AI解説
情報源: 本文全文を精読(arXiv プレプリント版 PDF https://arxiv.org/pdf/2007.10146v2、本文・付録A〜D・全図・全表まで)。本誌オープンアクセス版(https://doi.org/10.22152/programming-journal.org/2021/5/15、Programming Journal 5(3):15、全31ページ)と同一内容。図は PDF の該当ページをレンダリングして切り出したもの(R で描かれたプロット)。以下は論文そのものの記述のみに基づく。
一言でいうと
GitHub 上で公開されている 約270万(2 739 464)件の Jupyter ノートブックを静的に分析し、(1) ノートブックの基本的な特徴(サイズ・コードセル数・言語分布)と、(2) セル(スニペット)単位のコードクローンの蔓延度を、これまでで最大規模かつ初めてリポジトリ間(inter-project)クローンまで含めて測った研究。結果として、スニペットの 70 %超が他のスニペットの完全コピーであり、ノートブックの約半数(約50 %)は一意なスニペットを1つも持たない。Python ノートブックでは少なくとも約 80 % のスニペットが近似クローン(near-miss clone)であった。
ここで強調しておきたいのは、本研究は GitHub に置かれた .ipynb ファイルのソース(JSON)を読んで集計する静的分析であって、ノートブックを実行して資源(メモリ・実行時間・CPU/GPU)を測ったものではない点である。測っているのは「コードがどれだけ重複しているか」という静的な構造的特徴である。
問題(problem)と課題(task)の区別
- 問題(解こうとしている問題): GitHub などの巨大リポジトリから集めたコードは「重複(クローン)」を大量に含むことが先行研究で知られている。クローンを考慮せずに集めたデータセットで研究すると結果が大きく歪む(例: Lopes らが指摘するように、選び方次第で重複率が大きく変わる)。ところが Jupyter ノートブックについては、コードがどの程度クローンされているかが大規模には分かっていなかった。これでは Rule らの「サンプラーデータセット」のような既存のノートブックデータセットを使った結果も信頼しにくい。さらに、クローンの多寡は API 設計者(よく複製されるコードは関数化候補)や研究者(study object の偏り)にとっても重要な情報である。
- 課題(この論文が実際にやったこと): 約270万件のノートブックコーパスを構築し、(a) ノートブックの基本統計を報告し(§4)、(b) スニペット単位の 完全クローン(CMW) と 近似クローン(near-miss) の蔓延度を測り、(c) クローンがリポジトリ内(intra)に偏るかリポジトリ間(inter)に偏るかを統計的に調べ(§5)、(d) 最頻クローンを目視で定性的に確認した(付録C)。
なお「課題」を「解くべき問題」と取り違えないこと——本論文の主目的は測定・記述(characterisation)であって、クローン削減ツールを作ることではない。
コーパスの規模(§4・付録A)
データは 2019 年春に、Rule らの GitHub API スクリプト(リポジトリ言語が「Jupyter Notebook」に分類され、サフィックス .ipynb のファイルを探す)で取得された。最終的なコーパスは次のとおり。
- ダウンロードしたノートブック数: 2 739 464 件(≒ 2.7M、これが「270万件」の根拠)。
- うち fork 由来 6088 件、JSON が壊れている等で情報抽出不能 13 998 件を除外し、分析対象は 2 719 378 件。
- 分析対象の総サイズは 約921 GB(テキストセル・メタデータ込み)。公開アーティファクト(データ)は1 TB近い。
- 総コードセル数 = 総スニペット数: 36 974 714 個(厳密には抽出エラー1件で 36 974 711)。
- スニペットの総行数: 226 744 094 行(空行を除く・コメント込み)。空行込みでは 262 414 943 行。
ノートブック自体は概して小さい。中央値で 13 kB / コードセル9個 / 約47〜53行だが、分布は極端に右に歪んでおり、最大は 1433 コードセル・約46万行という外れ値もある(表2)。
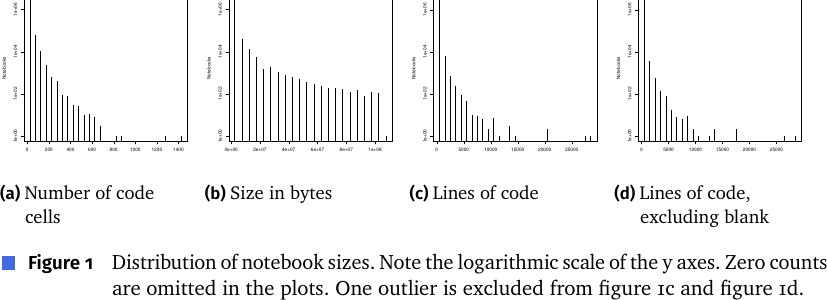
Figure 1: ノートブックサイズの分布((a)コードセル数 (b)バイト数 (c)行数 (d)空行除く行数)。y軸は対数。ゼロ件は省略、外れ値1件を(c)(d)から除外。いずれも強く右に歪む。
言語分布(§4.2・付録B)
言語は metadata.language_info.name → metadata.language → metadata.kernelspec.language → 各コードセルの言語、の順に最初に見つかった値で判定(付録B)。複数フィールドを見ることで先行研究より多くのノートブックで言語を特定できた(言語不明は 2.19 %、Rule らや Pimentel らの手法だと 6.8〜6.9 % が不明になっていたはず)。
分析対象 2 719 378 件の言語分布(表3):
- Python: 2 592 892 件(95.35 %) ——圧倒的多数。
- Julia: 22 336 件(0.82 %)、R: 21 432 件(0.79 %)、Scala: 5155 件(0.19 %)。
- Other(既知): 18 099 件(0.67 %)、Unknown: 59 464 件(2.19 %)。
つまりコーパスはほぼ Python であり、全体の傾向は Python の傾向にほぼ等しい。
クローン分析の方法(§5)
スニペット(=コードセルに入ったコード)単位で、2種類のクローンを別々に測った。ファイル単位・関数単位ではなく「セル(スニペット)単位」で測るのが本研究の特徴。著者ら自作の NotebookAnalyzer / SccOutputAnalyzer と後処理スクリプト(GitHub fxpl/notebooks で公開、付録D)を用いる。
- CMW クローン(Copy Modulo White space、§5.1) = 空白(改行含む)以外が完全一致するクローン。type 1 クローンに近いが、コメントの違いは許さない点が type 1 と異なる(多言語のためコメント除去が困難だから)。手順: 各スニペットから空白を全除去 → MD5 ハッシュを計算 → ハッシュ一致を CMW クローンとみなす。
- 近似クローン(near-miss clone、§5.2) = type 3 寄り。クローン検出器 SourcererCC(Sajnani ら)を使用。SourcererCC はコメント区切りが言語依存なので1言語に絞る必要があり、コーパスの 95 %超を占める Python のみを対象とした。閾値はデフォルトの 80 % 類似度(threshold=8)。128コアサーバで6週間超かけて実行し、報告されたクローンペアは 180億超。なお SourcererCC は1トークン以下のスニペットを無視する(後述の過小評価要因)。
両方について、ノートブックごとの クローン頻度(そのノートブックのスニペットのうちクローンである割合)と、ノートブック間の コネクション数(クローン関係にあるスニペットを持つノートブック対に辺を張ったグラフの次数)を計算。コネクションを intra(同一リポジトリ内) と inter(別リポジトリ間) に分け、Wilcoxon 符号順位検定で intra と inter の大小を比較した。言語間のクローン頻度差は Kruskal-Wallis 検定+Wilcoxon 事後検定(Hochberg 補正)で評価。
CMW クローン(完全コピー)の結果(§5.1.2)
- 最頻クローンは「空のスニペット」で 2 914 109 回出現。全スニペットの約8 %が空。偶発的とみなして以降の分析から除外。
- 少なくとも1つクローンを持つスニペット: 24 773 774 個。クローングループ数: 4 462 974 個。一意なスニペットは 9 286 828 個。
- これより クローン率 72.73 %(= 24 773 774 / 全体)——「70 %超が完全コピー」の根拠。
- すべてのクローンは少なくとも2つの別ノートブックに出現するが、324 740 件(11.94 %)のノートブックは自分自身の中にクローンを持つ(同じスニペットが同一ノートブック内に2回以上)。
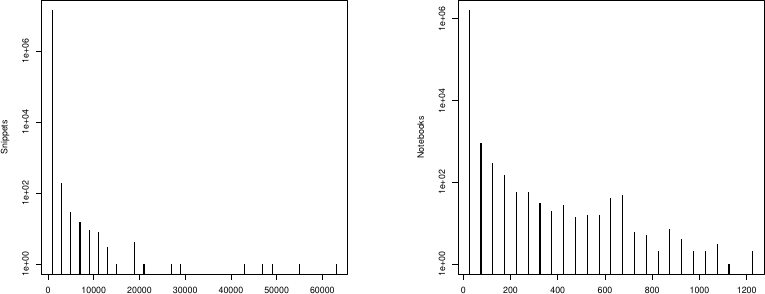
Figure 2: (a)スニペットのクローン出現回数の分布、(b)ノートブックのクローン出現回数の分布。y軸は対数。強く右に歪み、ほとんどのスニペットは200回未満しか出現しない。
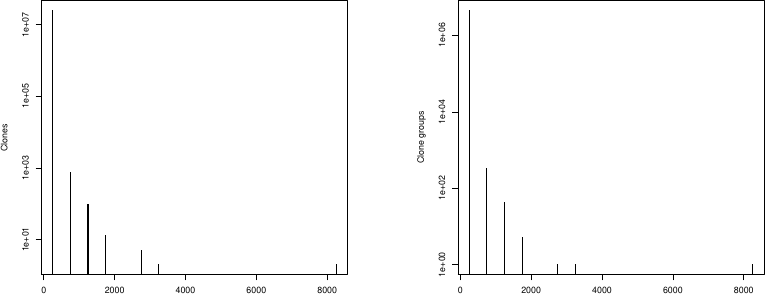
Figure 3: (a)クローンのサイズ(中央値LOC)分布、(b)クローングループのサイズ分布。小さなクローンが圧倒的に多く、小さいスニペットほどクローンされやすい。
クローンのサイズは小さい(表4)。クローンの行数は中央値2行・平均5.83行、90パーセンタイルでも14行。クローングループの行数は中央値3・平均7.48。
ノートブック単位で見ると(極めて重要な数字):
- 1 359 173 件(49.98 %)が「クローンのみ」のノートブック(一意なスニペットを1つも持たない)——「約50 %のノートブックは一意なスニペットがない」の根拠。
- 343 341 件(12.63 %)は逆に「一意なスニペットのみ」。
- クローンを持つノートブックは合計 1 292 653 件。
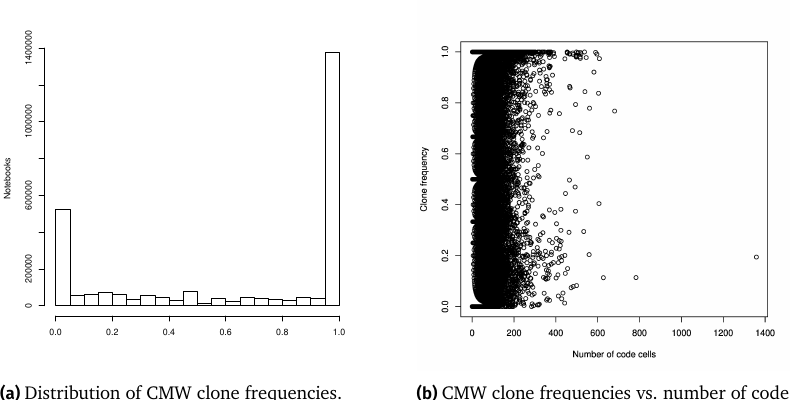
Figure 4: (a)CMW クローン頻度の分布。頻度は「とても低い(<5 %)」か「とても高い(>95 %)」に二極化し、高頻度側が多い。(b)クローン頻度 vs コードセル数。明確な相関は見えないが Spearman で有意(ρ=0.2383, p<2.2e-16)の弱い正相関。
クローン頻度は 平均 64.53 %・中央値 98.91 %(表4)。
言語間の差
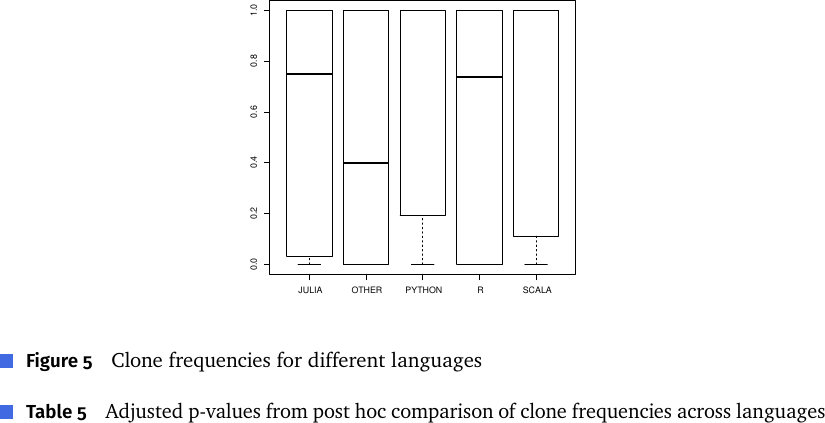
Figure 5: 言語別クローン頻度の箱ひげ図(JULIA / OTHER / PYTHON / R / SCALA)。クローン頻度は Python が最も高く、次いで Scala。最も低いのは雑多な OTHER 群。
Kruskal-Wallis 検定で言語間に有意差(χ²=3748, p<2.2e-16)。事後比較(表5)でも Python–Scala と Julia–R を除く全組合せが 0.001 水準で有意。Python と Scala でクローン率が高い理由は著者らも「困惑している(perplexing)」とし、Python の「やり方は一つ(one obvious way to do it)」哲学が偶発クローンを生みやすい可能性を挙げつつ、Scala は説明できないと正直に書いている(§6)。
コネクション(intra vs inter)
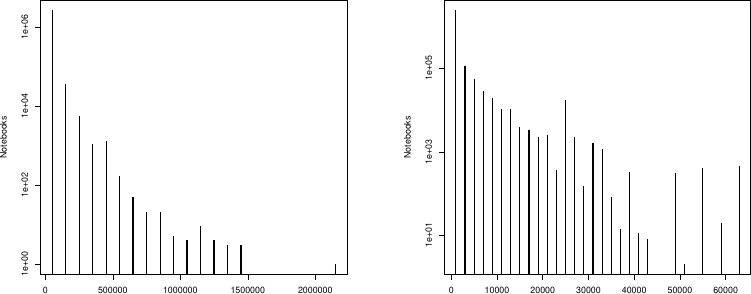
Figure 6: ノートブックあたりのコネクション数の分布。(a)絶対数、(b)正規化(スニペット数で割った値)。y軸対数で強く右に歪む。最大コネクション数は 2 170 917(コーパス全体数に匹敵)。
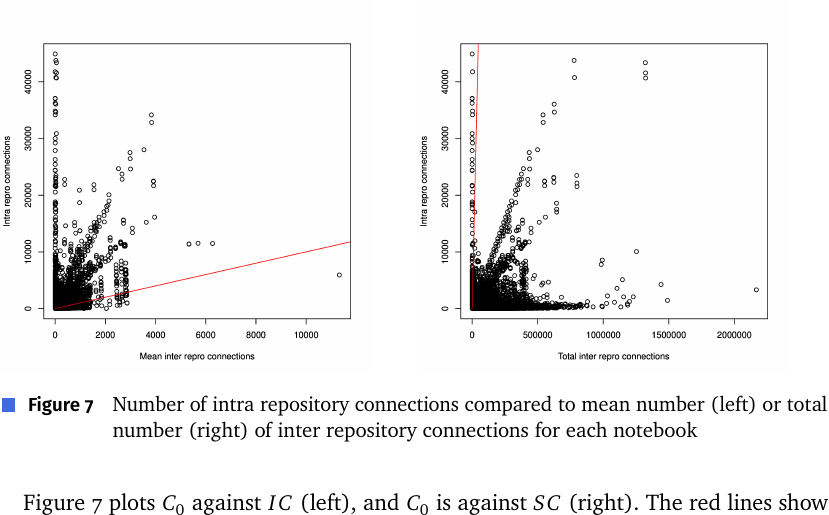
Figure 7: 各ノートブックの intra リポジトリコネクション数(縦軸 C0)と、inter リポジトリコネクションの平均(左、IC)/合計(右、SC)の比較。赤線は C0=IC, C0=SC。C0 は IC より大きいが SC より小さい。
ここがこの論文の鍵となる発見:
- C0 > IC: あるノートブック N がどこかと繋がっているとき、繋がり先が「N と同じリポジトリ」である確率は、「ある特定の別リポジトリ」である確率より有意に高い。
- C0 < SC: しかし「同じリポジトリ」である確率は、「いずれかの別リポジトリ全体」である確率より有意に低い。
- 言い換えると、リポジトリ間(inter-project)クローンの方が圧倒的に多いが、ノートブックが最も多くのクローンを共有する“単一の”相手リポジトリは自分自身のリポジトリである。これは Koenzen らが intra のみで低いクローン率を報告したことの説明にもなる。
近似クローン(near-miss、Python のみ)の結果(§5.2.2)
- Python スニペット 35 450 312 個のうち、3 673 406 個(10.36 %)は0行(コメントのみ等)で除外。
- 少なくとも1つ近似クローンを持つ Python スニペット: 25 339 340 個 = 79.74 %——「Python では少なくとも約80 %が近似クローン」の根拠。CMW(完全コピー)が近似クローンの部分集合なので、CMW より高くなるのは当然。著者らはこれを過小評価とみる(SourcererCC が1トークンスニペットを無視するため。1 076 617 個の CMW クローンは2トークン未満)。
- 自分自身の中に近似クローンを持つ Python ノートブック: 744 548 件(28.71 %)。CMW(11.94 %)の2倍超——自己クローンの過半は CMW では捉えられていない。
- ノートブック単位: 1 258 545 件(48.54 %)が「近似クローンのみ」、140 215 件(5.41 %)が「一意のみ」。
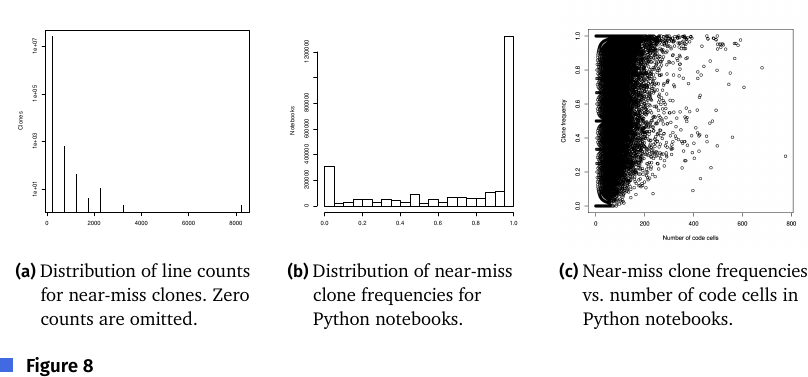
Figure 8: (a)近似クローンの行数分布(CMW と類似、小さいものが多い)、(b)Python ノートブックの近似クローン頻度分布(CMW より「低頻度<5 %」が少ない)、(c)近似クローン頻度 vs コードセル数。
近似クローン頻度は 平均 72.88 %・中央値 96.00 %(表8)。コードセル数との相関は Spearman で ρ=0.1233(CMW より弱い正相関)。
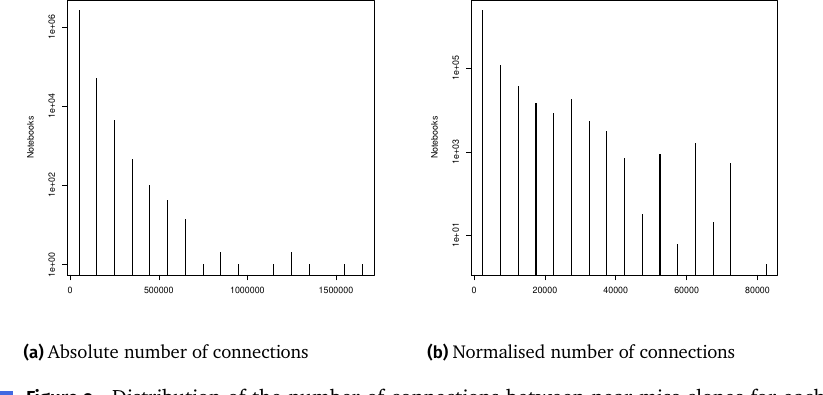
Figure 9: Python ノートブックの近似クローンコネクション数分布((a)絶対数 (b)正規化)。y軸対数。CMW(Figure 6)より総じてコネクション数が多い。
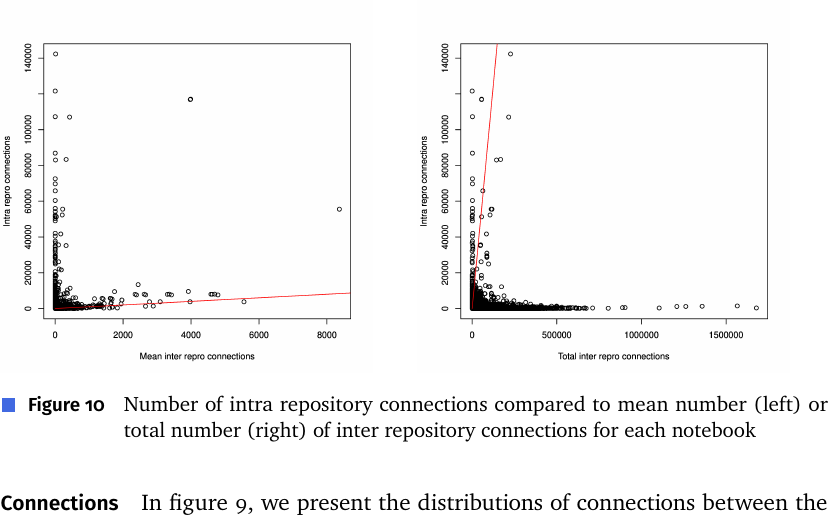
Figure 10: 近似クローンでの intra(C0)対 inter(左:平均IC / 右:合計SC)コネクション比較。赤線は等値線。CMW と同様に C0>IC, C0<SC。
近似クローンでも結論は CMW と同じ: 大半は inter-project クローンだが、最も多く共有する単一リポジトリは自分自身。
定性的な観察(付録C・§6)
最頻クローンを目視確認した結果(CMW についてのみ。near-miss はクローン関係が推移的でないため目視に不向き):
- 4行以上の最頻クローン: 課題テンプレートやライセンス文。最頻は神経回路の課題(4846回)、
cs231講義由来(”DO NOT MODIFY ANYTHING IN THIS CELL” コメント、各1400〜3800回)、ライセンス文(計約4700回、Apache 2.0 が2889回)。テンプレ非依存の最頻 import 群はimport pandas as pd / numpy as np / matplotlib.pyplot as plt / %matplotlib inline(3475回)。 - 1行クローン:
import numpy as np(63 049)、import pandas as pd(55 158)、%matplotlib inline(48 797)、df.head()(47 153)、df(42 101)、変数aの表示(29 926)など。 - 命名の慣習:
pd/npなどの略称、データフレーム名df/df1/df2、1文字変数a, X, x, b, s, ...の多用。これらが偶発クローン(accidental clones)を生みやすい。 - ほぼ同一なノートブックのクラスタは最大で1000〜1200件あり、その多くはチュートリアル/講義教材だった。
考察・含意(§6・§7)
- type 1(完全)クローンが type 3(近似だが完全でない)より多いのは Python の先行研究(Lopes ら、Yang ら)と一致。よって「type 1 クローンだけ見ても網羅的な結果が得られる」可能性があり、これは type 3 検出より遥かに容易なので実用的に重要。ただし他言語では逆(type 3 の方が多い)の研究もあり、近似クローンを一律に無視するのは危険とも注意。
- inter-project クローンが intra より多いのは、Java を対象とした Gharehyazie らの「クローンは主に同一プロジェクト内」という結果と逆。ノートブックという媒体の性質の違いが要因かもしれない。
- なぜクローンが多いか: プログラマが「以前の解からコピーして手直しする(copy-and-patch)」傾向(Koenzen らの観察)が大きい。Django のような定型コード生成フレームワークはノートブックには(著者らの知る限り)存在せず、それゆえノートブックの Python のクローン率は非ノートブック Python コードより低い。
- 妥当性への脅威: GitHub 公開ノートブックが全体を代表するとは限らない(GitLab や非公開のものは性質が違うかもしれない)。チュートリアル/講義由来のノートブックが多く結果を歪めうる。少数(340件)のファイル欠損、SourcererCC 出力のクリーニング、1トークン無視などは結果を大きく歪めないと判断。
自分用メモ(位置づけ)
- これは静的・コーパスレベルの特徴づけ研究で、ランタイム資源(実行時間・メモリ・CPU/GPU)は一切測っていない。ランタイム資源データセットを作る立場からは「公開ノートブックの巨大コーパスがどんな素性か(小さい・Python偏重・極端に重複が多い)」を押さえる背景文献として有用。特に 約半数のノートブックが一意スニペットを持たないという事実は、「公開ノートブックをそのまま実行データセットにすると重複だらけで偏る」という警告として効く(クローン除去/重複排除が前提になる)。
- セル単位という粒度は、セル別の実行時間・メモリを測る対象としてのセルとも対応が取れる。
Q&A
(まだなし)
自分のコメント
(まだなし)