー制御(=版を試して捨てた痕跡)。だが推論の説明に使うのは10%、結果は4%のみ。
- ジャンル: 完全な分析(full analysis)54、図の再現(figure replication)50、パッケージのチュートリアル 41。full analysis ほどヘッダー外テキスト・導入・推論記述が多く、figure replication ほど結果の議論にテキストを使う傾向(ただしサンプルが小さく統計的有意差なし)。
Study 2 の結論
最も饒舌な full analysis ジャンルですら、推論と結果が論じられるのは半分未満。多くは「コードを説明するときどき注記が付くスクリプト集」。145中90ノートブックは、自分のリポジトリの README よりテキストが少なかった。説明不足は分析が単純だからではない(半数がフロー制御コメントを使っており、版を試行錯誤している)。
Study 3: データ分析者へのインタビュー
なぜ豊かなナラティブにならないのかを探るため、定期的にノートブックを使う学術データ分析者15人(女性4・男性11、UCSD の8研究室、postdoc 6・PhD 5・staff 3・学部生1)にインタビュー。専門は計算生物学・薬理学・天文学・工学など。12回のインタビュー(3回はペア、9回は個別)、各30〜45分。最近のノートブックを少なくとも1つ見せてもらって基点にし、文字起こし→アフィニティ図でテーマ抽出。
主な所見
- 用途: 多くは教育(講義・宿題・新メンバー訓練)。研究では「実験のための遊び場(playground)」(7人、特にプロトタイプとデバッグ)、多段分析の自動化パイプライン構築(5人)、大規模分析は言語固有のIDEを好む(2人)、ノートブックでは実行せず別所の作業記録として貼るだけ(2人)。
- 再利用の目的: ①来歴(provenance)追跡(試した分析・dead end・古い図の版を残す。ただしセル上書き・再実行で自動には残らない。P6「Jupyter に自分のやったことを追跡してほしかったが、そうなっていなくて悲しい」)、②コード再利用(P14「散らかった版も消したくない、また使うかもしれないから」)、③再現(他人のマシンで再実行できるよう clean & annotated に。P13「人のサーバで動くようにするのは本当に難しい」)、④結果提示(コードを目立たなくしテキストで手法・結果を説明。多くはスライドやワープロ等別メディアに出力を移す)。
- 共有: ノートブックを「個人的・探索的・散らかった」ものと見る分析者は、コードよりメール・文書・スライドで結果だけを共有し、詳細を見たい相手にだけノートブックを添付(P1「協力者は方法論を見ず、ただ私を信頼するので、PDFを添付するだけ」)。一方でノートブックは非プログラマとの対話に良いという声もあるが、その場合は丁寧なキュレーションが要る。
- クリーニング・注釈: 全員が「ノートブックは掃除(cleaning/polishing)してから」でないと使えないと感じていた。「散らかっている」「汚いコード」「いい加減な小技」と表現。掃除が滞る理由は「面倒」「最高の状態でないと注釈を書けない」「時間切れ」。掃除=目次追加・節の連番・1セル100行未満・大きい分析の分割+テキスト注釈。注釈は個人用(迷子防止・記憶)と共有用(高レベルの提示・背景・結果の解釈)で書き分ける。P6「美しい可視化からどんな結論を引き出すか、解釈は自動生成できない、それこそが要点」。
- 社会的期待: 広範な共有・詳細な注釈を促す社会的期待が薄い(P15「PIはコードを気にしない、プロットを見たいだけ」)。物理的な実験ノートでは強い訓練(名前・日付・仮説・手順・結論)があるが、計算ノートブックにはその枠がない(P12)。
- 出版・再現性: 多くが再現可能にしたい義務感を持つが、障壁が複数。①「分析がいつ公開準備完了か」を決められない(P1)、②公開で「批判にさらされる」と協力者から反対される(P7)。
Study 3 の結論
探索(反復的実験→散らかったノートブック)と説明(特定目的のための「掃除」)の緊張が、来歴追跡・コード再利用・再現・提示それぞれの役割で現れる。ノートブックはテキストを織り込めるが、反省や注釈を自動的に促すわけではない。むしろラボミーティングでの発表や論文執筆という社会的実践のほうが、説明・センスメイキングの強い引き金になる(P12「『なぜこれをやっているのか、何が分かったのか、それは何を意味するのか』と座って考えるのは、ほぼラボミーティングと論文執筆のときだけ」)。
結論と設計の機会
3研究は一貫して探索と説明の緊張を示す。探索は「散らかった」ノートブック(代替コード・重複セル)を生み、特定の聴衆(未来の自分・同僚・上司・一般公開)と目的(来歴・再利用・再現・提示)のために掃除しないと説明にならない。掃除は退屈な手作業で、1つのノートブックで複数の目的/聴衆を同時に満たすのは難しい。だから多くの分析者は既存メディアで説明・共有し、「物好き」のためにノートブックへのリンクだけ添える。この「掃除(cleanliness)」問題はソフトウェア工学の refactoring や technical debt の議論と響き合う。
設計の機会(探索を妨げずに説明を促す):
- 構造を活用: 明示的な注釈をナビゲーション・デバッグ・変数状態確認に使う(ある被験者は markdown ヘッダーから目次をフロート表示する拡張を入れてから注釈を書くようになった)。文書/コメントの自動生成にも使える。
- ベストプラクティスの奨励: import を先頭へ、再利用コードを関数化、code smell の自動フラグ(Data Carpentry 流)。
- 非線形ナラティブの支援: 線形構造は優美だが分析過程を十分には支えない。自動バージョン管理や「レイヤー」で構造を簡素化/拡張。
- 社会的介入: ジャーナルが注釈付き分析コードの公開を奨励、ラボが予備結果の共有・レビューの新しい規範を作る。
最後は技術的・社会的要因の組み合わせが必要、という締め。
限界(論文記載)
- Jupyter Notebook に限定(RNotebooks や Mathematica では傾向が違う可能性)。
- Study 1 は公開ノートブックのみ(アーカイブ目的・共有非想定のものも混在しうる。個人用や少人数共有用とは見た目が違いうる)。
- Study 2・3 は学術データ分析に限定(教育・企業文脈は将来課題)。
Q&A
(まだなし)
自分のコメント
(まだなし)