AI解説
情報源: VLDB 公開 PDF(PVLDB Vol.14 No.6, pp.1093-1101)を全文(本文 8 ページ+参考文献)精読。図は同 PDF を 300dpi でレンダリングして切り出したもの(Figure 1〜6、Table 1)。arXiv プレプリント版は https://arxiv.org/abs/2012.06981、実装・実験スクリプトは https://github.com/nbsafety-project。本文が「技術レポート [28] を参照」と書いている細部(属性/添字の追跡の詳細、ミューテーション/エイリアス処理、Theorem 1 の証明など)は本論文には載っていないので、その部分は「(本文未取得)」とする。
一言で
Jupyter のような計算ノートブックで、セルを実行・編集・削除・並べ替えするうちに溜まっていく「隠れた状態」のせいで起きる事故(古い変数を参照したまま正しいと思い込む等)を防ぐツール。nbsafety は Jupyter のカーネルを差し替えるドロップイン実装で、実行をトレースしながらシンボル(変数や属性・添字)ごとの細粒度の来歴(lineage)を作り、それと静的解析(ライブネス解析+初期化変数解析)を組み合わせて、「いま実行すると古い値を使ってしまう危険なセル(stale なセル)」と「それを直すために再実行すべきセル(refresher セル)」を、実行前に色付けで警告する。任意順実行(any-order execution)という Jupyter の自由さを壊さずに安全性を足すのが売り。
用語の整理(問題 vs 課題)
- 問題(解くべき problem): ノートブックの隠れた中間状態により、画面上のコードと実際のメモリ状態が乖離し、古いシンボル(stale symbol)を使った不正な実行が起きること。具体的には out-of-order execution(順不同実行)・cell deletion(セル削除)・cell editing and re-execution(セル編集と再実行)が状態とコードの関係をこじらせる。
- 課題(この研究がやること task): 既存のノートブック意味論(特に任意順実行)を壊さずに、(1) 危険なセルを自動検出し、(2) それを直すための修正セルを提案し、(3) これらを対話的に許容できる性能で実現すること。論文は冒頭でこの 3 つを「Key Research Challenges」として明示する。
なお nbsafety が集めるのはシンボル間のデータ依存(来歴)であって、メモリ消費・CPU/GPU・セル実行時間といった資源プロファイルではない。本研究はあくまで「正しさ(staleness)」のための来歴であり、資源計測ツールではない点に注意。
背景・問題
ノートブックは REPL と違い「セル」を実行単位とし、過去のセルを自由に編集・再実行できる。この自由さ(探索的データ分析にうってつけ)が、同時に中間状態の管理をユーザの記憶に丸投げしてしまう。論文の動機例(Figure 1)が分かりやすい。

Figure 1: stale なシンボル使用に至る操作列の例。custom_agg を定義([1])→ それを使う集約辞書 agg_by_col を作り([2])→ それで 2 つのデータフレームを集約([3])。その後ユーザは custom_agg のバグに気づき [1] のセルを修正・再実行([4])したが、agg_by_col を作る [2] を再実行し忘れた。agg_by_col の中には古い custom_agg が残ったままなので、[3] を再実行([5])しても修正が反映されない。タイムスタンプ(実行カウンタ)≤ 3 のシンボルは青枠、> 3 は赤枠で示す。
ユーザは結果を見ても誤りに気づけないことがあり、最悪の場合「修正したのに効いていない」のに「効いた」と思い込む。こうした state 由来のバグは時間の浪費だけでなく研究結果を無効化し再現性を損なう。JupyterCon 2018 の “I Don’t Like Notebooks” のような批判の一因でもある。
既存研究との違い(任意順実行を壊さない): Dataflow notebooks [24] はセルに依存関係を明示注釈させ、依存セルの再実行を強制する。Nodebook [38] や Datalore のカーネル [1] は変数定義をセルが並ぶ順(時間順)に強制する。いずれも「forced in-order」寄りで柔軟性を犠牲にする。nbsafety は著者らの知る限り any-order 意味論を保ったままこの種の安全性を提供する最初のシステム。NBGather [19] は静的解析でノートブックを整理(再現性向上)するが、整理前に起きた状態起因のバグは防げない。
アーキテクチャ全体像
Figure 2: nbsafety のワークフローと構成。3 つの要素がセル実行のたびに回る。(1) Runtime tracer(実行トレーサ) がセル実行中に各シンボルへ親依存とタイムスタンプを注釈する。(2) Static checker(静的検査器) が全セルに対しライブネス解析+初期化変数解析を行い、トレーサが作った来歴メタデータと突き合わせて、実行前に staleness を判定する。(3) Frontend がその結果で「危険なセル(staleness warning)」と「直すべきセル(cleanup suggestion)」をハイライトする。JupyterLab / 従来 Jupyter から、組み込み Python3 カーネルのドロップイン置換として使える。
論文が挙げる 2 つの技術的革新:
- 動的+静的のジョイント解析による正確で効率的な staleness 検出。トレーサが各変数定義に親依存とタイムスタンプを注釈し、それを「runtime state-aware な静的検査器」がライブネス/プログラム解析と合わせて使うことで、セル実行前に判定できる。これにより、従来 Jupyter のセル実行の atomicity(セルは丸ごと走る)を保ったまま警告できる。
- refresher セルの効率的な特定。再実行すれば staleness を解消するセルを見つけるのに、
initialized variable analysis(初期化変数解析、definite assignment analysis)という比較的マイナーな手法を使い、計算量をセル数に対し 2 乗から線形へ落とす。大きなノートブックで効く。
Figure 3: nbsafety の UI。危険セル(stale なシンボルを参照するセル)には赤い staleness warning、それを解消できるセルには緑の cleanup suggestion を、セルの左に色帯として出す。Figure 1 の例で、ユーザが [3] を再実行しようとする前に、[3] には赤(古い値で誤動作しうる)、[2] には緑(再実行すれば直る)が付く。実行前に視覚的ヒントを与え、次に走らせるセルの判断材料にしてもらう。
来歴トラッキング(§3)
用語の定義
- Symbol(シンボル): ノートブックのスコープから参照できる任意のデータ片。トップレベル変数だけでなく、
lst[0]などの添字シンボルやdf.colなどの属性シンボルも第一級として追える。 - Timestamp(タイムスタンプ): シンボルにとっては「そのシンボルを最後に更新したセルの実行カウンタ」、セルにとっては「そのセルが最後に実行された実行カウンタ」。
ts(s)/ts(c)と書く。 - Dependencies(依存): シンボル
sの計算に直接のデータフローで寄与したシンボル群。Par(s)(parents)。 - Stale symbol(古いシンボル):
sの親s'の中にts(s') > ts(s)なものがある(=親の方が新しく更新された)か、親自身が stale なら、sは stale。Figure 1 のagg_by_colはts(agg_by_col)=2だが親custom_aggがts=4なので stale。staleness は親をたどって再帰的に伝播する。
トレーサの仕組み(動的解析)
トレーサは Python 組み込みのトレース機能を使い、line / call / return / exception の 4 種のイベントをフックする。あるセルが実行されると、各文(line イベント)で実行された AST ノードを見て、Table 1 のルールに従い来歴を更新する。

Table 1: 来歴更新ルールの抜粋。a = e のような Assign では Par(a) = USE[e](右辺 e で使われたシンボル集合を a の親にする)。a = a + e(右辺に左辺が現れる)や a += e(AugAssign)では Par(a) = Par(a) ∪ USE[e](既存の親に追加)。for a in e:、def f(a=e):、class c(e): も右辺/基底クラスの使用シンボルを親にする。例えば gen = map(lambda x: f(x), foo + [bar]) 実行直後、USE[…] は {f, foo, bar}(x は lambda 引数なので束縛され除外、map は Python 組み込みで除外)となり、Par(gen) = {f, foo, bar} かつ ts(gen) を更新する。
ポイントは動的+静的のハイブリッドであること: トレーサは実行を観測しつつ、実行が済んだ文の AST を見て静的に右辺の使用シンボルを取り、来歴を更新する。完全な動的追跡(すべての値を追う)は重すぎるため、AST から「使われたシンボル名」を取る軽量な静的処理で代替している。
属性・添字の細粒度追跡: x[0] の親子、x.a のような属性を、トップレベルシンボル x とは別に追う(詳細は技術レポート [28]、本文未取得)。
外部ライブラリ呼び出し: ユーザのノートブック内で定義された関数に入るときはトレースを続けるが、import したライブラリ内の関数に制御が移るとトレースを一旦止める(外部ファイルはノートブック内定義にアクセスできない前提)。オブジェクトを引数で渡した場合、ライブラリはそれを変更しないと仮定する(ミューテーションは将来課題)。これにより追加トレースのオーバーヘッドはユーザのノートブックサイズで上限が抑えられる。
来歴オーバーヘッドの上限: for i in random.sample(range(10**7), 10**5): x += lst[i] のようなセルでは、x の親を 100% 正確にすると lst の 10 万個の添字を持たねばならず非現実的。nbsafety は lossy な近似(x は lst 全体に依存とみなす等。詳細は拡張版 [28]、本文未取得)を採る。保守的近似(lst 全体依存)だと lst に 1 要素追加しただけで x を stale 扱いしてしまうので、それを避ける近似を選んだ。
ライブネス解析と初期化変数解析(§4)
検査器(checker)は liveness analysis(ライブネス解析) と initialized variable analysis(初期化変数解析 / definite assignment analysis) の 2 つの古典的プログラム解析を、1 つのプログラムではなくノートブック(セルの集合)に拡張して使う。
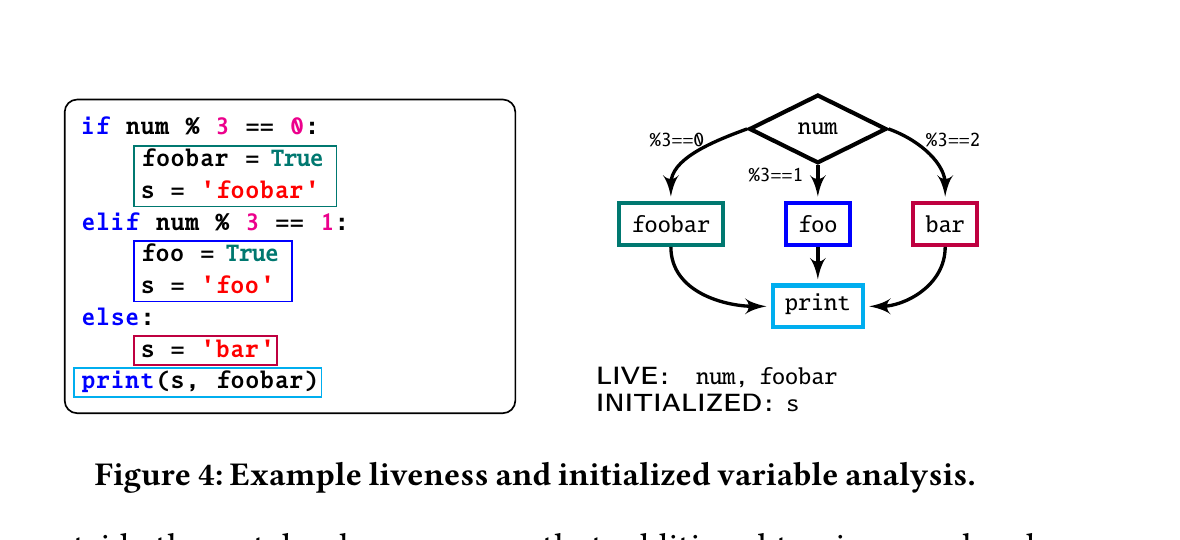
Figure 4: あるセルに対するライブネス/初期化解析の例。if num % 3 == 0 / elif … / else の分岐の後で print(s, foobar) するセル。制御フローグラフ(CFG)の入口で値が後で使われ得るシンボルが LIVE(ここでは num と foobar)。num は条件で必ず使われるので live。foobar は一部の経路でしか代入されず、最後に使われるので live。s は全経路で代入されてから使われるので入口では live でない(dead)。一方 INITIALIZED(= そのセルの終端までに全経路で確実に代入されるシンボル)は s(どの分岐でも s に代入される)。
セル単位への拡張
- Live symbols(live なシンボル)
Live(c): セルcを単体プログラムとみなしたとき、入口での値がc内で後に使われるシンボル。 - Dead symbols(dead なシンボル)
Dead(c):cの終端到達までに全経路で(現在値に依らず)上書きされるシンボル。 - Stale cell(危険セル):
Live(c)の中に stale なシンボルが 1 つでもあるセル。これに staleness warning を出す。シンボルが stale かどうかは live かどうかと独立だが、live で stale なシンボルを参照するセルこそ実害があるので警告対象。 - Fresh symbol / Fresh cell(新鮮なシンボル/セル): あるシンボルが
cより「新しい(tsが大きい)」ときcに対し fresh。stale でなく、かつ fresh な live シンボルを含むセルが fresh cell。fresh cell は「ユーザが再実行したくなりがちなセル」で、これも自動特定できることが貢献の 1 つ。
refresher セル(修正セル)の特定
- Refresher cell(修正セル)
c_r: それ自身は stale でなく、ある stale セルc_sに対し、c_rとc_sを連結したc_r ⊕ c_sの方がc_s単体より stale な live シンボル参照が減るもの。直感的には「c_rを先に走らせればc_sの古さが(場合により 0 に)減る」セル。
| 直接定義どおりに refresher を求めると、全 non-stale セルについて連結のライブネス解析が要り **O( | N | ^2)(N はセル数)になり、大きなノートブックでレイテンシが許容外。そこで **initialized variable analysis を使う。これはライブネス解析の「逆」で、各セル終端までに確実に代入されるシンボル(dead に相当)を前方向に計算する。 |
論文は Theorem 1 を示す(証明は技術レポート [28]、本文未取得):
連結
c_r ⊕ c_sでStale(c_s)が縮むかどうかは、Stale(c_s)とDead(c_r)に共通部分があるかを見れば判定できる(Stale(c_s) − Stale(c_r⊕c_s) = Dead(c_r) ∩ Stale(c_s))。
これにより、dead シンボル → 所属セルの逆引きインデックス(Dead^-1)を一度作っておけば、refresher セル集合 H_r は Equation 1 の形でまとめて計算でき、前処理は **O( |
N | ) のライブネス解析と O( | N | ) の初期化解析**で済む。O(|N|^2) → 線形へ落ちる(§6.4 のベンチで効果を確認)。 |
セルハイライト(§5)
検査器の出力と来歴メタデータを合わせ、cell highlights(意味的に関連するセルの集合)を計算する。論文が扱うハイライト集合:
H_s: ノートブック中の stale なセル集合(赤の staleness warning)。H_f: fresh なセル集合。H_r: refresher なセル集合(緑の cleanup suggestion)。- 差分版
ΔH_f(新たに fresh になったセル)、ΔH_r(新たに refresher になったセル)も定義。実行カウンタで暗黙にインデックスされる。
H_s と H_f の計算は素直(各セルで Live(c) を求め、各シンボルが fresh か stale かをメタデータ照合)。H_r は §5.2 の効率化(Theorem 1 / Equation 1)で計算する。UI 上、stale セルはセル左に赤帯、refresher セルは右に緑帯で出し、fresh セルも refresher と同色の補助ヒントを添える。
評価(§6 実証研究)
評価の主目的は「nbsafety が指すセルが実際のユーザ行動と相関するか」を確かめること。ユーザは nbsafety を使っていない(過去ログのリプレイ)ので、ツールの提案が行動に影響していない=バイアスのない検証になる。
データ収集
.ipynbは静的スナップショットでしかなく、どのセルをどの順で再実行したかの対話情報を持たない。そこで IPython が記録するhistory.sqlite(セル実行ごとのソース・実行カウンタの履歴)を使う。- GitHub から 712 リポジトリの history ファイルを収集し 657 個を抽出、合計 約 51000 のノートブックセッションを得た。
- そのままではファイル欠損等で忠実に再現できないセッションが多いため、Yan ら [37] のアイデアを応用してセッション修復を行い、リプレイ可能な 2566 セッションに絞った。さらにセル実行の 50% 超で例外を投げるセッションを除き、最終的にメトリクスを取れたのは 666 セッション。
評価指標(predictive power)
Predictive power(予測力)P(H): 「ハイライト集合 H から次に実行されるセルが選ばれる確率が、ランダムに比べ何倍か」。次セル c が H に入っていれば P(H) = (|H|/|N|) / |H| × |N| = |N|/|H| の形(ランダム基準は期待値 1)。P(H) > 1 なら「ユーザはそのハイライトのセルを選びがち」、P(H) < 1 なら「避けがち」を意味する。集合が H = {c}(1 個)のとき最大 |N|。
比較対象のベースライン: H_n(次セル=直前に実行されたセルの k+1 番目を常に出す)、H_rnd(ランダムに 1 セル選ぶ)。
予測力の結果
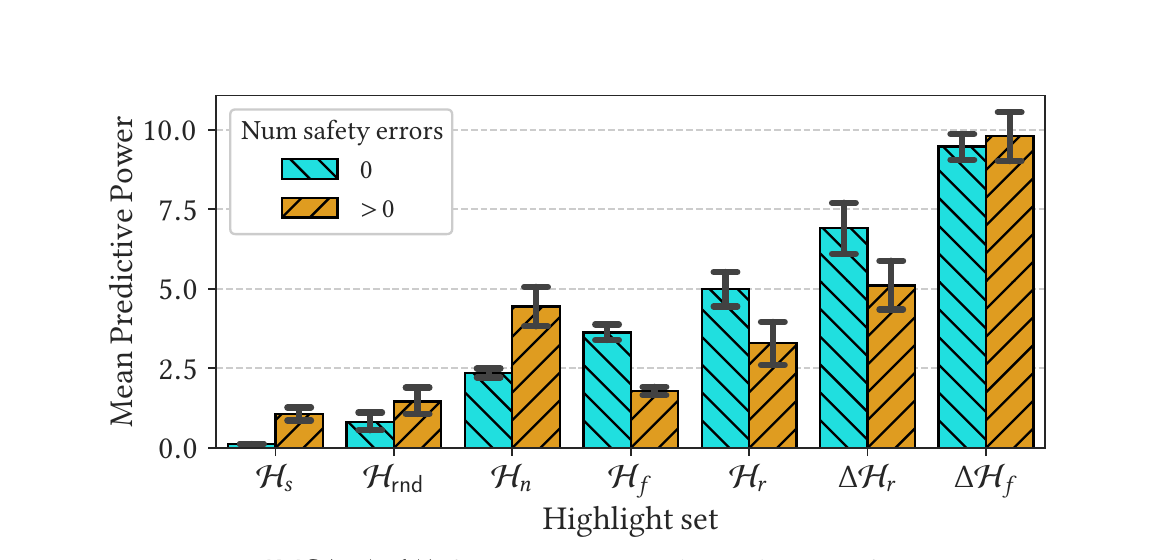
Figure 5: 各ハイライト集合の平均予測力 AVG(P(H)) を、安全エラーのある/ないセッションに分けて表示。青=エラー 0、橙=エラー > 0。
主な数値(Table 2 より):
H_s(stale セル)の予測力は 約 0.30 と最も低い。P(H_s) < 1= ユーザは stale なセルを避けて実行する傾向。逆に言えばユーザは「ランダムに選ぶより 3 倍以上 stale セルを選ばない」。H_f(fresh),H_r(refresher),H_n(次セル),ΔH_f,ΔH_rはいずれも平均P(H) > 1。特にΔH_f(新たに fresh になったセル)が最高で約 9.17、ΔH_rも約 6.20 と高い。差分ハイライトが特に「次に選ばれる」セルとよく一致する。H_n(直後の次セル)は positive な集合の中で最低(平均 2.64)。nbsafetyのH_f/H_r(特に差分版)の方が、単純な「次のセル」より行動とよく合う=設計上の視覚ヒントが有用だと支持。- どのハイライトも平均サイズ
|H|が 4 を超えず、情報過多にならない。
安全エラーの有無による違い: 666 セッション中 117 セッションで 1 回以上の安全エラー(stale セルを実際に実行)を検出、残り 549 セッションにはエラーなし。
- エラーありセッションでは
AVG(P(H_n))が有意に高い = ユーザは何も考えず次のセルを「盲目的に」実行しがちで、それが事故につながる示唆。 - エラーありセッションでは
H_f/H_r/ΔH_f/ΔH_r(positive 集合)を選ぶ確率が有意に下がる = 事故を起こす人ほど「直すべきセル」を選べていない。nbsafetyのヒントが効きそうな対象像。 - エラーなしセッションでも
P(H_s) < 1(stale を避ける)は成り立つが、エラーありセッションではP(H_s)がそこまで下がらず、ランダムを排除しきれない。
要するに 549 のエラーなしセッションでも、nbsafety が「直すべき」と指したセルはランダムに比べ 7 倍以上ユーザに再実行されていた。ツールを使っていないのに提案が行動と一致する=検出ロジックが妥当。
ベンチマーク(オーバーヘッド)
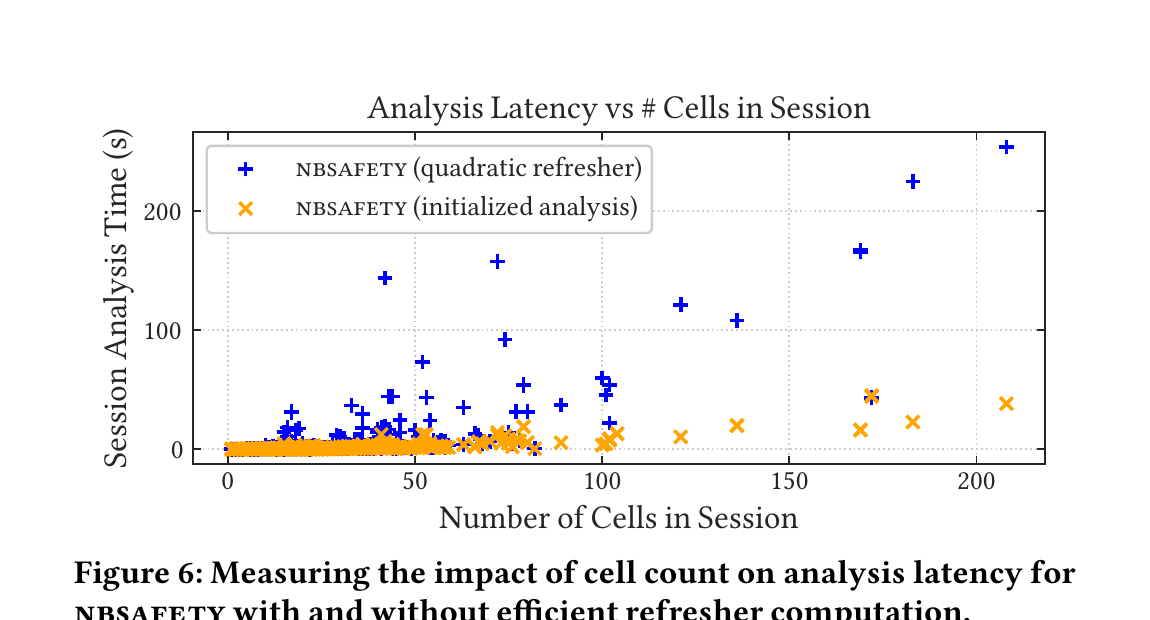
Figure 6: セッションのセル数(横軸)と解析時間(縦軸)。青十字=refresher を素朴な 2 乗法で計算した版、橙バツ=初期化解析で線形化した版。2 乗版は 50 セルを超えると急増するが、線形版はセル数 200 超でもほぼ平坦。
Table 3 の主な数値(666 セッションのリプレイ総時間):
- 解析時間: vanilla Jupyter 0 秒 /
nbsafety990 秒 /nbsafety(2 乗 refresher)5070 秒。 - 総時間: vanilla 3150 秒 /
nbsafety5840 秒 /nbsafety(2 乗)9920 秒。 - 中央値スローダウン(5 秒超かかったセッションで測定): vanilla 1× /
nbsafety1.44× /nbsafety(2 乗)1.58×。
つまり nbsafety の追加オーバーヘッドは vanilla Jupyter と同じオーダーで、666 セッション全リプレイで 2× 未満、典型的スローダウンは 1.5× 未満。初期化解析を使わない 2 乗版だと総応答時間が 3× 超に膨らむので、効率化が効いている。
位置づけ・限界(論文の主張ベース)
- 新規性: any-order 実行を保ったままグローバル状態の安全性を提供する最初のシステム。Dataflow notebooks [24](依存注釈+強制再実行)や Nodebook/Datalore(時間順強制)と違い、柔軟性を犠牲にしない。Vizier [8] は cell versioning とデータ provenance で caveat を警告するが、依存はデータセット API で明示が要る。
nbsafetyは依存を自動推論する。 - 限界(本文記載): 外部ライブラリに渡したオブジェクトのミューテーションは追わない(変更しない仮定)。来歴の上限を抑えるためlossy な近似を入れている。属性/添字の詳細、エイリアス処理、Theorem 1 の証明は技術レポート [28] 送り(本文未取得)。
- 資源計測ではない: 繰り返しになるが
nbsafetyの lineage は正しさ(staleness)判定のためのデータ依存であり、メモリ/CPU/GPU/実行時間のプロファイルは扱わない。
Q&A
(まだなし)
自分のコメント
(まだなし)