AI解説
情報源:arXiv HTML 全文(https://arxiv.org/html/2502.04184v1)を精読。本文・図・表を読んだ範囲で記述する。数値・図表のキャプションは原文から取得。論文に書かれていない事項は補わない。
一言でいうと
公開ノートブックの「実行可能性(executability)」を、従来の「実行できる/できない」の二値ではなく、より細かい段階で捉え直す研究。先行研究は「公開ノートブックの約76%は実行不能」と報告してきたが、本論文は「そのうち本当に救えない(pathologically non-executable)のは21.3%にすぎず、残り78.7%は環境構成を直せば復旧できる(restorable)」と主張する。GitHub の人気ノートブック 42,546本を対象に、実行不能の原因を分類し、部分実行率という連続的な指標を導入し、さらに LLM(Llama-3)で一部を自動修復できることを示した。
問題(problem)と課題(task)の整理
- 問題(解くべき問題):公開ノートブックの実行可能性を「実行できる/できない」の二値で測ると、実際には作者の元環境では動くノートブック(依存パッケージや入力ファイルが揃っていないだけ)まで「実行不能」と数えてしまい、非実行率を過大評価してしまう。ノートブックは本来セル単位で段階的・対話的に実行されるのに、その性質が評価に反映されていない。
- 課題(著者がやること):(1) 実行不能を「病的に実行不能(pathological)」と「復旧可能(restorable)」に区別する分類軸を導入する。(2)「部分実行率(degree of executability)」という連続指標を定義し、二値ではなく程度で測る。(3) 実行不能の原因をエラー種別で分類する。(4) LLM を使って実行不能ノートブックをどこまで自動復旧できるかを検証する。
用語の定義
- executable(実行可能):最初から最後までエラーなく通る。
- pathologically non-executable(病的に実行不能):構文エラー・インデントエラー・AttributeError など、コードの意味を理解した上でリファクタリングしなければ直せない致命的エラーを含む。表面的な設定修正では救えない。
- restorable non-executable(復旧可能な実行不能):欠落ファイル・欠落モジュール・セル実行順序など、表面的な構成ミスが原因で、作者の元環境なら本来動くはずのもの。
- degree of executability(実行可能性の程度/部分実行率):「最初のエラーが出るまでに実行できたセル数 ÷ ノートブックの総セル数」の比。二値ではなく0〜100%の連続値として実行可能性を測る。
なお、論文の本文では人気ノートブック母集団における全体の実行不能率を 81.5%(34,659本) とし、「病的21.3%/復旧可能78.7%」はこの非実行34,659本に対する内訳として示している(21.3% ≒ 7,387/34,659、78.7% ≒ 27,272/34,659)。アブストラクトで先行研究の「76%」と対置している「21.3%」は、この内訳の病的割合を指す。
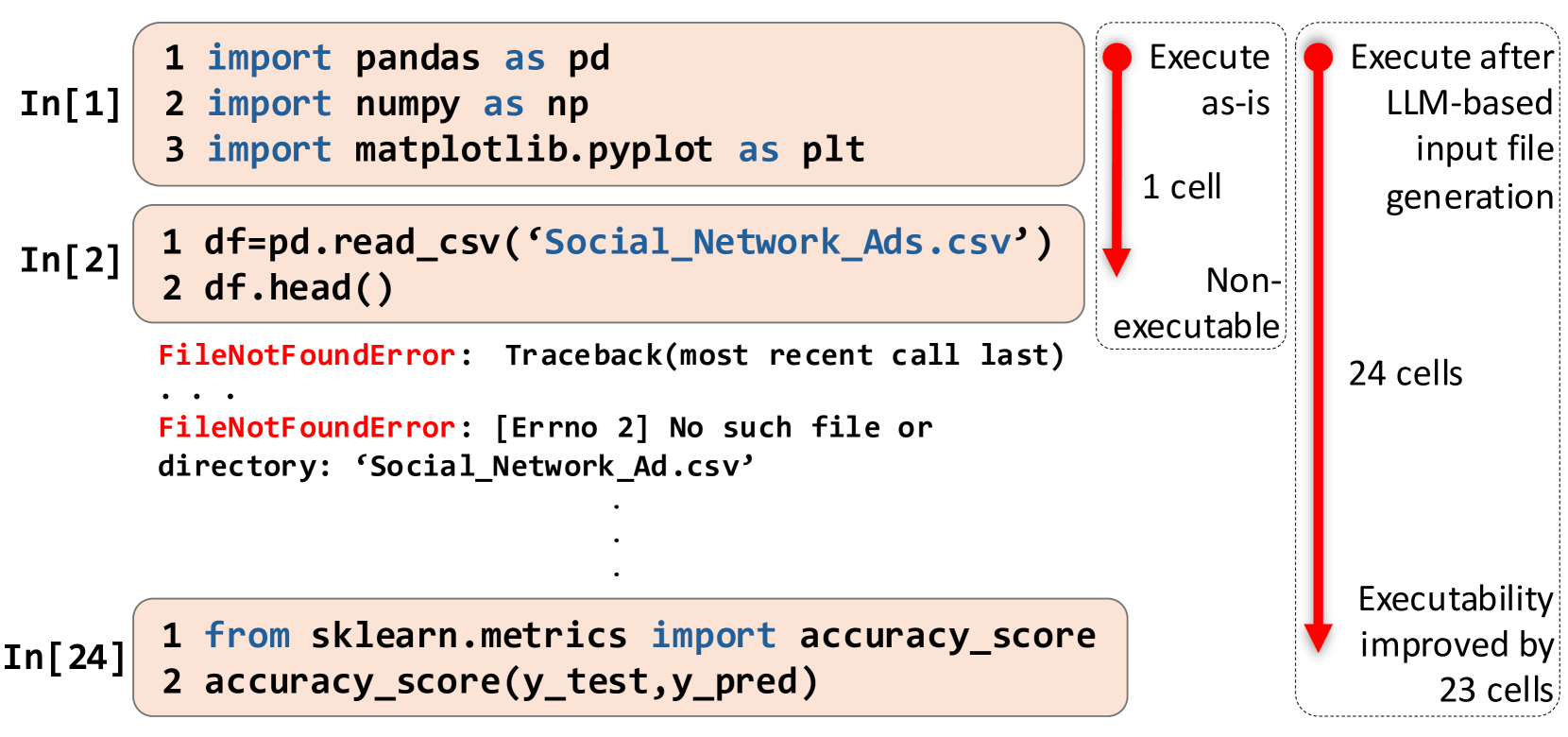
Figure 1: 文献[15]のノートブックは未定義変数のため最初は実行不能だが、欠落していた入力ファイルを生成することで23セル分まで実行可能性を完全に復旧できる、という導入例。
リサーチクエスチョン(RQ)
- RQ1:実行不能の原因は何か。
- RQ2:病的に実行不能なものと復旧可能なものはそれぞれどれだけあるか。
- RQ3:病的に実行不能なノートブックでも、部分的にはどこまで実行できるのか。
- RQ4:LLM ベースの手法で実行可能性をどこまで改善できるか。
手法・パイプライン
著者らは「エラー駆動(error-driven)」の解析・復旧ワークフローを構築する(公開リポジトリ名は ReNote2024)。
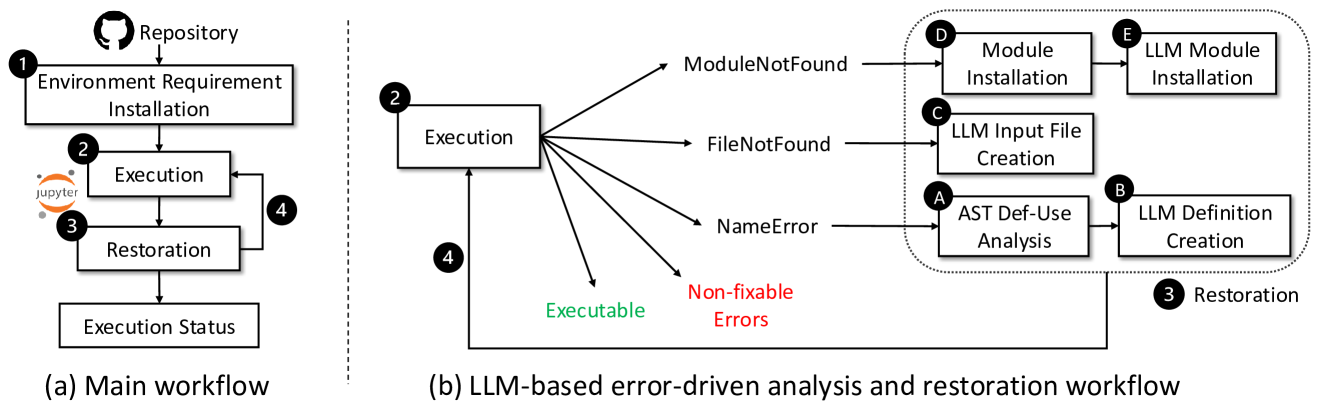
Figure 2: LLM を用いたエラー駆動のノートブック実行可能性解析・復旧ワークフロー。
パイプラインの段階:
- 静的エラー検査:
nbformat等で構文・インデントエラーを検出。 - 環境構築:リポジトリごとに仮想環境を作り、
requirements.txtがあれば依存をインストール。依存衝突を避けるためサンドボックス化。 - 動的エラー検査:Papermill でノートブックを実行し、最初のエラーを記録(実行タイムアウトは1本あたり5分、Python 3 カーネル)。
- エラー分類:ModuleNotFound / FileNotFound / NameError / その他 に分類。
- def-use 解析:各セル内のスコープを意識して変数の定義(def)と使用(use)を追跡する専用の AST ビジターを構築し、セルをまたいだ変数の定義・使用関係を把握する。
- LLM ベース復旧:Llama-3 を使い、合成入力データの生成、モジュール名の修正、欠落関数定義の生成を行う。

Figure 3: 文献[18]のノートブックの最初の2セルに対する def-use リストの例。
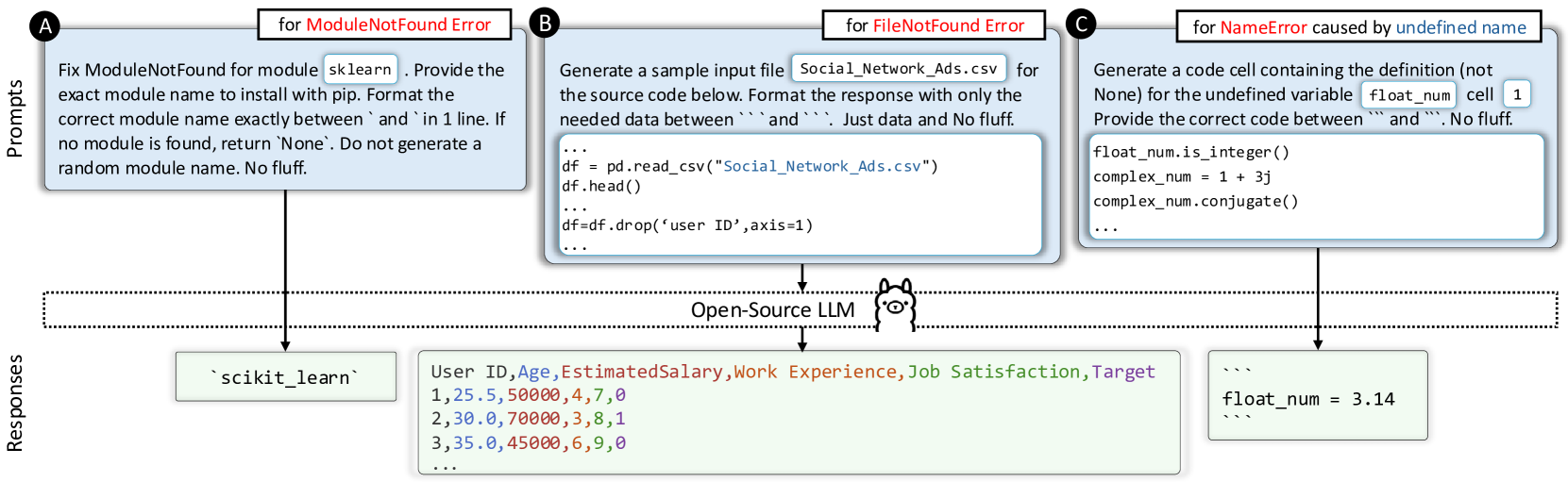
Figure 4: エラー種別ごとの、LLM へのプロンプトと応答の例。
データセット
- 出所:GitHub(2024年時点、★4以上のリポジトリ)。
- サンプリング:スター数の階層(★1000以上 … ★4–9)で層化抽出。当初の約318,000本のうち、LLM 利用コストの都合で約13%を抽出。
- 規模:4,456リポジトリから 42,546本のノートブック。
- 除外:非Python、Python 2、破損・空ノートブック。
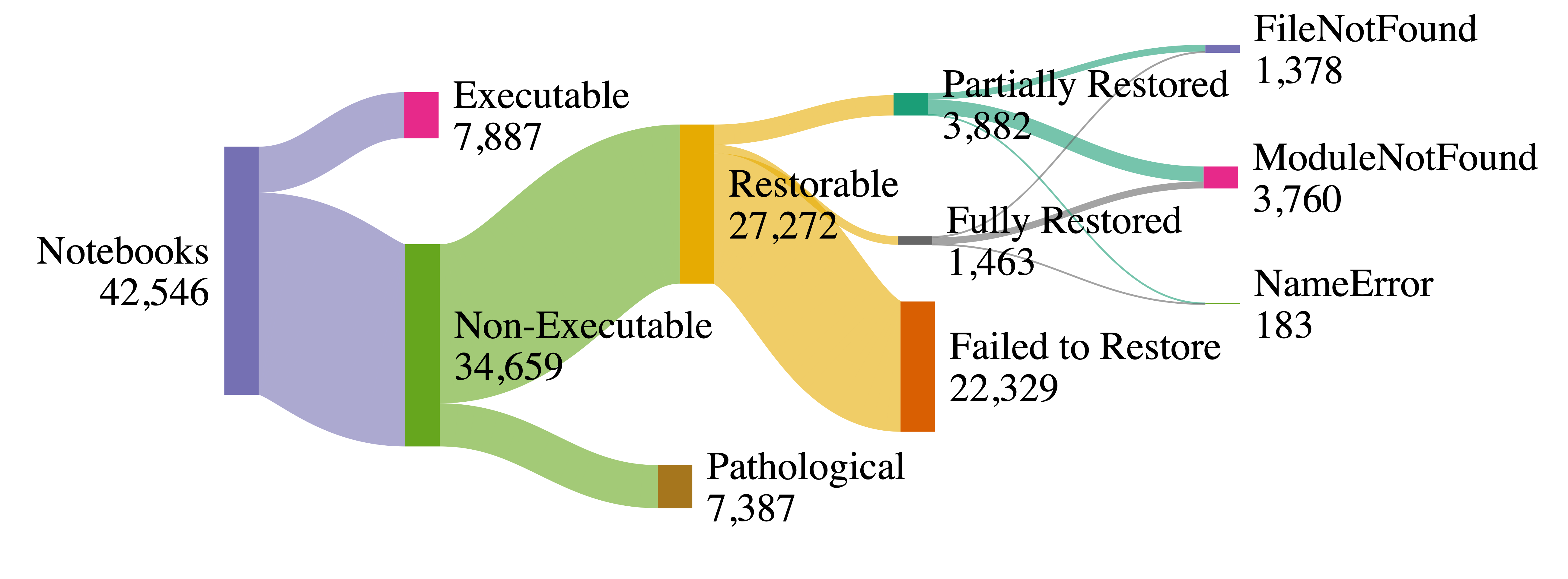
Figure 6: 調査結果の要約。計算ノートブックにおける「実行可能性」の異なる捉え方を示す。総数42,546本が、実行可能7,887本/病的に実行不能7,387本/復旧可能27,272本に分かれる様子をサンキー図で表現。(図はサンキー図のみ取得。Figure 5「ノートブックとGitHubスター数の分布」は本文中のチャートで画像未取得。)
主な結果
RQ1:実行不能の原因(非実行率 81.5%)
非実行ノートブックの主因はエラー種別で上位が偏っている(Table I より)。最多は ModuleNotFound(23,476本、非実行の約67.7%、全体の約55.2%)、次いで FileNotFound(4,546本、非実行の約13.1%、全体の約10.7%)。この2つだけで非実行のおよそ三分の二を占める。以降、AttributeError(1,917本)、ImportError(1,723本)、ValueError(1,705本)、TypeError(1,505本)、KeyError(1,018本)、StdinNotImplementedError(469本)、IndexError(446本)、NameError(404本)と続く。
注目点として NameError は人気ノートブックでは稀(404本、非実行の約1.2%)。先行研究が低品質データセットで14.53%と報告したのと対照的である。さらにスター数別に見ると NameError 率は人気が低いほど高くなる(★1000以上で0.65%、★4–9で2.09%)という逆相関があり、人気=保守状態の良さの代理指標になっていることを示唆する(Table II)。
(Table I「上位10エラーと頻度」、Table II「スター数別の NameError 率」はいずれも本文中の表で、画像としては存在しない=図は本文未取得。数値は本文から転記。)
RQ2:病的 vs 復旧可能
- 当初から実行可能:7,887本(全体の18.5%)。
- 病的に実行不能:7,387本(非実行の21.3%)。
- 復旧可能な実行不能:27,272本(非実行の78.7%)。
「公開ノートブックの大半が実行不能」という従来の見方に対し、本当に救えないのは2割程度であり、大半は環境構成(依存・入力ファイル・実行順序)を直せば復旧しうる、というのが本論文の中心的主張。
RQ3:病的に実行不能なものの部分実行率
病的に実行不能とされたノートブックでも、平均すると 34.1%のセルが最初のエラーまでに実行できる。1,270本(約17.2%)は50%超のセルを実行できる一方、2,059本(約27.9%)は最初のセルで止まる(部分実行率0%)。二値で「実行不能」と切り捨てると、この部分的な実行価値を見落とすことになる。
(Figure 7「病的に実行不能なノートブックの実行セル割合の分布」はヒストグラム。画像未取得=図は本文未取得。)
RQ4:LLM ベースの復旧
- ModuleNotFound(復旧可能の大半を占める):必要モジュールのインストールに成功したのは3,760本(成功率約21.5%)。インストールできた場合、実行セルが平均 40.5%増加。失敗の25.4%は非推奨・削除済みパッケージが原因。
- FileNotFound:合成入力ファイルの生成に成功 3,729本(LLM 成功率約82%)。完全復旧は1,378本。平均で実行セルが 28%増加。
- NameError:LLM 支援で復旧したのは183本(成功率約45.3%)。完全復旧8.7%、部分復旧36.6%、平均 9.4%改善。欠落関数の定義を補うことで改善する例(ケーススタディ2、softmax の欠落定義を補い0→7/14セル=50%改善)が示される。
- 全体:復旧前に完全実行できたのが7,887本だったのに対し、各種復旧後にはおよそ2,000本程度(全体の約4.8〜5.4%)が新たに完全実行可能になった。
(Figure 8「ModuleNotFound 修正による改善分布」、Figure 9「合成入力による改善分布」、Figure 10「復旧前後の完全実行可能ノートブック数」はいずれもチャート。画像未取得=図は本文未取得。)
ケーススタディ
- ケース1:random_forest_algorithm.ipynb(GirlScript、★881)。FileNotFound。LLM が合成データ Social_Network_Ads.csv を生成し、24/24セルを完全復旧(約95%改善)。
- ケース2:DinosaurusIsland 系のノートブック(deep-learning-coursera、★129)。ModuleNotFound + NameError。LLM が未定義の softmax() を補い、0→7/14セル(50%改善)。
先行研究との対置(Table III の要旨)
RELANCER(Kaggle、非実行47%)、SnifferDog(GitHubサンプル、72.6%)、Osiris(再現性、82.6%)、Pimentel ら(140万本超の低スターGitHub、76%)に対し、本論文は 高スターGitHub 42.5K を対象に、モジュールエラー・実行順序/NameError・入力ファイルの全てを扱い、「病的に実行不能なのは21.3%」と結論づける点が新しい。母集団が「人気ノートブック」に寄っていることが、従来の高い非実行率との差を生む大きな要因。
結論・含意
- 二値の実行可能性は非実行を過大評価する。病的エラーと構成ミスを区別し、部分実行率という細粒度の指標を使うべき。
- LLM は合成データ生成・モジュール名修正・欠落関数定義に有用。
- エコシステムの課題として、requirements ファイルを含むリポジトリは25.8%に過ぎず、ノートブック向けのビルド/依存記述の標準化が必要。
妥当性への脅威(threats to validity)
- 古い/空ノートブックの混入(Python 2 除外・空セル除去で緩和)。
- GitHub 偏り(Kaggle・HuggingFace は過少代表)。
- AST パーサの限界によるエラーの見落とし・誤分類。
- 5分タイムアウトによる打ち切り(タイムアウトは約2.5%)。
- LLM による修正がノートブックの意図を変えうる点(著者は「実行可能性は再現性検証の前提」という立場を取る)。
Q&A
(まだなし)
自分のコメント
(まだなし)