AI解説
出版社版: https://doi.org/10.1145/3626203.3670623(PEARC ‘24, Article 41, 5 pages) 実装基盤: Apache Airavata(https://airavata.apache.org/)上の Cybershuttle Research Environment 情報源: 本文(ACM PDF 全 5 ページ)を全文精読。図 1〜4 も本文 PDF から抽出して掲載。アブストラクトのみだった旧版から、アーキテクチャ・評価まで本文に基づいて全面的に書き直した。
一言で
手元のラップトップで動かしている JupyterLab のノートブックを、UI 操作ひとつで HPC スパコン上のリモートカーネルへ「スケールアウト」できるようにするオープンソースの仕組み Cybershuttle Notebook Gateway。ローカルカーネルを起動するのと同じ感覚で、クラスタの違いを意識せずにリモートカーネルを起動・接続できる。仲介役の Gateway Server が、計算ノード上のカーネルが開く ZMQ ポートを SSH 越しにプロキシすることで、どのクラスタでも一貫した IP でつながる。HPC 側には標準の Jupyter Kernel 以外、追加サービスを一切入れないのが効く点。
背景・問題
科学者の典型的なワークフローは、初期の分析やモデリングを個人 PC で行い、研究が進んで複雑なシミュレーションや大規模データ処理が必要になった段階で HPC へ移る、というもの。だがローカル開発から HPC へシームレスに移る手段が無いのが問題。論文が具体的に挙げる詰まりどころ:
- 複数クラスタを相手にする複雑さ:ジョブ投入の仕組み(スケジューラ)、セキュリティポリシー、資源制約がクラスタごとに違う。
- ファイルシステムのマウントやデータ同期といった技術的作業が、その都度のしかかる。
- 認証・アクセス制御・データ転送の管理が環境をまたいで発生し、HPC の使い勝手とアクセス性を損なう。
JupyterLab はコード・数式・可視化・記述テキストを束ねる実行可能ドキュメントを作れる Web ベース IDE で、Python・R・Julia など複数言語に対応し科学コミュニティで広く使われている。だがローカルとリモートを効率よく橋渡しすること自体が依然として課題として残る。
既存解との差分が論文の主張の肝。既存解はどれも「リモート資源側に Jupyter ランタイムを展開する」発想で、ユーザの手元のローカルなノートブック環境への直接の橋渡しを提供しない、という整理:
- Google Colab / JupyterHub:クラウド上にデプロイする方式。
- Open OnDemand:HPC クラスタ上にノートブックサーバを立てられる。
- Jupyter Kernel Gateway:ローカルのノートブック実行とリモートカーネルの統合という、まさにこのギャップを埋めようとするもの。ただし設定が複雑で、ユーザのワークフローを乱し生産性を損なう。
つまり「ユーザは手元の JupyterLab に居たまま、UI からリモートカーネルへ scale-out / scale-in したい」という研究上の未充足ニーズに応える、というのがこの論文の立ち位置。
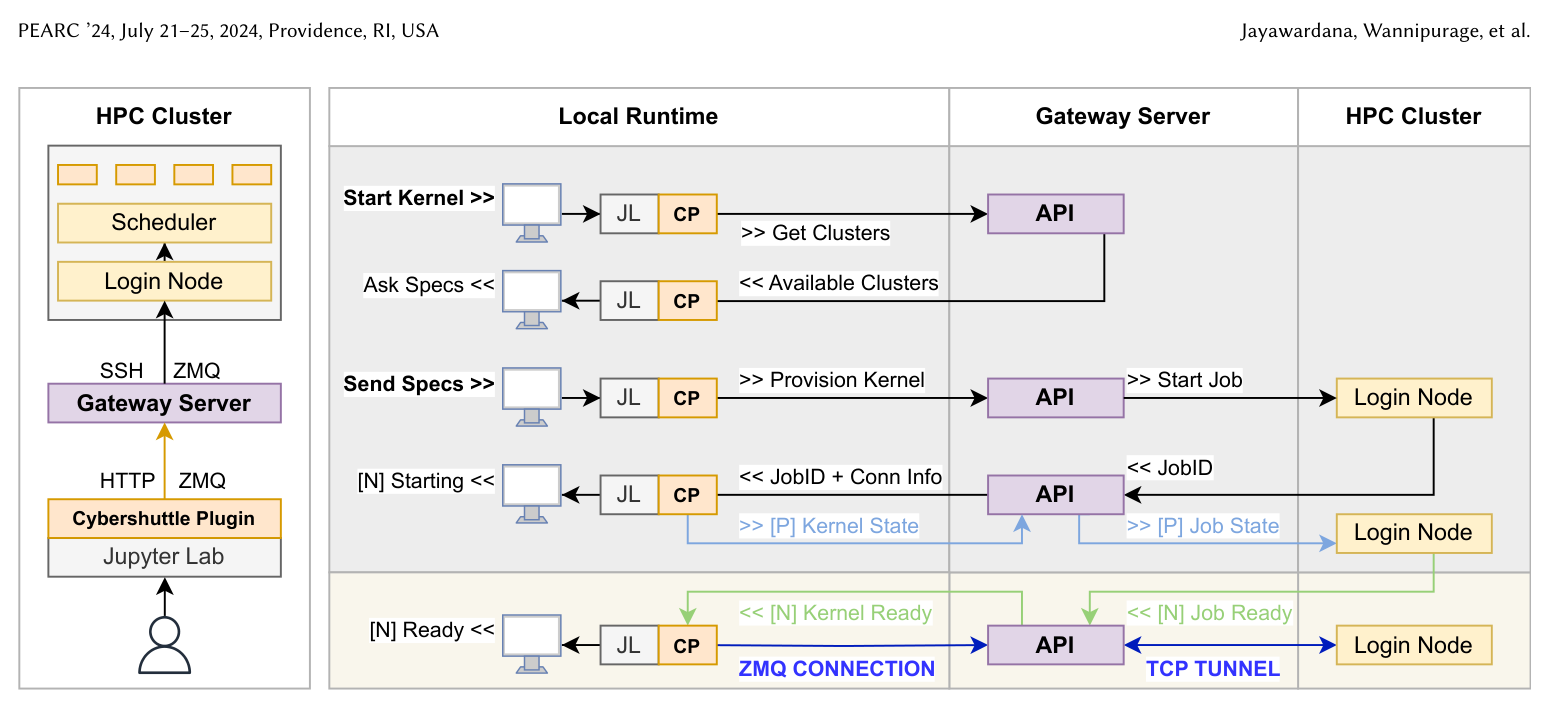
Figure 1: 左=システムの俯瞰。ローカルの JupyterLab(JL)+ Cybershuttle Plugin(CP)が、HTTP/ZMQ で Gateway Server につながり、Gateway は SSH/ZMQ で HPC クラスタの Login Node→Scheduler→計算ノードへ。右=カーネル供給(provisioning)の通信シーケンス。Start Kernel → Get Clusters → Available Clusters → Ask/Send Specs → Provision Kernel → Start Job → JobID → JobID+Conn Info、と進み、最後に TCP TUNNEL 上の ZMQ CONNECTION でローカルとカーネルが直結し [N] Kernel Ready になる。[P] はポーリング、[N] は通知を表す。
提案手法(アーキテクチャ)
システムは 2 つの主要コンポーネントから成る(Figure 1 左)。両者は Apache Airavata 上に構築された Cybershuttle Research Environment の一部で、Apache Airavata 2.0 のリリースでオープンソース公開される予定。
Cybershuttle Gateway Server(仲介サーバ)
HPC クラスタのワーカーノード上にカーネルを spawn し、そのカーネルが開く ZMQ ポートを、Gateway の IP 上で SSH 越しにプロキシするのが中心機能。
- なぜ効くか:このプロキシにより、ユーザはどのクラスタを使っていても一貫した IP アドレスでリモートカーネルに接続できる。クラスタごとのネットワーク事情を Jupyter 側に露出させない。
- 新クラスタの追加は、クラスタ固有の SSH 接続パラメータを設定ファイルで与えるだけ。ユーザ固有のクラスタアクセス設定もここで組める。
Cybershuttle JupyterLab Plugin
連携する 3 つのコンポーネントで「シームレスな体験」を作る。
-
Cybershuttle Kernel Provisioner:Jupyter Client(>7.0)の
KernelProvisionerBaseクラスを継承してカスタムの kernel provisioner を JupyterLab エコシステムに差し込む Python パッケージ。Jupyter は本来このクラスでカーネルのライフタイム(runtime 環境)を第三者が管理できるように設計されている。本実装では、ライフサイクル管理を Gateway Server に委譲し、ライフサイクルイベントを HTTP リクエストで起動する。 -
Connection Plugin:ユーザがこのシステムへ入る入り口。ローカルのノートブックを HPC クラスタのカーネル上で実行できるようにする。JupyterLab の UI に 2 つのワークフローを足す:(a) 新規ノートブックをリモートカーネルにつないで開始、(b) 既存ノートブックをリモートカーネルに接続。どちらでも、メモリ上限・wall time・CPU/GPU 数・カーネル言語などの runtime パラメータを UI から指定でき、通常のローカルカーネルを起動するのと同じ操作感でリモートカーネルを起動できる。裏では Kernel Provisioner を使って HPC 上にカーネルを spawn し、ZeroMQ で接続を張る。JupyterLab 7.0 以上と互換。
-
Management Plugin:Gateway Server に対するユーザ認証と、ローカル⇄HPC のデータ移動を担当する。
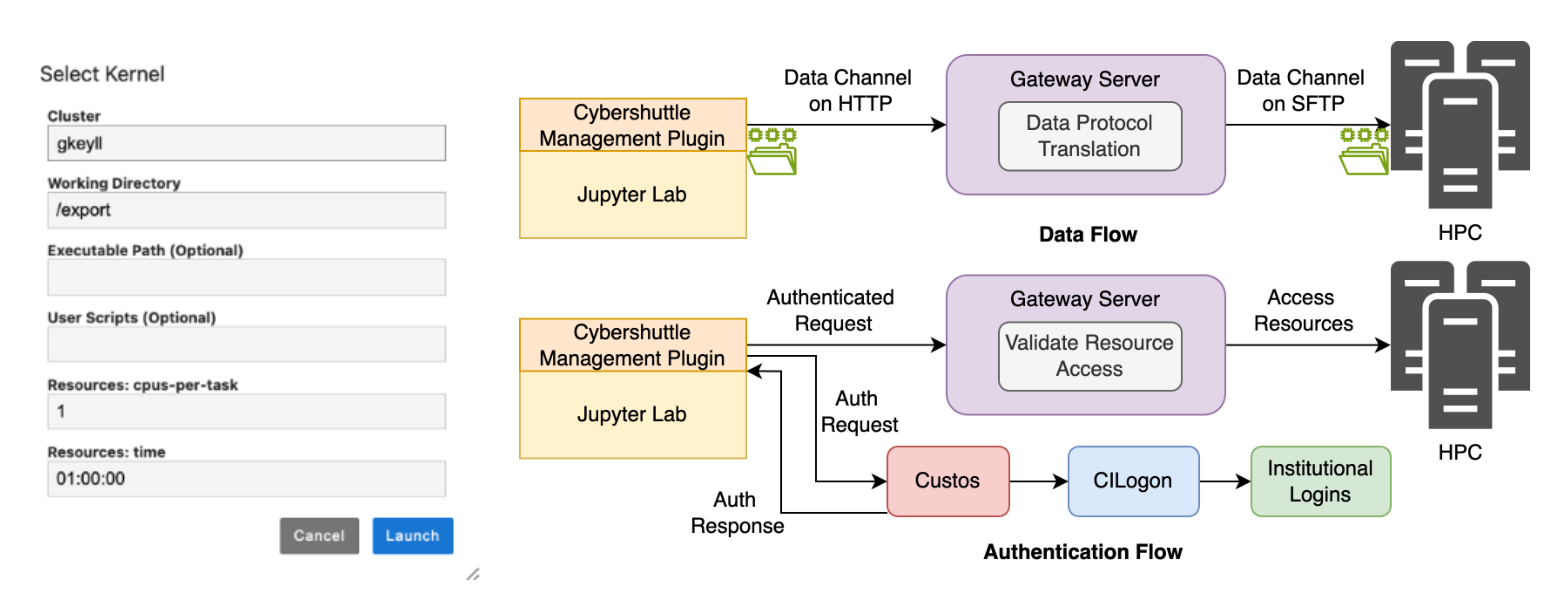
Figure 2: 左=Connection Plugin のカーネル選択 UI(Cluster・Working Directory・Executable Path・cpus-per-task・time などを指定して Launch)。右=Management Plugin の 2 つのフロー。上の Data Flow は、ローカル⇄Gateway を HTTP、Gateway⇄HPC を SFTP でつなぎ、Gateway 内の “Data Protocol Translation” がプロトコル変換のブローカになる。下の Authentication Flow は、Auth Request が Custos→CILogon→所属機関ログインへ流れ、Gateway が “Validate Resource Access” で資源アクセスを検証する。
認証・認可
Gateway は、ローカルのノートブック環境と HPC エンドポイントの間にユーザセッションを確立する仲介者。ユーザは CILogon 経由で所属機関の ID 管理基盤にアクセスして認証し、その際 Gateway に統合された Custos セキュリティミドルウェアを使う(Figure 2)。認証が成功すると、Gateway はあらかじめ定めた sharing schema に従ってユーザに HPC 資源へのアクセス権を割り当てる。
ファイルアクセス/同期
runtime 環境を移るときの効率的なデータ移動のため、Gateway はデータ移動のプロトコル変換を担うプロキシとして働く。データ転送時、
- ローカルの Jupyter plugin が ローカルファイルシステム⇄Gateway 間に HTTP のファイル転送チャネルを張り、
- 同時に Gateway が Gateway⇄HPC ファイルシステム間に SFTP チャネルを張る。
- 両接続が確立すると、Gateway がブローカとなって 2 チャネル間のバイト変換(byte translation)をシームレスに仲介する(Figure 2)。
なお HPC 側には標準の Jupyter Kernel 以外、追加サービスのインストールは不要。HPC⇄Gateway 間の通信は標準の SSH トンネリングで行い、追加サービス導入の必要を最小化している。本論文の主要な貢献は、この Gateway を「Web API 越しに複数の HPC クラスタにアクセスするプロキシ」として位置づけた点だと述べている。
評価
性能とスケーラビリティを、計算ワークロードの様々な側面で測定。具体的には、ユーザ負荷を変えながらエンドツーエンドのレイテンシと計算オーバーヘッドを測る。
- 負荷モデル:実運用の API 使用を模して、N ユーザが同時に N カーネルを動かす設定とし、セル実行頻度をパラメータ
λのポアソン過程でモデル化:Pr(x=k; λ) = λ^k · e^(−λ) / k!(式 1)。 - 時間の分解:1 つのセルを
M回独立に実行し、各実行で 2 つの時間{T_E, T_C}を記録。T_E=セル実行時間、T_C=計算時間、T_O=オーバーヘッド時間とし、T_E = T_C + T_O、したがってT_O = T_E − T_C(式 2)。 - 注目量:本研究が見るのはオーバーヘッド
T_O=セルがリクエスト/レスポンスのためにネットワーク上で費やす時間。これはセル出力サイズで変わる(例:セルが 8 文字を print すれば、HPC→ローカルへ 8 バイトを送る)。M回のT_Oの平均と標準偏差を、様々なNについて計算。比較のためローカル runtime 上でμ[T_O]・σ[T_O]をベースラインとして求める。 - さらにユーザ活動量
λを変えた場合も調べる。具体的には 50 人のバックグラウンドユーザが、それぞれ毎秒 0.5 / 1.0 / 2.0 回のポアソン分布レートでセルを実行するシナリオを模擬。 - 実験環境:すべて Jetstream 2 の SLURM クラスタ(ワーカーノード 8 台、各 8 コア・30GB RAM)で実施。ローカル runtime は Apple M2 MacBook Pro(16GB RAM)。
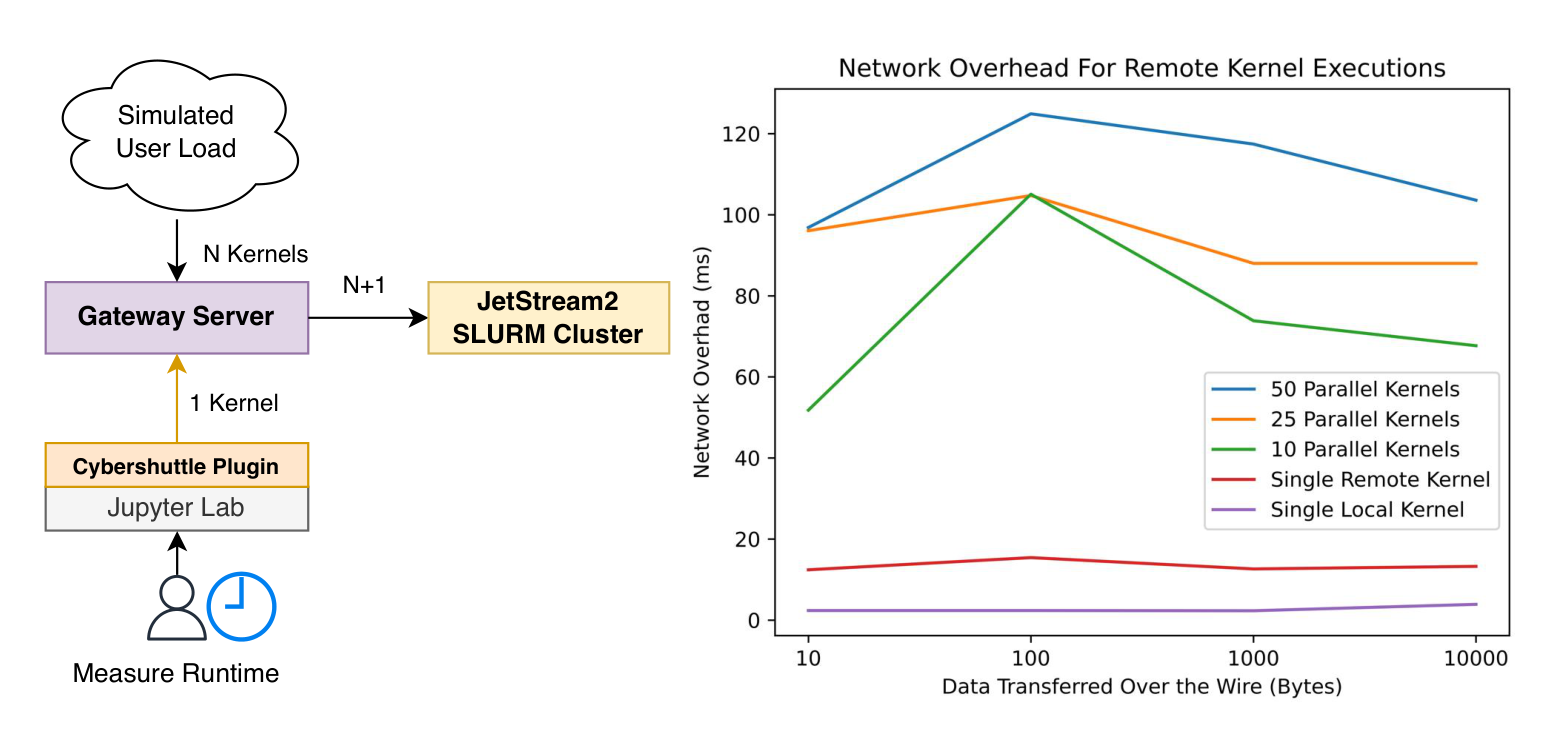
Figure 3: 左=ベンチマーク構成。Simulated User Load から Gateway Server へ N カーネル、ローカルの Cybershuttle Plugin から 1 カーネル(計 N+1)を Jetstream2 SLURM Cluster につなぎ、同一 HPC エンドポイントに対し並列カーネルで Runtime を測る。右=セル実行時の中央ネットワークオーバーヘッド(ms)を標準出力サイズ別に示す。50/25/10 並列カーネルは 100 バイト付近を山に 70〜130ms 程度、Single Remote Kernel は十数 ms 前後、Single Local Kernel はほぼ 0。
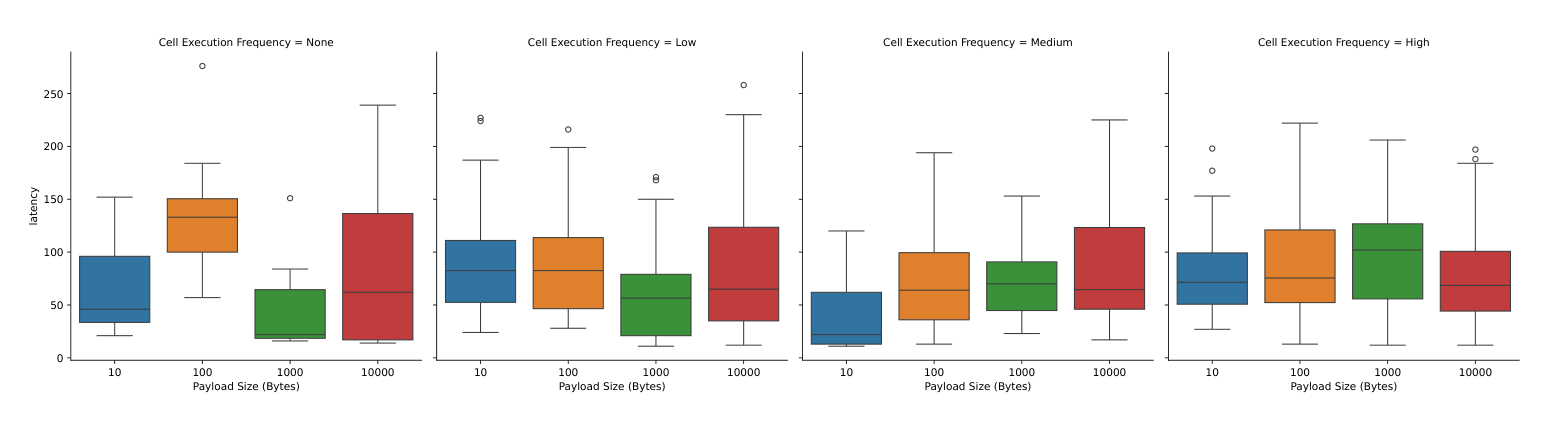
Figure 4: バックグラウンドユーザのセル実行頻度を None→Low→Medium→High と上げたときのネットワークオーバーヘッド分布(左から右)。全テストで 50 人の模擬ユーザ、各箱ひげは 50 回の独立試行の分布。ペイロードサイズ(10〜10000 バイト)を変えても、レイテンシは概ね 200ms 未満に収まり、頻度を上げても分布は大きくは崩れない。
結果:
- 最悪ケースでも、ローカル runtime と比べてセル実行あたりのネットワークオーバーヘッドは 200 ms 未満。スケーラブルな性質を示した。
- 高 IO 負荷下でも応答性を維持し、ユーザ体験に資する。
- 興味深い観察として、セル出力のペイロードサイズはネットワークオーバーヘッドを「最小化」する方向に働く(出力サイズが現代のネットワークバッファ容量に比べて相対的に小さいため)。
- ただし 10KB を超える水準はテストできなかった。JupyterLab がローカル/リモートとも、それ以上の大きな出力 print をサポートしなかったため(評価の限界)。
関連研究との関係(メモ)
- DESY notebooks(
reppin2021interactive)/Cori/NERSC(thomas2021cori):「HPC 上でノートブックを動かす」系。本論文は対比として、Open OnDemand 等の「リモートに Jupyter を立てる」発想に対し、ローカルの JupyterLab に居たまま UI からリモートカーネルへ scale-out する点を差分として強調している。 - Absolute State フレームワーク(
wannipurage2022absolutestate):同じ Apache Airavata/Cybershuttle 系の研究グループ(著者 Wannipurage が共通)。 - Jupyter の品質・再現性の大規模調査(
pimentel2019largescale):本論文は参考文献 [10,11] として、JupyterLab が科学コミュニティで広く使われている根拠の 1 つに引いている。 - 構成要素として Apache Airavata(分散アプリ/計算ワークフロー基盤)、Custos(サイエンスゲートウェイ向けセキュリティミドルウェア)、CILogon(連合 ID)に依存。
Q&A
(自分がAIに実際に質問したことだけを Q/A 形式で残す。まだなし。)
自分のコメント
(ここは自分で都度書く欄。例:手元の JupyterLab から HPC カーネルへ繋ぐ機構(ZMQ ポートの SSH プロキシ+カスタム KernelProvisioner)を、自分の移行シナリオに流用できるか確かめたい。)