AI解説
取得元: arXiv v1 PDF https://arxiv.org/pdf/2210.06893(HTML 版 v1〜v3 はいずれも 404 で存在せず、arXiv に登録があるのは v1 のみ) 情報源: 全文 PDF(26頁、本文+全図表)を精読して記述。図はHTML版が無いため PDF の該当ページをレンダリングして切り出した(6枚)。数値・割合・各 Finding・Table 1〜6 は本文で確認済み。 なお PDF のヘッダ/フッタには ACM テンプレートの placeholder(”Trovato and Tobin”、”Article 111”、”2018”)が残っているが、これはテンプレート未差し替えの痕跡で、本研究の正しい著者・年は frontmatter のとおり(2022, arXiv:2210.06893)。
一言で
Jupyter Notebook で実際に起きているバグを、GitHub のコミット・Stack Overflow の投稿・データサイエンティストへのインタビューの3つの証拠源から大規模に調べ、8カテゴリのバグ分類体系(taxonomy)と10種類の根本原因(root cause)、そしてバグの影響(impact)と現場の課題(challenges)を整理した実証研究。最頻バグは「環境・設定(Environments and Settings)」と「実装(Implementation)」で、両者で全体の6割超を占める。
背景・問題
Jupyter はデータ分析・可視化のデファクトになっているが、その利点(literate programming、自己文書化)の裏で「name-value inconsistency(変数名と値が食い違う)」「依存関係を明記しないノートブックが約94%」「messy / dirty / ad hoc なコード」といった品質上の批判が積み重なってきた。
ここでの問題(problem)は、「Jupyter の開発がどんなバグ・困難を抱えているのかが、実務者の視点から体系的に調べられていない」こと。Wang らのコーディング規約違反、Pimentel らの再現性(有効なノートブックでもエラーなく走ったのは 24.11% のみ)など個別の指摘はあったが、Jupyter プロジェクトのバグそのものを網羅的に特徴づけた研究は存在しなかった。一方、他ドメイン(深層学習、機械学習システム、自動運転、IaC スクリプト等)ではバグの実証研究が多数行われており、その空白を埋めるのが狙い。
本研究が掲げる課題(task)= やったことは、3段階のマイニング+質的調査で「Jupyter バグの分類体系・根本原因・影響・課題」を作り出すこと。著者らはこれを「Jupyter notebook プロジェクトのバグに関する初の包括的研究」と位置づける。
リサーチクエスチョン
- RQ1: どの種類のバグがより頻繁か?(バグの type を同定し taxonomy を作る第一歩)
- RQ2: バグの根本原因(root cause)は何か?(原因を理解すれば回避・修正・改善ができる)
- RQ3: バグの頻出する影響(impact)は何か?(深刻度の優先順位づけに使える)
- RQ4: 実務でデータサイエンティストはどんな課題(challenges)に直面するか?
手法(調査の設計=やったこと)
3つの証拠源を組み合わせる。全体像は Figure 1。
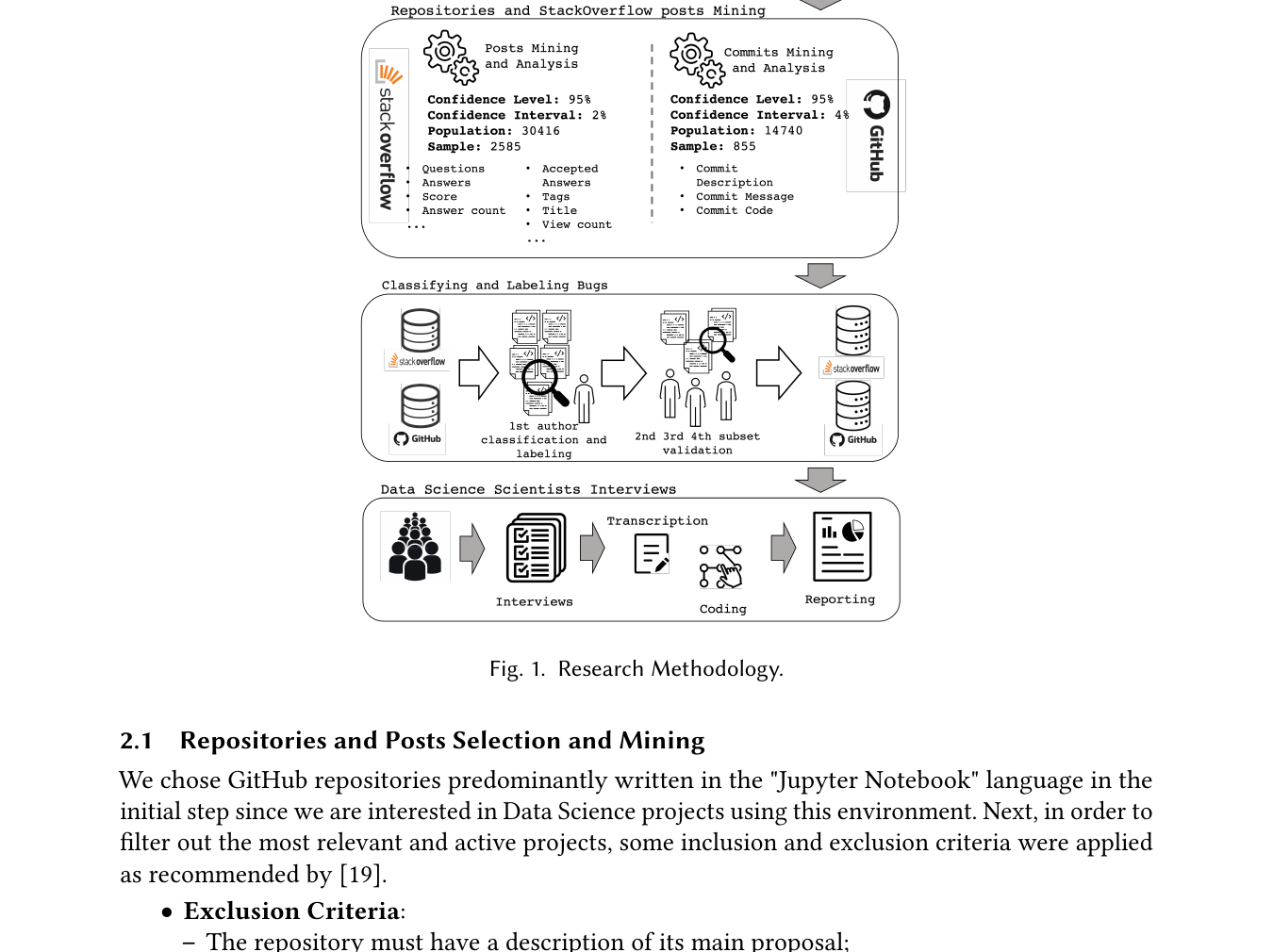
Figure 1. 研究方法。上から順に「リポジトリ/投稿の選定」→「コミット・投稿のマイニングと分析」→「バグの分類・ラベリング」→「データサイエンティストへのインタビュー(録音→転写→コーディング→報告)」の4段階。
-
GitHub リポジトリマイニング: 主言語が “Jupyter Notebook” のリポジトリ 11,010 件から、8つの包含/除外基準(英語、2020年に更新あり、2020年に24コミット以上=月2件以上、貢献者10名以上、
.ipynbのコミットメッセージにバグ修正系キーワード —fix/bug/error/defect/mistake/fault/correction等 — を含む 等)で絞り込み、上位105リポジトリ/14,740件の有効コミットを得た。 -
Stack Overflow 投稿分析:
Tags LIKE 'jupyter-notebook'のクエリで Stack Overflow API から取得し、30,416件の投稿を生データとした。タイトル・本文・コメント・accepted answer を分析。 -
バグの分類・ラベリング(オープンコーディング): 全コミット・投稿をスプレッドシート化し、bug type / root cause / impact を反復的に分類。飽和(新カテゴリが出なくなる状態)に達するまで行い、コミットは855件(誤差 <4%、信頼水準95%)、投稿は2,585件(誤差 <2%、信頼水準95%)を分析した時点で飽和。判断の信頼性を確認したのち、残りは第1著者が単独分類。さらに第2・3・4著者がランダムに 145コミット・137投稿を独立分類し、Cohen’s Kappa で評価したところ bug type >81%、root cause 95%、impact 95%(Landis & Koch の基準で “substantial agreement”)。
-
半構造化インタビュー: パイロット1名を除く19名のデータサイエンティスト(12社、金融・自動車・石油化学・鉱業・モバイルゲーム・大学等。40%が博士、25%が修士。経験1年以上、Table 1)に、18問のオープン質問で平均約43分。QDA Miner で転写・コーディングし、52コード・7カテゴリ・5課題にまとめた。
RQ1: バグの種類と頻度
最初に8カテゴリのバグ taxonomy(Figure 2)を作り、インタビューで検証・改良した。各カテゴリは Stack Overflow / GitHub での出現割合つき。
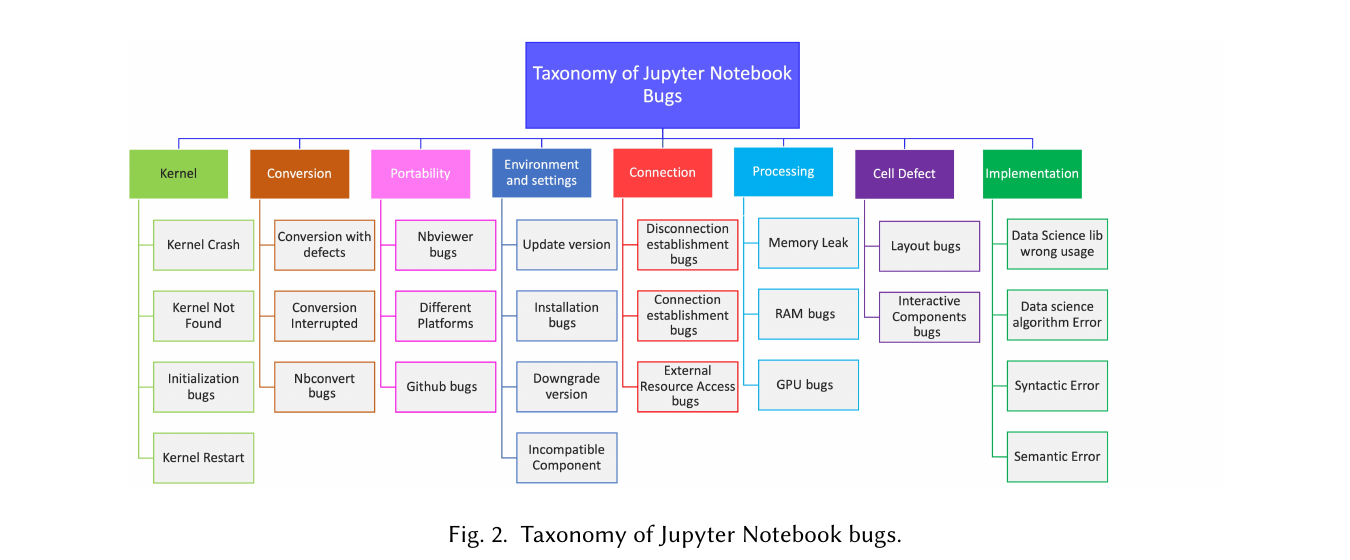
Figure 2. Jupyter Notebook バグの taxonomy。8カテゴリ(Kernel / Conversion / Portability / Environment and settings / Connection / Processing / Cell Defect / Implementation)と、それぞれのサブタイプ。
8カテゴリと割合(SO=Stack Overflow, GH=GitHub):
- Kernel (KN) — SO 10.8% / GH 2.9%。カーネル動作のバグ。Kernel Crash(突然落ちる), Kernel Not Found(カーネル未接続), Initialization Bugs(誤インストール・カーネル競合), Kernel Restart(勝手に再起動)。
- Conversion (CV) — SO 6.7% / GH 10.6%。
.ipynbから他形式への変換時。Conversion Interrupted, Conversion with defects(PDF に画像が出ない等), Nbconvert bugs。 - Portability (PB) — SO 2.7% / GH 1.3%。別環境・別プラットフォームでの実行。GitHub Bugs(GitHub 上で
.ipynbがレンダリングされない), Nbviewer bugs, Different Platforms(Colab/JupyterLab/別OS)。 - Environment and Settings (ES) — SO 43.2% / GH 35.6%。最頻。開発環境・設定の問題。Update/Downgrade Version(バージョン非互換), Installation Bugs, Incompatible Component。
- Connection (CN) — SO 6.2% / GH 0.9%。外部リソース(DB・ハード・リポジトリ)との接続。External Resource Access Bugs, Disconnection and Connection Establishment Bugs。
- Processing (PC) — SO 4.9% / GH 1.9%。Timeout・メモリ・処理時間。Memory Leak, RAM and GPU Bugs。
- Cell Defect (CD) — SO 3.6% / GH 2.6%。セル描画(code/markdown/出力)。Layout Bugs(マージン超過・空セル・可視化崩れ), Interactive Components Bugs(
input()・スクロールバー等)。 - Implementation (IP) — SO 22% / GH 44.2%。GitHub では最頻。一般的な実装バグ。Semantic Error(論理), Syntax Error, Data Science lib wrong usage(Pandas/Scikit-learn/TensorFlow 等の誤用), Data Science Algorithm Error。
頻度分布が Figure 3。両データセットで ES と IP が突出しており、両者で6割超。インタビューでもバージョン管理・コンポーネント非互換・誤インストール・拡張の問題が裏づけられた。
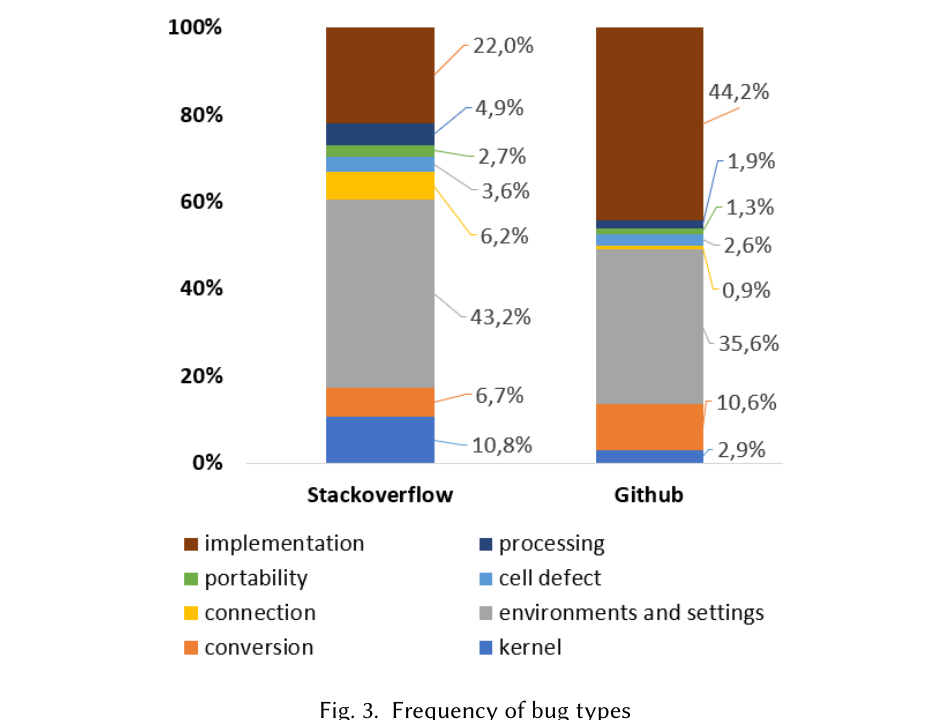
Figure 3. バグ種類の頻度。左 Stack Overflow・右 GitHub の積み上げ棒。ES(灰)と IP(茶)が両者で大半を占める。GitHub では IP が 44.2%、SO では ES が 43.2%。
さらに 2014–2021 の 年平均成長率(AGR)を Stack Overflow で算出(各年の成長率を平均)。全体平均(赤破線)を上回るのは4種類で、Figure 4 のとおり Implementation 48% / Portability 39% / Environments and Settings 38% / Cell Defect 37%。注目点は、Portability と Cell Defect は出現数こそ少ないが成長率は平均超ということ。
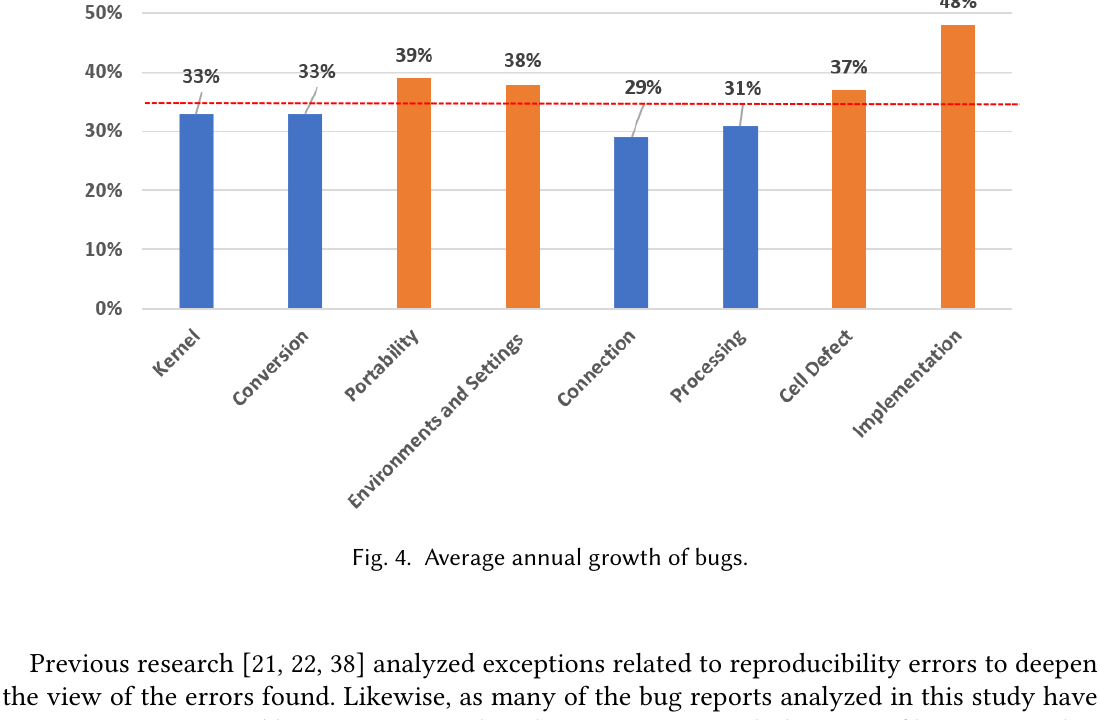
Figure 4. バグの年平均成長(2014–2021)。橙=平均超、青=平均以下、赤破線=全体平均。Implementation(48%) が最大、Portability(39%)・Cell Defect(37%) も低出現ながら高成長。
バグに伴う Python 例外も集計(Table 2)。ImportError / ModuleNotFoundError / AttributeError は ES に多く、TypeError / AttributeError / NameError は IP に多い。
Finding 1: 最頻バグは Environments and Settings(SO 43.2% / GH 35.6%)と Implementation(SO 22% / GH 44.2%)で、年平均成長も平均超(38%・48%)。Portability と Cell Defect は出現数は少ないが、年々の成長率は平均を上回る。
RQ2: 根本原因
bug type × root cause のクロス集計が Table 3。10種類の root causeを同定。上位3つは:
- Install and Configuration Problems(SO 32.1% / GH 16.3%)— インストール・設定の問題。ES バグの主因。
- Version Problems(SO 19.0% / GH 22.5%)— コンポーネントのバージョン不整合。
- Coding error(SO 17.6% / GH 31.5%)— semantic / logical / syntax のコーディングミス。IP バグの主因。
その他: Hardware/Software Limitations(SO 6.7% / GH 6.1%、特に Memory Error が Processing バグの主因)、Logic error(約2%)、TimeOut、Deprecation、Permission denied など。Unknown(SO 13.3% / GH 8.1%)は原因特定できなかったもので、特に Kernel バグに多く、「原因の分かりにくさ」を示唆。
Finding 2: 最頻の root cause は Configuration issues(SO 32.1% / GH 16.3%), Version issues(SO 19.0% / GH 22.5%), Coding Error(SO 17.6% / GH 31.5%)。これらが ES・IP バグの大半を生む。Unknown は Kernel バグに多く、原因同定の難しさを示す。
RQ3: バグの影響
impact × bug type のクロス集計が Table 4。主要な impact は3つ:
- Run Time Error(SO 57.5% / GH 31.2%)— エラーメッセージを伴う実行失敗。SO では最頻、GitHub では2番目。ES・IP バグに多い。
- Incorrect Functionality(SO 13.5% / GH 57.3%)— コードは走るが結果が想定外。GitHub では最頻、SO では3番目。
- Crash(SO 24.3% / GH 3.3%)— エラー・例外・警告なしに動作/起動が止まる。Kernel バグに多く、GitHub で少ないのは「カーネル再起動で直り、修正コミットに現れにくい」ためと推測。Kernel Crash は全インタビュー参加者が言及した唯一のバグ/影響で、「面倒だが再起動すれば回避できる」とされた。
他に Bad Performance(SO 3.0% / GH 7.5%), Warning(SO 1.7% / GH 0.7%)。
Finding 3: 最頻 impact は Run Time Error(SO 57.5% / GH 31.2%), Incorrect Functionality(SO 13.5% / GH 57.3%), Crash(SO 24.3% / GH 3.3%)。ES・IP・Kernel バグの影響。Kernel Crash は日常的で、主な回避策はカーネル再起動。
RQ4: 現場の課題(インタビュー)
5つの課題が浮かび上がる。
- 背景・素養(Backgrounds and requirements): Jupyter ユーザは物理・数学・IT など多様で、計算機出身でない人も多い。経験が浅いと messy / dirty なノートブックになりやすく、バグの認識・修正の仕方にも差が出る。「構造化・可読・文書化されたコードへの配慮はソフトウェア工学の素養から来る」(DS3)。
- ソフトウェア品質(Software Quality): Jupyter はセル複製やドラッグ&ドロップを許し、品質を制御・支援する仕組みがない。「IDE(VSCode / RStudio)の方が良いコードが書ける」(DS14)。
-
テストとデバッグ(Testing and debugging): 基本的な test/lint ツールが使いにくい。「unit testing と lint が本当に恋しい。Black, Isort, Pylint, Flake8, Bandit を Jupyter で使うのは非常に難しい」(DS11)。デバッグの難しさは、Stack Overflow の accepted answer 率・未回答・回答までの時間にも影響しうる。
Stack Overflow で各バグ種に accepted answer が付いた割合は Figure 5。全種で平均 27.9% と低め。回答が得られるまでの平均日数は Figure 6 で、ドメイン平均は 21日、8種中4種がこれを上回る(特に Portability は 100.9日 と突出)。
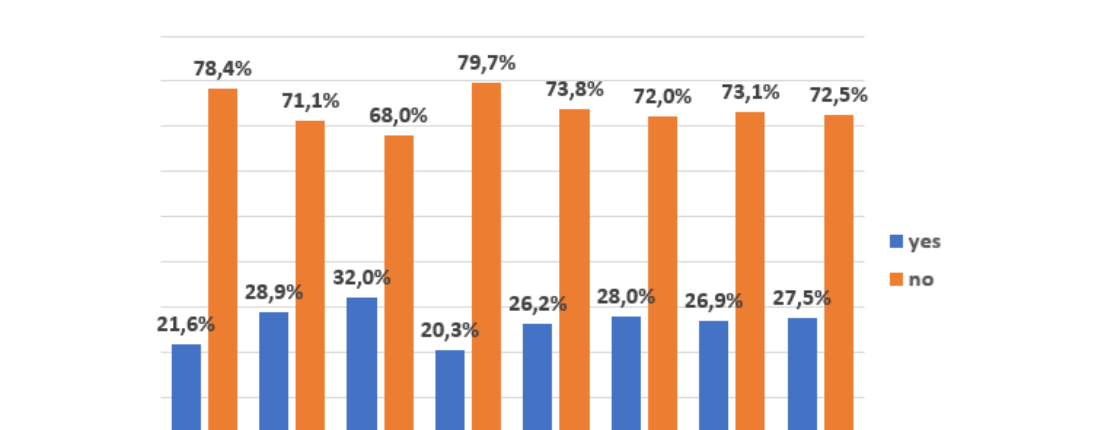
Figure 5. accepted answer のある投稿の割合(青=yes / 橙=no、左から KN, ES, IP, CV, PC, CD, CN, PB)。yes はどの種でも 2〜3割程度(20.3〜32.0%)。
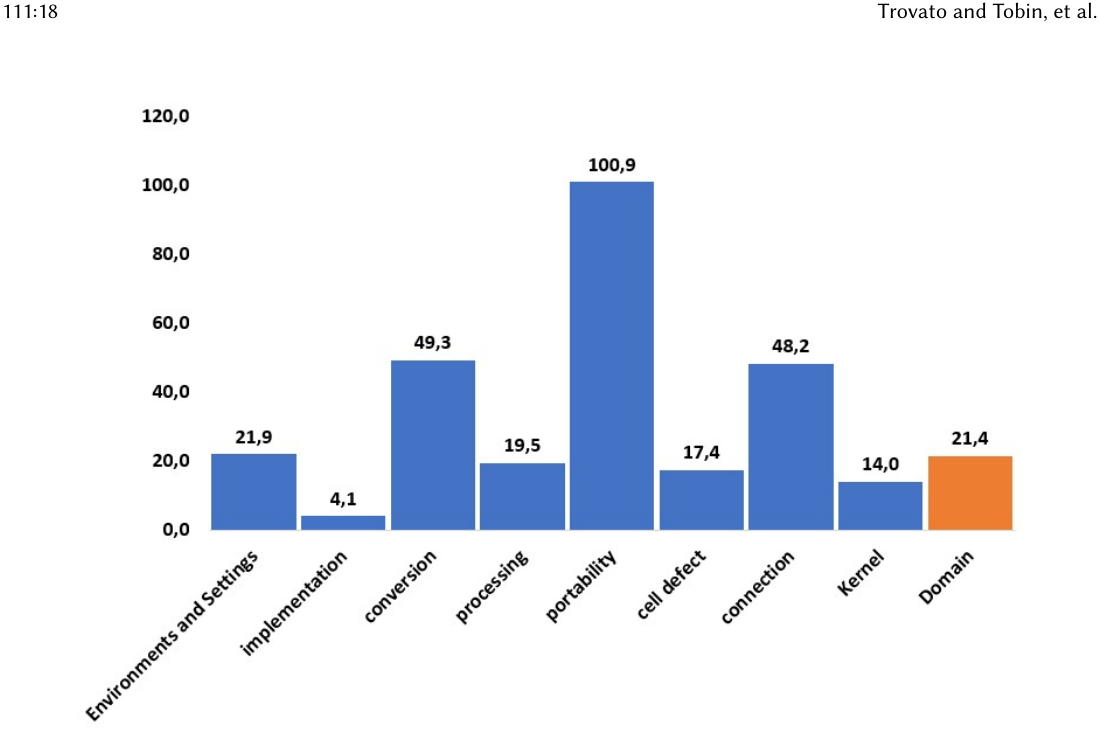
Figure 6. accepted な回答が付くまでの平均日数。Portability が 100.9日 と突出、Conversion 49.3 / Connection 48.2 が続く。ドメイン平均(Domain, 橙)は 21.4日。
- データ分析の成果物化(Data analysis deployment): ノートブックは(1)成果物そのもの、(2)システムに組み込む元コード、の2通りで使われる。探索・プロトタイピングには良いが、最終成果物・本番デプロイへの変換を支援する機能が乏しい。「Jupyter の中身を deliverable にするのは簡単じゃない」(DS11)「本番投入には自明でない変更が要る」(DS7)。
- 悪いプログラミング習慣(Bad Programming Practices): 計算機科学以外の出身者が Jupyter からプログラミングを始めることが多く、「コード品質を気にしない文化」が伝播する懸念。Stack Overflow の年次調査でも 2017年以降 Jupyter の投稿・バグは増加し続けている(Table 5: Posts/Bugs の年次推移)。
Finding 4: データサイエンティストはバグを各自の経験で異なって捉える。ソフトウェア工学の実務経験がバグ同定の仕方を左右し、Jupyter にテスト/デバッグを促す機能が欠けていることが修正を難しくする。
Finding 5: 分析を製品に変えることは産業で重要な機能だが、コード品質とこの移行を支える資源が不足。一部ユーザは「Jupyter と IDE の良さを両立する代替」を探す。品質支援の欠如は新人の悪い習慣にもつながる。
考察・含意
ツール作成者・研究者・データサイエンティストへの示唆。
- 最頻の ES バグは設定・バージョン・deprecation 由来が多く、ソフトウェア工学研究が貢献できればデータサイエンティストの時間を大きく節約できる。
- IP バグ(GitHub 44.2%)は test/bug localization/repair の不慣れから来る “Incorrect Functionality” が多く、既存の SE 技術の認知向上と、Jupyter にシームレスに統合できるツールの開発が必要。
- バージョン管理は SE の標準だが Jupyter では標準でない。既存 VCS は生成された GUI コンポーネントの差分を比較できないため、GUI 変化を比較できるツールが有効。
- 高度なデバッグ機能(ノートブックで定義された変数とその値のビューア等)の要望が強く、これが実装エラーを減らしうる。
- 95% の回答者が「データの分析・調査・探索という主用途では Jupyter は非常に有用」とした一方、79% が「分析を本番コードに変換する難しさ」を挙げた。
- ユーザが望む機能の非網羅リストが Table 6(Indentation corrector, Syntax highlighting, Data Preview, Graphic Interaction, Multi-Languages Per Cell, Version control, Variable Manager, Connection Between Notebooks 等)。拡張で既にあるものもあるが、その利用が容易でなく互換性・バージョン・設定エラーを生むため、統合パッケージ化または標準搭載が望ましい。
妥当性への脅威
プロプライエタリなリポジトリ未分析(OSS 105件で緩和)、キーワード方式ゆえ見落とすバグがありうる、手作業分類の主観(3著者で独立分析し合意)、Stack Overflow 投稿の信頼性(score≥5・評判で選別)、taxonomy の非網羅性(105リポジトリ・14,740コミット・30,416投稿で緩和)、インタビューのバイアス(12社・相互非接触・パイロット実施・参加者への確認)。
関連研究との位置づけ
Chattopadhyay ら(15名インタビュー+156名調査で9つの困難をカタログ化)と違い、本研究は実際のバグの視点から課題を示す。Pimentel らの再現性研究(24.11%/4.03%)や Rule ら(100万ノートブックの構造分析)、Patra ら(Name-Value 不整合)が構造・再現性に注目するのに対し、本研究はバグそのものの種類・原因・頻度・影響を分類・定量化する点が新しい。深層学習(Zhang/Islam)・MLシステム(Thung)・自動運転(Garcia/Dinghua)・IaC(Rahman)のバグ実証研究はあったが、Jupyter プロジェクトのバグの実証研究は本研究が初。
結論
105 GitHub リポジトリの 855コミット、2,585件の Stack Overflow 投稿、19名のインタビューを分析し、8カテゴリのバグ taxonomy・10種の root cause・影響を提示。最頻は ES と IP、根本原因は設定・バージョン・コーディングエラー、最頻 impact は Run Time Error と Incorrect Functionality。データサイエンティストの背景がバグ同定の仕方を左右し、テスト/デバッグ支援の弱さとデプロイ支援の欠如が大きな課題。バグ検出・修正推薦ツールなど今後の研究の方向を示す。
Q&A
(まだなし)
自分のコメント
(まだなし)