AI解説
情報源:arXiv HTML 全文(https://arxiv.org/html/2504.12365v1)を精読。本文・図(Figure 1, 2)・表(Table 1〜3)・Appendix の見出しまで読んだ範囲で記述する。著者・所属は本文記載のとおり Konstantin Grotov・Sergey Titov(JetBrains Research)。 ベンチマークデータ: https://zenodo.org/records/14861889(本文記載)。プロジェクトページ(themisto-benchmark.github.io)は本文に記載が無いため AI解説では参照しない。
一言で
Jupyter ノートブックの開発トラジェクトリ(人が実際にセルを実行していった順序+各実行時のランタイム状態)を素材にして、LLM がランタイム情報(変数・メモリ・出力など実行時の文脈)をどれだけ予測に活かせるかを測るベンチマーク Themisto。タスクは「次に実行されるセルのコード予測」と「あるセルの出力予測」の2つ。現行の主要 LLM(GPT-4o / GPT-4o-mini / Claude 3.5 Sonnet / Gemini 1.5 Pro / DeepSeek-V3)はいずれも低スコアで、しかもランタイム情報を入力に足してもスコアがほとんど上がらない(Claude-3.5 はむしろ半減)。著者は「コードモデルにランタイム文脈を取り込む領域は未開拓で、大きな伸びしろがある」と主張する。
背景・問題
近年のコード生成・補完は、単純なプログラム生成(Chen et al., 2021)からリポジトリ規模の実問題解決(SWE-bench 系, Jimenez et al., 2023)へと進んできた。しかしほとんどの研究はコードの静的スナップショットに基づいており、ランタイム情報やメモリ状態といった動的な性質を活用する研究はごくわずかしかない。
著者が指摘する根本の問題は、「ふつうのプログラミング環境では、実行中にコードを生成する場面がほとんど無い」点にある。ランタイム情報が集まるのは実行している最中なのに、その最中にコードを書く状況がそもそも生じにくい。だから「実行時の値・状態を使ってコードを生成・理解する」能力を測る土台が乏しい。
ここで Jupyter ノートブックが固有のチャンスを持つ。ノートブックはセルを実行しながらコードを書き足していく環境であり、コード生成とランタイム情報・環境の現在状態への参照が同時に成立する。著者はこの性質を使って「LLM はランタイム文脈を活かせているか?」を測ろうとする。
用語の整理:ここでの 問題(problem) は「LLM が実行時の値・メモリ・出力といったランタイム状態をコード予測に活かせているかが、測る土台すら無く未解明(そして現状活かせていない)」こと。課題(task=著者がやること) は「ノートブックの開発トラジェクトリを使い、それを測るベンチマーク Themisto を構築し、主要 LLM のベースラインを出すこと」。
ベンチマークの構成
Themisto は Jupyter ノートブックの開発トラジェクトリの集合から成る。
- 開発トラジェクトリ(development trajectory) とは、人間の開発者が実行した順序どおりに並んだセル実行の列。各操作(ステップ)は、そのセルの内容と実行後のランタイム状態を含む。
- 各トラジェクトリは「対象セル実行までのすべての先行セル実行+その実行コンテキスト(セル内容やランタイムスナップショット)」で構成される。実行順序は元データセットの作者が開発過程を記録したもので、Themisto でもその順序を保持する。
- オプションで、そのノートブックがもともと何のタスク用に作られたかの初期タスク説明を各トラジェクトリに付けられる。
このトラジェクトリを与えた上で、「次に実行されるコード」と「そのセルが生む出力」を予測させる。

Figure 1: 出力予測タスク(左)と次セル予測タスク(右)のトラジェクトリ対のサンプル。灰色・白の行はトラジェクトリの内容(セル内容とセル出力)を表し、緑が予測対象のエンティティ。左ではあるセルの出力(Out[1]: の値)が、右では次に実行されるセル(Cell to predict)が予測対象になっている。
タスク定義と評価指標
選んだタスクは2つ。
- 次セル予測(Next cell prediction):トラジェクトリ中で次に実行されるセルのコードを予測させる。「次に何をすべきか」を決めるには、これまでのトラジェクトリを相当深く理解している必要があり、コード生成の中でも興味深い視点を与える。
- セル出力予測(Cell output prediction):出力を持つ種類のセルについて、その出力テキストを予測させる。デフォルトのスナップショット設定では、コードの強い理解とランタイム挙動のモデリングが要るため LLM には難しい(Gu et al., 2024)。著者は「ランタイム情報を与えればスコアが上がるはず」と仮説を立てる。このタスクはコードモデリング能力とランタイム文脈の活用能力の両方を映すと位置づける。
評価指標は、Evtikhiev et al.(2023)の推奨に沿って次の3つ(いずれも高いほど良い)。
- Exact Match:完全一致(2値)。
- ROUGE-L:最長共通部分列ベースの F1(Lin, 2004)。
- ChrF:文字 n-gram の F スコア(Popović, 2015)。
データ収集(JuNE データセット → トラジェクトリ)
元データは JuNE データセット(Titov et al., 2025)。著者ら(元論文側)は8時間超にわたり少人数の参加者のノートブック開発過程を追跡し、14,000 件超のユーザイベント(うち 9,000 件超のセル実行)を、29 ノートブック・2つの元タスクにわたって収集した。Kaggle 由来のようにより多くのノートブックを持つデータセットもあるが、JuNE は最終版だけでなく中間状態やデバッグの過程まで含み、「モデルが開発者を支援すべき最も重要な段階」の情報が豊かだ、というのが選定理由。
Themisto はそこから4ノートブックを環境再現して再実行し、合計 1,453 件のコード実行を得た。再実行時に、各ステップについてメモリ負荷・実行時間などの追加情報を計測し、環境の状態をシリアライズしてトラジェクトリに組み込んだ。利用できるコンテキスト特徴は Table 1 のとおり。
各トラジェクトリのステップが持つ特徴(Table 1):
kernel_id:実行カーネルの一意識別子。code:そのセルで実行されたコード。output:実行コードが生んだ出力。execution_time:実行にかかった時間(秒)。memory_bytes:実行中のメモリ使用量(バイト)。runtime_variables:実行環境内のランタイム変数の辞書。各変数について名前・バイトサイズ・repr表現を保存する。hash_index:実行状態を表す一意ハッシュ。
こうして、データセット内の各セル実行について「それ以前の開発の完全なトラジェクトリ」が得られる。
予測対象セル/出力の選定とサンプリング:
- トラジェクトリ中に5つ以上のアクションを持つセルをすべて選ぶ。
- タスクごとに、空の例と極端に長い例(セル長・出力長分布の 0.99 分位を超えるもの)を除外。
- 多様性確保のため 200 例を以下の層化抽出で選ぶ:まず出力長分布の第2・第3四分位から 180 例をランダム抽出、次に第4四分位(長い)から 10 例、第1四分位(短い)から 10 例を加える。
- 例外(exception)を含む予測対象は除外。基盤モデルはスタックトレースを苦手とするため(Gehring et al., 2024)。
ベースライン(評価設定)
ベースラインとして主要 LLM 5種を選定:GPT-4o(Hurst et al., 2024)、GPT-4o-mini(同)、Claude 3.5 Sonnet(Anthropic, 2024)、Gemini 1.5 Pro(Team et al., 2024)、DeepSeek-V3(Liu et al., 2024)。
- 2つの設定で報告する:推論時にランタイム情報を使う(Runtime)設定と、使わない(No Runtime)設定。これがこのベンチマークの肝で、「ランタイム情報を足すと予測が良くなるか」を直接見る。
- モデル出力には後処理を施す:セルの言語識別子(コードフェンスのタグ)の除去、冗長な空白・タブのトリム。後処理なしの結果は Appendix A.3(Table 3)に別掲。
- 推論セットアップの詳細は Appendix A.2。プロンプトは、出力予測では「Python REPL インタプリタとして振る舞う」よう、次セル予測では「熟練 Python プログラマとして振る舞う」よう指示し、言語識別子タグの付与を明示的に禁じている(本文・Appendix 記載)。
評価結果
Table 2 が両タスクの結果(後処理あり)。No Runtime / Runtime の2ブロックで、各指標(Exact Match / ROUGE-L / ChrF)を並べている。
出力予測(Output Prediction)
| Model | EM (No RT) | ROUGE-L | ChrF | EM (RT) | ROUGE-L | ChrF |
|---|---|---|---|---|---|---|
| GPT-4o | 0.16 | 0.32 | 0.47 | 0.16 | 0.34 | 0.46 |
| GPT-4o-mini | 0.16 | 0.31 | 0.43 | 0.15 | 0.30 | 0.43 |
| Claude-3.5 | 0.18 | 0.38 | 0.50 | 0.09 | 0.34 | 0.48 |
| Gemini Pro | 0.17 | 0.35 | 0.54 | 0.16 | 0.35 | 0.55 |
| DeepSeek-V3 | 0.18 | 0.35 | 0.49 | 0.19 | 0.33 | 0.48 |
次セル予測(Next Cell Prediction)
| Model | EM (No RT) | ROUGE-L | ChrF | EM (RT) | ROUGE-L | ChrF |
|---|---|---|---|---|---|---|
| GPT-4o | 0.10 | 0.28 | 0.39 | 0.10 | 0.26 | 0.37 |
| GPT-4o-mini | 0.06 | 0.25 | 0.38 | 0.07 | 0.27 | 0.36 |
| Claude-3.5 | 0.12 | 0.30 | 0.42 | 0.11 | 0.30 | 0.42 |
| Gemini Pro | 0.12 | 0.34 | 0.43 | 0.13 | 0.33 | 0.42 |
| DeepSeek-V3 | 0.13 | 0.34 | 0.46 | 0.14 | 0.35 | 0.47 |
読み取り:
- 出力予測:ランタイム情報なしでも全モデルが相当数の完全一致を出せた。最良は Claude-3.5 の 18%(EM)。他モデルも非常に近い値で、タスクの難しさはモデル間で同程度(ただし正解できた例の集合はモデルごとに異なる)。ROUGE-L・ChrF はもっと高く、完全一致でなくても原文に近い出力は出せている。
- ランタイム情報を足しても、スコアはほぼ変わらない。例外は Claude-3.5 で、EM が 0.18 → 0.09 と半減。これは「モデルがまだランタイム文脈を有効に活用できていない」ことを示し、ポストトレーニングで伸ばす余地が大きい、と結論づける。
- 次セル予測:全モデルとも特に Exact Match で総じて低調。最良は DeepSeek-V3 の 13%(EM)。これも ROUGE-L・ChrF はより高く、「次セルに関連した出力は出せている」。著者は、極めてオープンエンドなタスクで非常に具体的なデータ点を当てさせている割に、一部では実際の次の操作を正しく当てられた点を有意とみなす。
- 総括として、「手元のランタイム情報を全部そのままコンテキストに足しても性能は上がらない。情報は丁寧に取捨選択(curate)する必要がある」と述べる。情報自体は予測・状態理解に価値があるが、どう実装するかは研究コミュニティへの問いだとする。
サンプルの多様性(Appendix A.1)
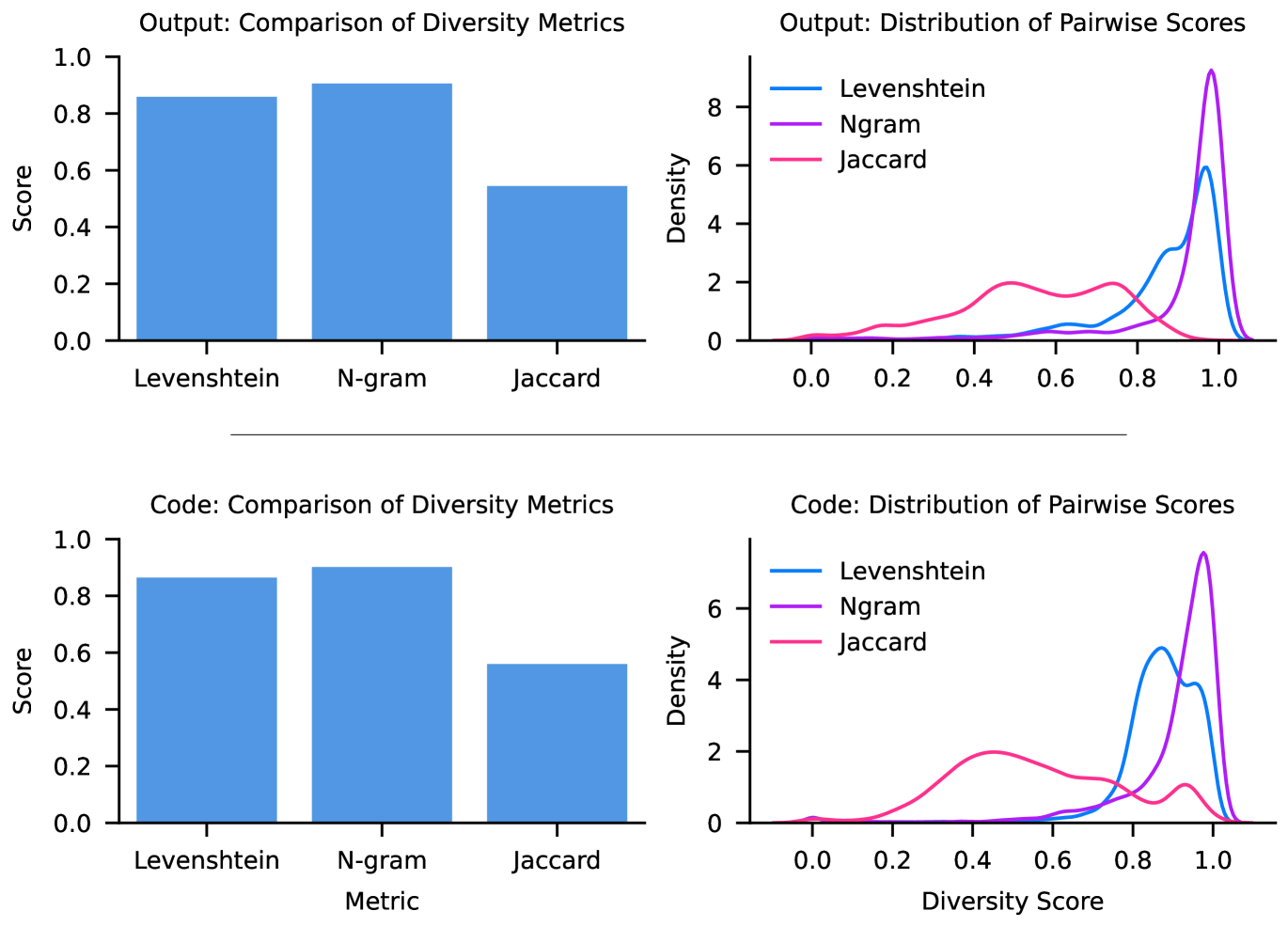
Figure 2: 出力(上段)とコード(下段)について、多様性指標の比較。左は Levenshtein・N-gram・Jaccard の各スコアの比較(棒グラフ)、右はペアワイズスコアの分布(密度)。ベンチマークに採られた出力・コードがどの程度多様かを示し、N-gram と Levenshtein では高い多様性、Jaccard では相対的に低い値を示している。
関連研究との関係
著者が挙げる近接研究は、コード実行のシミュレーション能力を測る2つのベンチマーク:
- CruxEval(Gu et al., 2024):コード・入力・出力の三つ組を与え、残り1つを予測させる。chain-of-thought 設定が有効で、推論が実行過程モデリングの鍵になると示した。
- REval(Chen et al., 2024):CruxEval にランタイムデータを加え、プログラム状態予測・実行経路予測などの新タスクを導入。モデル間で推論能力が大きく異なり、実行経路予測では最強の GPT-4-Turbo でも精度 57.7% にとどまると示した。
また、学習過程でランタイム情報を取り込む試み(Ding et al., 2024 の TRACED など)にも触れる。TRACED はランタイム情報の付加が実行状態予測やバグ位置特定を改善しうると示す一方、コンパイラフィードバックへの応答は弱い(Gehring et al., 2024 ほか)という報告もある。Themisto はこれらと違い、完全な開発トラジェクトリという動的モダリティを持ち込み、静的スナップショットを超えてランタイム情報と開発の進行を同時にモデルへ渡す点に新規性を置く。
このリポジトリ内では、JuNE データセットの提供元である Titov et al., 2025(JuNE)(zhang2019juneau とは別物)と、ノートブック実行・状態管理を扱う既存ノート(ElasticNotebook 等)が文脈的に近い。
限界と今後(Threat to validity and Conclusion)
- 主な問題は多様性の低さ(low variability)。元データは2タスク・20名の参加者のみで、Themisto はさらにそのサブサンプルを使う。そのためノートブックトラジェクトリの空間が著しく過小に代表されており、「ランタイム文脈を扱う手法の一般化可能性」について結論を出しにくい。
- 解決の方向:コミュニティの関心があれば、元の JuNE のツールを使って追加タスク向けのデータを増やせる。
- 位置づけ:本ベンチマークはコード生成・プログラム解析に新しい動的モダリティを導入し、静的スナップショットを超えて完全な開発トラジェクトリをモデルに利用させることで、開発者のワークフローや期待によりよく整合させうる、とまとめる。
注(本文の表参照の食い違い):2.3 節の本文は「Table 3 に2タスクの結果を示す」と書いているが、実際の結果表は Table 2(後処理あり)で、Table 3 は Appendix A.3 の後処理なしの結果。上の数値は Table 2(後処理あり)に基づく。
Q&A
(まだなし)
自分のコメント
(まだなし)