AI解説
情報源:arXiv 全文(ar5iv HTML 版
arxiv.org/abs/2311.12308)を精読。 原文:https://arxiv.org/abs/2311.12308 著者:Jinli Duan, Dennis Shasha(NYU Tandon)。 注意:本論文は設計提案(システムアーキテクチャの記述)が中心で、実験・評価・ベンチマークの節を持たない。本文に無い数値・アルゴリズム詳細は補わず、「論文に書かれていない」と明記する。
一言で
1 本の Jupyter Notebook パイプラインを、「依存込みで分割 → 各部を Docker 化 → Kubernetes 上に Pod として分散デプロイ」へ自動変換し、K8s ネイティブ機能(ReplicaSet・liveness/readiness probe・rolling update・Horizontal Pod Autoscaler)で耐障害性を持たせるシステム Jup2Kub の提案。依存捕捉に ReproZip、ノートブック分割に nbmanips、Pod 間通信に Kafka を使う。ただし本論文は設計の記述にとどまり、定量評価は行っていない。
背景・問題
論文は、科学研究の再現性を阻む要因(コードが共有されない・計算環境の詳細が欠ける・実験手順が十分に報告されない)を出発点に置く。Jupyter Notebook はコード・文章・可視化・メディアを 1 つの共有可能な文書(”one study – one document”)にまとめ、これを大きく改善した。しかし論文は Notebook の問題として次を挙げる。
- スケールしない:データ量が増えると単一マシン実行では立ち行かない。
- 耐障害性が無い:インフラ障害に対して脆い。
- 依存変化に脆い(brittle):下層のツール・パッケージが変わると壊れる。
- モジュール性の欠如:セルに直接コードを書く線形構造が、大規模開発に要るモジュール化を妨げる。コードと依存・データが「ノートブックの流れの中で密に混在」してしまう。
- 利用者の専門性ギャップ:多くの領域科学者は計算機科学の専門家ではなく、結果としてコード品質・作法が最適でないノートブックになりがち。
→ そこで論文は「より高い耐障害性と堅牢なエラー処理、そしてモジュール性を備えた、より進んだソフトウェア開発フレームワーク」が必要だと主張し、それを Notebook → Kubernetes への自動変換という形で実現しようとする(これが本研究の課題=やること)。
提案手法:Jup2Kub のアーキテクチャ
システムは大きく (1) ノートブックの分割と Docker 化 → (2) 動的な Pod デプロイ → (3) ストレージ → (4) プロセス間通信 → (5) 耐障害性管理 で構成される。全体像は下図 1 が示す。
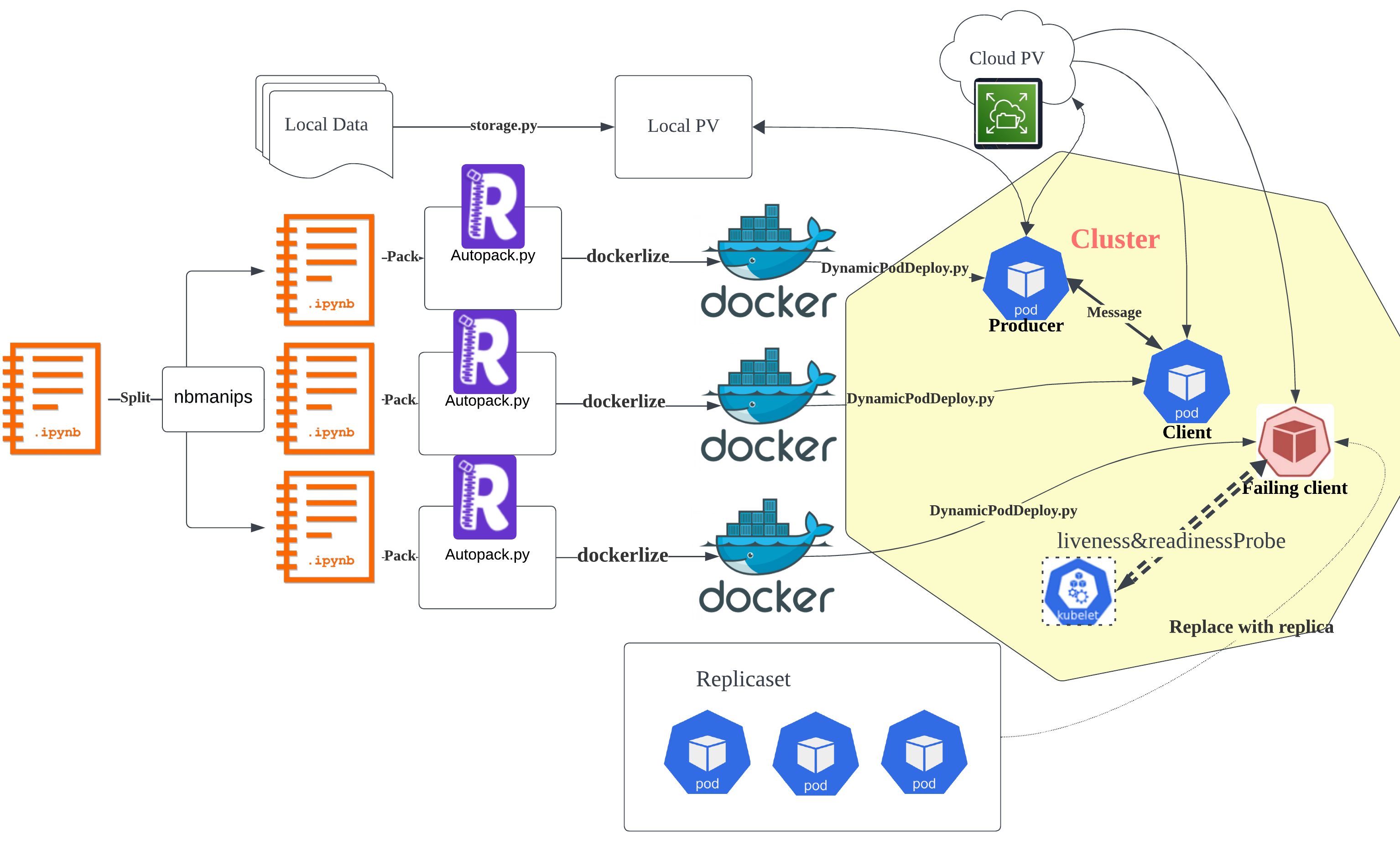
Figure 1(原文 “Flowchart”):左端の 1.ipynb(元のノートブック)を nbmanips で複数のノートブック(1.ipynb・2.ipynb・3.ipynb)に分割し、各々を ReproZip(Autopack.py)で依存ごと梱包 → dockerlize(Docker 化)→ DynamicPodDeploy.py で Kubernetes クラスタ(右の黄色い領域)へ Pod として配備する。ストレージは storage.py 経由のローカル PV と Cloud PV。クラスタ内では Producer Pod → Message → Client Pod とデータが流れ、liveness&readinessProbe で落ちた Pod(Failing client)を ReplicaSet の複製で置き換える。下段の Replicaset は 3 つの Pod 複製を表す。
3.1 分割と Docker 化(Split and Dockerize)
3 段階で進む。
- 依存の捕捉:ReproZip がノートブック実行中のシステムコールをトレースし、必要なファイル・依存をすべて特定して
config.ymlに書き出す。 - ノートブックの分割:nbmanips ライブラリを使い、ワークフロー上の論理的な区切り(”piped sections”)でノートブックを分割する。※ 分割の形式的アルゴリズムや、ノートブックを DAG として表す記述は論文に無い。
- 個別梱包とコンテナ化:分割した各ノートブックを ReproZip の pack コマンドで梱包する(依存は最初に捕捉したリストから差し替える)。各パッケージを unpack して個別の Docker コンテナにする。
論文はこれで「ノートブックの効果的な分割とコンテナ化を達成する」と述べるが、アルゴリズム的な詳細は与えていない。
3.2 動的な Pod デプロイ(Dynamic Pod Deployment)
- PodManager クラス:各 Pod のメタデータ(producer か consumer か、対応する Kafka トピック)を保持する。
- K8s 設定の読み込み:
config.load_kube_config()で Kubernetes 設定をロードする。 - DynamicPodDeployer クラス:PodManager の Pod 群を順に走査し、各 Pod の役割に応じてデプロイ設定(環境変数など)を生成・適用して Kubernetes に配備する。
デプロイのテンプレートは Listing 1(Kubernetes pod Deployment template) に YAML として示され、次を指定する:replicas: 3(3 つのバックアップ複製)、strategy.type: RollingUpdate(maxUnavailable: 1, maxSurge: 1)、リソース上限(CPU 1 / Memory 1Gi)と要求(CPU 500m / Memory 500Mi)、/healthz・/readiness(ポート 8080)への liveness / readiness probe、永続ストレージ(EFS)のボリュームマウント。
3.3 ストレージ
- ローカルストレージ:node affinity を持つ Persistent Volume(PV) を特定ノードに束ねて低レイテンシ参照を得る。
- クラウドストレージ:AWS EBS / EFS 向けに PV・PVC を構成し、ノード間で共有・スケール可能なストレージにする。
論文は「多層ストレージがワークロードに適応する」と述べるが、具体的な実装・データ構造・アルゴリズムは示していない。
3.4 プロセス間通信(Interprocess communication)
Pod 間は Kafka の producer / consumer で連携する(トピックの具体的な設定や producer/consumer セマンティクスの実装詳細は論文に無い)。補助的に 2 つの関数が説明される:
get_cluster_ip(service_name, namespace):subprocessで kubectl を実行し、指定サービスの cluster IP を返す。communicate_with_service(service_name, namespace):得た cluster IP で URL を組み立て、requestsで HTTP GET し、応答テキスト(失敗時は None)を返す。
3.5 耐障害性の管理(Fault Tolerance Management)
論文は耐障害性の手段を 6 つ列挙する。いずれも Kubernetes のネイティブ機能の利用であり、チェックポイント/リスタートや状態復元、障害検知のしきい値といった独自アルゴリズムは記述していない。
- ReplicaSet:Pod 複製を 3 つ維持して冗長化する。
- リソース上限:CPU・メモリ制約で資源利用を最適化する。
- liveness / readiness probe:Pod の健全性を監視し、応答しない Pod を複製で置き換える。
- rolling update:
maxSurge/maxUnavailableで更新中もサービスを継続する。 - Horizontal Pod Autoscaler:ワークロードに応じて CPU・GPU 資源を動的調整する(スケーリングのしきい値・指標は明示されない)。
- エラー処理とロギング:監視・トラブルシュート用に追跡する(具体的なロギング戦略の記述は無い)。
関連研究(論文が挙げるもの)
論文の Related Work は次の 3 つを取り上げる:ReproZip(依存トレースと再現パッケージング。本システムの土台)、Kubernetes(コンテナオーケストレーション基盤)、Pegasus(科学ワークフロー管理システム)。Jup2Kub は「既存ワークフローシステム(Pegasus 等)」と「Notebook の手軽さ」の橋渡しを、ReproZip + K8s で図るという立ち位置。
本リポジトリ内では、依存・ファイル捕捉という点で Absolute State フレームワーク(strace でファイル依存を言語非依存に拾う)と発想が近く、分散実行という点で Distributed workflows with Jupyter と並べて読める(系統だった対比は overview の分野マップに寄せる)。
実験・評価について
本論文には実験・評価・ベンチマーク・ケーススタディの節が存在しない(ワークロード/データセット、ベースライン、性能指標、障害復旧時間などの数値は一切報告されていない)。したがって、分割変換のオーバーヘッド、スケール性、耐障害性の実効性は本論文からは判断できない。設計提案として読むべき論文である。
まとめ(位置づけ)
Jup2Kub は「ノートブックを ReproZip で依存ごと固め、nbmanips で分割し、Docker 化して Kubernetes に Pod 分散配備、K8s ネイティブ機能で耐障害性を付ける」という変換パイプラインの設計を示す。タイトルは “algorithms and a system” を掲げるが、分割・スケジューリング・耐障害性の具体的アルゴリズムや定量評価は本文に乏しい点は、後で参照・批判する際に押さえておきたい。