AI解説
情報源:本文 PDF(https://tcpp.cs.gsu.edu/curriculum/sites/default/files/EduPar-06.pdf,全8ページ)を全文取得して精読。図(Fig.4/5/8/10/11 の実画像)も同 PDF から抽出して掲載。著者:Lena Oden, Klaus Nölp(FernUniversität Hagen),Philipp Brauner(RWTH Aachen)。ソースコード・データ公開:https://zenodo.org/records/10573107。本ノートの記述は上記本文に書かれた内容のみに基づく。
一言で
並列プログラミング教育で、学生が MPI/OpenMP の C/C++ コードのベンチマーク・プロファイリング・トレーシングを Jupyter(JupyterLab)の中で完結して行えるようにする統合学習環境を作った話。コマンドラインのプロ用解析ツール(Score-P / Scalasca / Cube)を内部で叩き、結果の可視化までノートブック内に出す。GUI の JupyterLab 拡張と C++ API の2経路を用意。19名の学生評価で、ツールを使った学生ほど(自己申告ベースの)習熟度が高まる正の効果が見られた。
背景・問題
並列プログラミングを教えるには、コードや並列アルゴリズムだけでなく 並列性能・スケーラビリティ・性能解析まで扱う必要があり、ベンチマークやスケーラビリティテストを演習に組み込むことが求められる。ところがここに、教育現場特有の 問題(困りごと) が積み重なる。
- 学部生は C/C++ に不慣れなことが多く、さらに bash / ssh の知識も乏しい。これだけで並列アルゴリズムの理解に入る前に挫折しやすい。
- その上で プロファイリング技術の習得が加わると複雑さが跳ね上がる。プロ用の解析ツールは 新しいツールの学習を要し、ドキュメントが貧弱なことも多い。
- オープンソースの性能解析ツールは 大半がコマンドライン用で、可視化には別ソフトのインストールが要ることもあり、それ自体が学生が自力で課題を解く際の障壁になる。
- Jupyter は並列教育に向くが(後述の利点)、インタプリタ実行の C/C++ はコンパイル版より遅く本格的な性能解析に不向きで、しかも 性能解析ツールが Jupyter 環境に統合されていないため、学生は外部ツールに頼らざるを得ない。
ここでの 問題 は「学生がプロ用のプロファイラ/トレーサを使いこなせない・環境構築でつまずく」ことであり、それに対する 課題(やること) が「これらの解析を JupyterLab に統合し、ワンクリック/数行で使えるようにする」ことである。
なぜ Jupyter なのか(採用理由)
論文が挙げる Jupyter の教育上の利点:
- Web ブラウザ経由でアクセス:JupyterHub / JupyterLab により、SSH 不要のユーザフレンドリな入口になる。
- テキストとコードの結合:理論背景・指示・コードを1ファイルにまとめられ、読みやすい教材になる。
- 再現性:学生どうし・教員と成果を共有し、実験を再現・検証できる。
- フィードバック/評価:教員がノートブック内で直接フィードバックできる。
著者の大学は通信制(distance learning)大学で、学生は社会人が多く年齢層も広い(後述の評価で 23〜66 歳、中央値 35)。非同期・自習中心が前提なので、教材は自己完結・自己説明的である必要があり、ツールの使い方も動画とサンプルノートブックで説明している。
Jupyter での C/C++ 並列プログラミングの土台
- Xeus フレームワーク上の
xeus-clingカーネルを使う。これは Cling(LLVM/Clang ベースの対話型 C++ インタプリタ)に依存し、C++ を対話実行できる。 - OpenMP:
kernel.jsonに-fopenmpを入れることで OpenMP 4.5 の機能を有効化(Fig.1 の例)。OpenMP はスレッド並列なのでカーネル内でそのまま動く。 - MPI:MPI はプロセス並列で、複数の並列カーネルを起動するとデッドロックやスケーラビリティテストの難しさが出る。これを避けるため
%%executableセルマジックを使う。入力セルのコードを実行可能バイナリにコンパイルし(%%executableセルがmainの入口)、!mpirun -n 2 ./test.binのように複数プロセスで実行する(Fig.2)。関数や非並列の実行はインタプリタで対話的に行える。
ただしインタプリタ実行は遅く、プロファイラも使いにくい。そこで次節の「コンパイルしてから解析する」仕組みを作る。
提案手法:Jupyter でのベンチマーク・性能解析
著者は統合にあたり6つの要件を立てた:(1) ベンチマーク/プロファイル用コードはコンパイルする(インタプリタのボトルネック回避。多くのプロファイラは再コンパイルが必須)、(2) ユーザが問題サイズと並列実行単位数(スレッド/プロセス)を変えられる、(3) 複数の計測区間(timing region)をマークできる、(4) 可視化を Jupyter にシームレス統合、(5) 中間結果すべてにアクセス可能、(6) GUI 拡張と C++ API の両方で使える。
ノートブックをコンパイル可能ファイルに変換
- まず
nbconvertでノートブックを C++ ファイルに変換する。ただし変換結果にはmain関数が無く、そのままではコンパイルできない。 - そこでツールは、ユーザが書いた マーカーコメント
// start_mainと// end_mainを探す。これらはセル実行時には無視されるが、プロファイルツールが本質的なコード領域を識別するために使う。main関数は複数セルにまたがって書いてよい。// start_mainより前に宣言した関数・変数は C++ ファイルに含まれ、// end_main以降は無視される。
この「実行時は無視されるコメントを目印に、後からコンパイル可能な C++ を組み立てる」発想が肝で、同じセルが(ツールが無くても)普通に対話実行でき、かつ解析のときだけ意味を持つという二重性を実現している。
ベンチマーク用マーカー
- 計測区間は
// start_<名前>/// end_<名前>で囲む(Fig.3)。ツールはこれを走査して経過時間を記録する関数を挿入し、結果をファイルに書き出す。 - 同じ名前のマーカー対は1ノートブック内で複数回再利用でき、解析時に番号付けされる。同名マーカーを入れ子にしない(
// start_total// start_communicationのように命名規約で回避)。
問題サイズ・並列実行単位の振り分け(スケーラビリティテスト)
- 問題サイズの定義は一通りでないため、
int n = ... ;の行を1本だけ置く規約にした。ツールはコードをパースしてこの行を見つけ、ユーザ指定の問題サイズで置き換える。マーカーコメントでなく実コードの行を使うのは、問題サイズの定義は常に必要で、ツールが無くてもセルが正しく実行できるようにするため。 - ベンチマークツールは各問題定義ごとに新しい C++ ファイルを生成→コンパイル→実行する。実行単位数は OpenMP では
OMP_NUM_THREADS環境変数、MPI ではmpirunで変える。正確な計測のため、ユーザは OpenMP 関数/指示でスレッド数を手動指定しないようにする。
プロファイリング・トレーシング
- 内部で Score-P / Scalasca を使う。生成した C++ ソースを計装(instrumentation)用の特定コマンドで再コンパイルし、アプリ実行→プロファイルデータ収集→可視化、という流れ。
- ツールはこれらのツールの全機能を使うわけではなく、「網羅的だが圧倒されない」プロファイリングの入門体験を学生に与えることが目的、と明言している(教育目的ゆえの意図的な絞り込み)。
2つの入口:C++ API と JupyterLab 拡張 GUI
- C++ API:
performanceクラスのインスタンスを作る(例performance p("mm.ipynb")、入力はノートブックか C++ ソース)。mm.ipynb自身の中でこのインスタンス化を行えるので、コードの開発と解析を同時並行できる。実行モデル(mpi/openmp/hybrid/serial)は自動判定:MPI_Initがあれば mpi、pragma ompがあれば openmp、両方あれば hybrid。performance p("mm.ipynb", "mpi")のように手動指定も可。 - JupyterLab 拡張 GUI:API を JupyterLab から触れるようにしたもの。新しいメニュー項目(Fig.4)を追加し、クリックするとパネル(Fig.5)が開く。解析の種類(Timing/Profiling/Tracing/Compiler Optimization)とパラメータ(実行単位数・問題サイズ・反復回数・コンパイラフラグ)を選ぶ。GUI 操作は編集可能な入力欄を更新するので、学生は実行される API 呼び出しを見たり書き換えたりできる(GUI で学んだ操作がそのまま API コードとして見える=GUI から API への橋渡し)。プロット生成時は新しい C++ カーネルがノートブック全体(編集欄のコード含む)を実行し、結果を新しい Jupyter パネルに表示する。

Figure 4: JupyterLab 拡張を起動するメニュー項目。「C++ Performance」メニューの「Create Performance Diagram for the current notebook」を選ぶ。
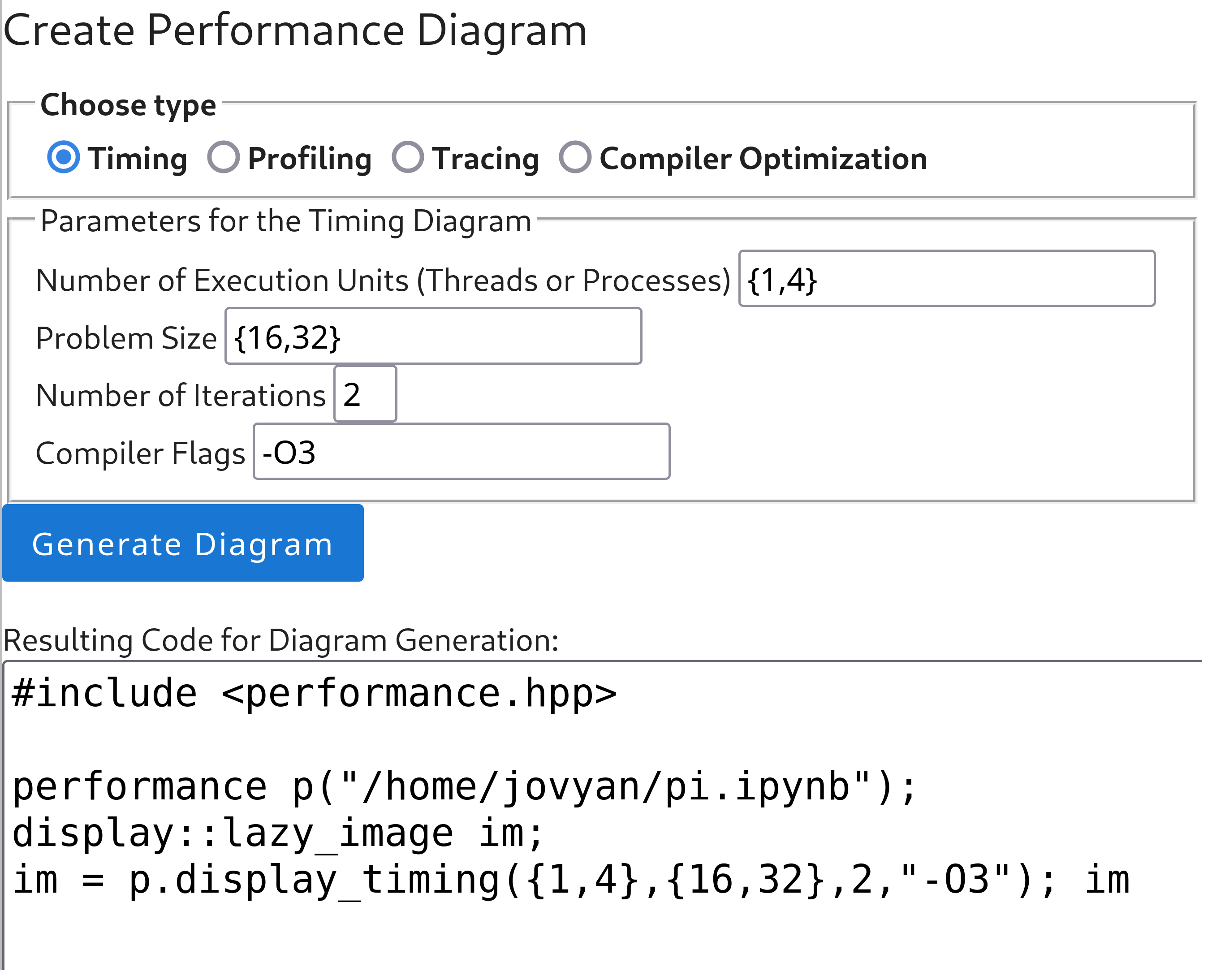
Figure 5: 拡張のパネル。解析種別(Timing/Profiling/Tracing/Compiler Optimization)とパラメータ(実行単位数・問題サイズ・反復回数・コンパイラフラグ)を選ぶと、下部の「Resulting Code」に対応する C++ API 呼び出し(performance p(...) / display_timing(...))が生成・表示される。
授業での使い方と可視化例
著者の大学は通信制で、「並列プログラミング」は学部生向けだが他修士課程の学生にも開かれる選択科目。全6ユニット(並列入門/並列化のアプローチ/OpenMP/MPI/並列アルゴリズム/ビッグデータ(Hadoop, Spark))で、本研究が主に対象とするのはユニット3・4・5のノートブックとツール。出力(ソースコード・計測結果・プロファイル/トレースデータ)はすべて学生のユーザ空間内の専用フォルダに保存され、直接アクセスして further analysis できる。
ベンチマーク(Timing)— 演習3:πの数値積分
- 数値積分で π を計算する課題で、reduction・critical・atomic の同期機構を学ぶ。3手法ぶんの timing マーカーで計測する(Fig.6)。
- 学生は GUI 拡張、または同じノートブック内で
p.display_timing({1,2,4,8}, {(1<<20),(1<<21),(1<<23),(1<<24)}, 4)を呼ぶ(Fig.7)。スレッド数 1/2/4/8 × 問題サイズ 2^20/2^21/2^23/2^24 の全組合せを各4回自動実行し、スケーリングのプロットを表示(Fig.8)。プロットはインタラクティブ(ズーム、数値のマウスオーバー表示)。
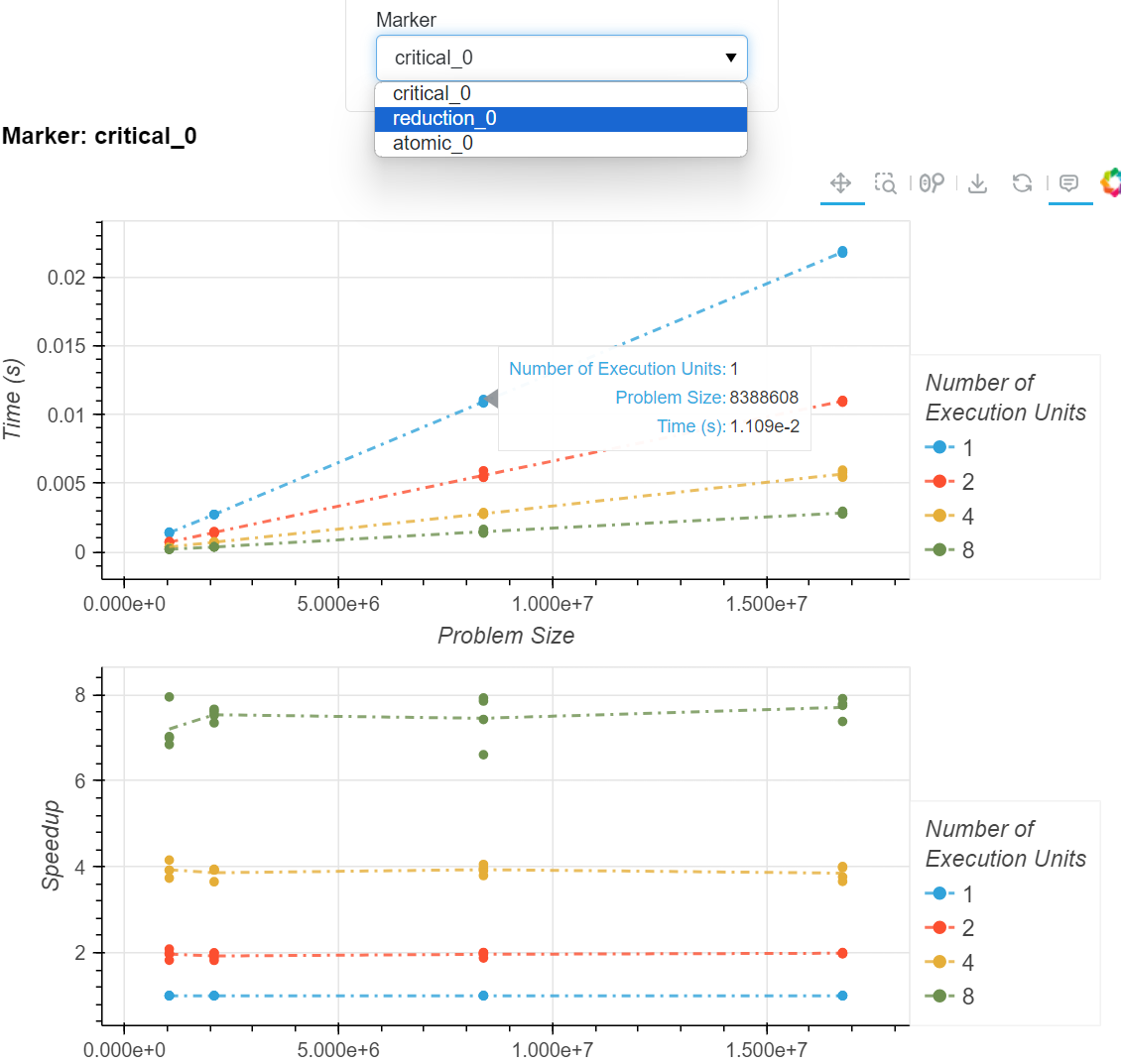
Figure 8: OpenMP による π 計算の自動ベンチマーク出力。上が実行時間 vs 問題サイズ、下がスピードアップ。色は実行単位数(1/2/4/8)。マーカー(critical_0 / reduction_0 / atomic_0)を切り替えて比較でき、点にカーソルを合わせると実行単位数・問題サイズ・時間が表示される。
プロファイリング — 演習5:CSR 疎行列ベクトル積(SpMV)
- CSR 形式で疎行列ベクトル積を実装し、OpenMP 版でスケジューリングアルゴリズムを比較する課題。問題サイズ
nを行列ファイル名に変換するヘルパ関数(Fig.9)で自動ベンチマークに対応。 - プロファイルデータをズームすると、OpenMP の暗黙バリアと for ループの関係を関数名・行番号・(任意生成の)コールグラフから理解できる(Fig.10)。動的スケジューリング時、スレッド 1〜3 がスレッド 0 より大幅に長く待つ=負荷分散の不均衡が見える。
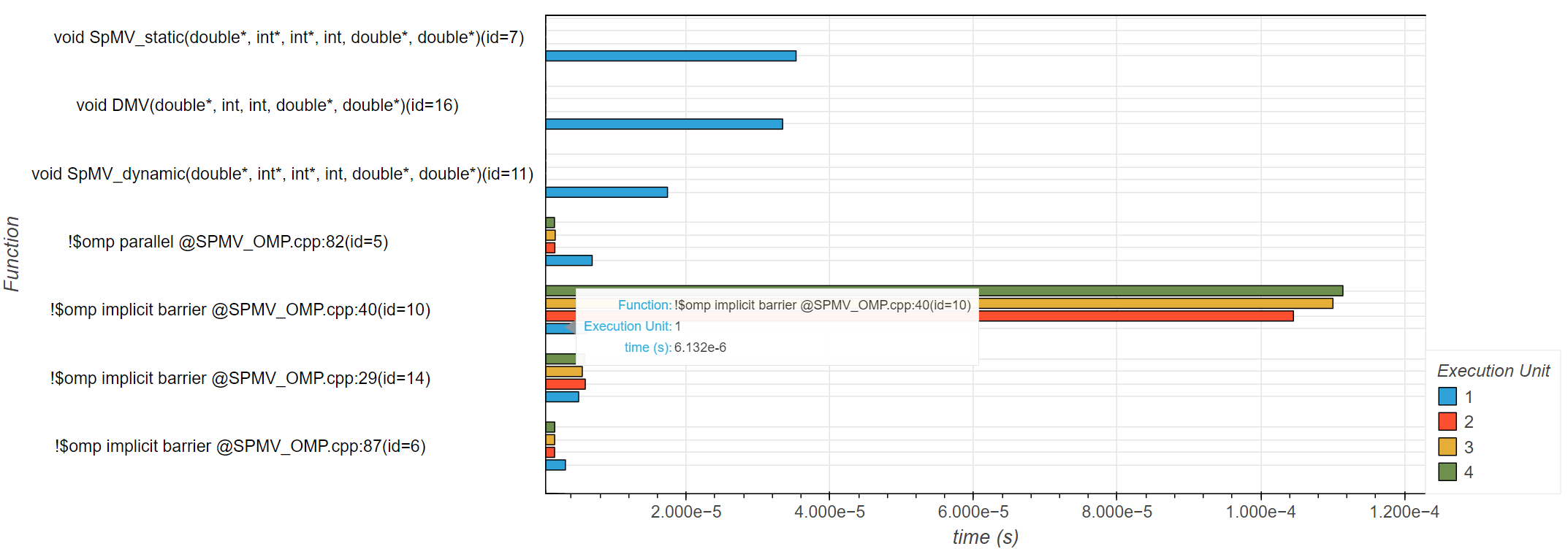
Figure 10: OpenMP(動的スケジューリング)による疎行列ベクトル積のプロファイル出力。関数ごと・実行単位ごとの時間を横棒で表示。!$omp implicit barrier @SPMV_OMP.cpp:40 で実行単位2/3/4 が長く待っており(バリア待ち)、負荷の偏りが読み取れる。
トレーシング — 演習4:MPI による素数計算
- MPI で素数計算を並列化し3版を実装する課題。版1・2は controller-worker パターン(controllerが数(1)または区間(2)を worker に配る)、版3は MPI プロセス間の静的タスク分配。
- 版1のトレース出力(Fig.11)をズームして関連関数だけ選ぶと、計算より通信に多くの時間が費やされていることが見える。特に worker プロセス 1 が
MPI_Recvで長時間ブロックしており、これがボトルネックと特定され、最適化された版2へ学生を導く。
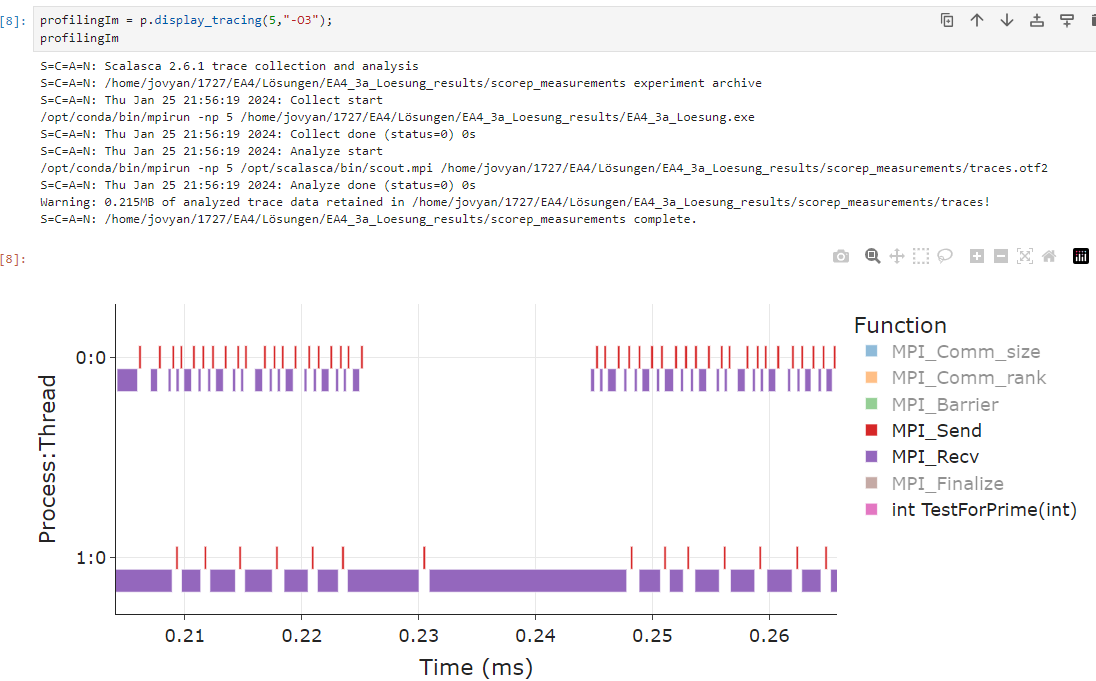
Figure 11: MPI 素数計算(版1)のトレース出力。p.display_tracing(5,"-O3") を呼ぶと Scalasca がトレース収集・解析を行い、プロセス:スレッドごとの MPI 関数(MPI_Send/Recv/Barrier 等)の時間軸タイムラインが出る。worker(1:0)が MPI_Recv(紫)で長くブロックしている様子が見える。
評価(19名の学生評価)
方法
- アンケート調査(GDPR の都合でツール使用ログと試験結果の紐付けは不可なため、自己申告)。LimeSurvey で作成、コース管理システムから招待、リマインダ2回、匿名・任意、謝礼として10ユーロ券3枚を抽選。
- 構成:(1) 人口統計(年齢・性別)と所属プログラム、(2) 専門性とコース評価。一般プログラミング・C++・並列プログラミング・ベンチマーク・プロファイリングの習熟度を 5段階(very low〜very high)で受講前・後を尋ねる pre-post 設計(ただしコース後の単一調査なので前知識の回答は認知バイアスを受け得る)。ベンチマーク/プロファイリングのツール使用頻度(not at all〜whenever possible)、課題外での実験有無も尋ねた。(3) コース/ツールの良かった点・悪かった点の自由記述2問。
- 標本:29名が開始、回答が極端に少ない者を除外して 19名を分析。女性4(21.1%)、男性14(73.7%)、無回答1(5.3%)。年齢 23〜66(中央値35)。学部10(情報学・経営情報学)、修士9(応用情報学・経営情報学)。
量的結果
- 課題外での追加実験:なし5(26.3%)、ある程度13(68.4%)、たくさん1(5.3%)。
- 実行環境:大学サーバ15(78.9%)、自分のPCの自前環境8(42.2%)、自分のPCの提供 Docker コンテナ2(10.5%)。
- ツール使用:標本はおおむね使用者・非使用者で二分。ベンチマークは10名(52.7%)が「使わない/たまに」、9名が「よく/ほぼ/可能な限り」(最頻は「可能な限り」31.6%)。プロファイリングは9名(47.4%)が「使わない/時々」、10名(52.7%)が「よく/ほぼ/可能な限り」(同じく「可能な限り」が最頻 31.6%)。以降の分析では使用者群・非使用者群に分割。
- 学習成果:受講前後で知覚知識が強く有意に増加(
T(df=17) = -12.9, p < .001, d = 3.05、5段階で平均 +1.21 点)。特に並列プログラミング・性能解析・プロファイリングで顕著。これは大学コースとして当然なので、さらにツール使用との関係を調べた。 - 回帰分析(独立変数=ツール使用・受講前の主観的習熟度、従属変数=受講後の主観的習熟度):モデルは有意で分散の 52.3% を説明(
F(2,15) = 10.3, r²_adj = .523, p = .002)。受講前習熟度は強い有意な影響(β = .602, t = 3.51, p = .003)。ツール使用も同程度に強く正の影響(β = .687, t = 2.05, p = .059)だが、有意水準は僅差で超えなかった(脚注:ツール使用のみを独立変数にしたモデルは有意でr²_adj = .204, β = .983, t = 2.37, p = .030)。 - ツール使用は年齢(
τ = .017, p = .934)・性別(τ = -.149, p = .520)と無関係=特定の属性に障壁を作っていないと推測。
表I(回帰):(Intercept) Estimate 2.233 (p<.001);TOOLUSE 0.417, t=2.05, p=.059, std.β=0.687;COMPETENCE(pre) 0.540, t=3.51, p=.003, std.β=0.602。
要するに、提供した性能解析ツールの使用は(あくまで主観的に測った)習熟度に正の影響を与えると示唆された。
質的フィードバック(自由記述の主題分析)
- 肯定:講義スクリプトが「一貫して簡潔・本質を突いている」と好評。最初の4課題は良設計で歯ごたえあり。Jupyter ノートブックは統一された開発環境と使いやすさが評価(「全学生で標準化された開発環境は理にかなっていて楽しい」「ローカル環境構築の手間を考えると提供環境がありがたい」)、ノートブック内でプロファイル結果をすぐ生成できる点、課題が統合されている点。
- 否定:「そもそも Jupyter が好みでない、特に C++ 版は一部の構文にうるさい」、時間帯によって「かなり遅い」という性能問題、ドキュメントをもっと増やしてほしいという要望。課題5は苦戦した学生もいたが「何とかなる」範囲。
限界(著者自身が挙げる)
- 参加者が少ない(専門領域の選択科目+任意のアンケート)うえ学生層が多様で、一般化可能性は限定的。本研究は探索的で、コース概念とツールの実用的評価=今後の改善が目的。
- 正式な pre-post 設計でなく受講前後を1回の調査で同時に聴取したため、自己効力感によるバイアスを受け得る。とはいえ前習熟度を統制してもツールの正の効果は示唆された。今後は設計済み事前・事後テストを用いたフィールド実験(他大学の学生も含む)でより厳密に調べるべき、としている。
結論・今後
新しい性能ツールは JupyterLab に統合され、対話的環境で C/C++ の性能解析を可能にした。学生はツールを気に入り、並列プログラミング・ベンチマーク・性能解析の理解が深まった。ただし全員が Jupyter を好むわけではないため、コードスケルトンや Makefile といった「従来型」教材も Jupyter 外で使えるよう引き続き提供する。今後は C++ ラッパクラスの他言語への移植、Python 可視化の対応解析ツール拡張、設計済み事前・事後テストによる学習成果の本格的測定を計画。あわせて、ドキュメント・UI 設計の不備に起因する問題に取り組む立場から、性能解析ツール開発者にセットアップの簡素化・例示・UI とドキュメントのベストプラクティス(Diátaxis 等)を呼びかけている。計算機科学者の育成を超えて、生産変革など他分野での需要にも言及。
関連研究との関係(論文が挙げるもの)
- HPC への web アクセス手段としての Jupyter(大規模計算センターでの導入報告)。
- Jupyter でHPCの基礎を教えるオープンアクセス講座([9])— ただし Python ベースで性能解析を含まない点が本研究と異なる。
- Jupyter を対話型教科書として並列教育に使う([4])や MPI 実行([17])—
%%writefileマジックや!でのシェル実行を使う。本研究はxeus-clingで C++ を直接使う点、そして これらは自動性能解析・トレーシング・プロファイリングを教育で扱っていない点が差分。 - Score-P バインディング付き Python カーネルで Jupyter 内の Python コードをトレース/プロファイルする先行研究([20])— ただし結果解析に Vampir・CubeGUI などの外部可視化ツールが必要な点が本研究(ノートブック内完結)と異なる。
Q&A
(まだなし)
自分のコメント
(まだなし)