AI解説
arXiv 版(全文): https://arxiv.org/abs/2511.14162(実装: https://github.com/illinoisdata/pod。同 Park 研。ElasticNotebook → Kishu の系譜) 情報源: arXiv 全文 PDF(15頁)を pymupdf で本文抽出して精読。図・式・アルゴリズム・実験数値を本文で確認済み。以前「本文に無い」として削っていた期待永続化コストの式は、実際には Algorithm 1・式(4)(5) として本文に明記されていたので、原文の記号(s=サイズ、λ=volatility、c_pod=pod固定費)で正しく復元した。 図について: 原論文(arXiv PDF)の図を貼る(
figures/fig*.png、図番号・キャプションは原論文に対応。PDF からページ領域を切り出して生成)。論文に図が無い **LGA の判定ロジック(Algorithm 1)だけ AI 生成の補足図(figures/lga-decision-flow.svg)で補う。図はコミットして GitHub Pages にも公開する(サイトは noindex +robots.txtで検索除け)。
一言で
データサイエンスのオブジェクト永続化(Pickle/Dill 等)は毎回まるごとスナップショットするため、変わっていないオブジェクトまで冗長に保存して時間も容量も無駄になる。Chipmink は、巨大なオブジェクト グラフを pod(部分グラフ) に構造を意識して分割し、版間で pod を比較して変わった pod だけを部分永続化する「グラフ ベースのオブジェクト ストア」。DBMS のバッファ マネージャに相当する役割を、ヒープ・共有メモリ・GPU・リモートにまたがる状態に対して果たす。実ノートブック/スクリプトで、ストレージを最大 36.5×、永続化を最大 12.4× 改善し、経験的に 100% のライブラリを扱える。
背景・問題
バッチ スクリプトから計算ノートブックまで、現代のデータサイエンスは巨大で刻々と変わるオブジェクト グラフ(pandas・networkx・pytorch/tensorflow モデル等)を扱う。これを安く正しく保存・復元できれば、障害耐性も、版管理による非線形な探索も支えられる。まず「データシステムの足元には、刻々と変わる巨大オブジェクト グラフがある」という出発点を図で押さえる。

Figure 1: データシステムの足元には巨大で進化し続けるオブジェクト グラフがある。(a) ライブラリ import → (b) データのロード/クリーニング → (c) モデルの学習・評価、とセルを進めるたびにグラフが変わる。(d) はその時点の全オブジェクトと参照、(e) は実ノートブックのオブジェクト数(数十万〜数百万)。オレンジ=その実行で変わったオブジェクト、青=変わっていないオブジェクトで、大半は青(不変)であることが見て取れる。
既存手段は破綻している。Pickle・Dill・ZODB は参照を辿って完全なバイト表現のスナップショットを作るので、実行中に複数地点で保存すると変わっていない同じオブジェクトを何度も捕捉する。論文の例 buildats ノートブック(21万オブジェクト)では、42 スナップショットの保存に延べ約 300 万オブジェクトを処理する羽目になる。一方で実際に変わるのは 6.1% だけ——つまり 16.5 倍の削減余地がある。
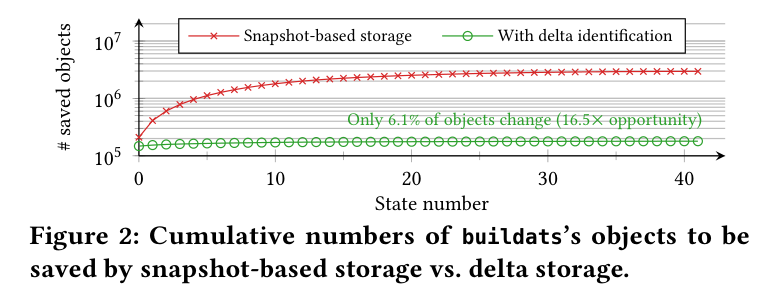
Figure 2: buildats を 42 状態ぶん保存したときの、累積で処理するオブジェクト数(対数軸)。赤=スナップショット方式は変わらないオブジェクトも毎回数え直すので右肩上がりに約 300 万まで膨らむ。緑=差分同定(delta identification)方式なら、実際に変わる 6.1% だけを保存するので 21 万付近でほぼ横ばい。この差が「16.5× の機会」。
根本原因は、DBMS と違って既存のオブジェクト永続化に delta identification(オブジェクト グラフ間の差分同定) が無いこと。既存の差分手法もどれも不十分だと論文は指摘する。
- グラフ DB(Neo4j 等):import・データクリーニング・モデル学習のように「見かけ静的なのに共有された入れ子構造を変える」暗黙の更新を正確に追えない。
- 手動の注釈/DB 形式への変換/型を選んで保存:ユーザ定義型や外部ライブラリ内部の多様さ(例: 組込4・外部63・ユーザ定義37 変数)を網羅できない。
- バイトレベルの差分圧縮(LZ77・xdelta 等):差分は取れるが、毎回 名前空間全体を直列化してから圧縮するためスナップショットより遅く、ロード時も参照+差分を両方読んで復元する必要があり、しかも「どれを参照バイト列にするか」が未解決。
- 古典アルゴリズム(グラフ整合・編集距離・グラフ分割):数百万オブジェクトには非効率。
問題は「散在する巨大オブジェクト グラフに対し、変更差分(delta)を正確・網羅的・効率的に同定する手段が無い」こと。
提案手法
Chipmink が「保存・復元」で何をするかは、論文の走る例(running example)が分かりやすい。3 つの状態を保存し、後から一部だけをロードして探索する。
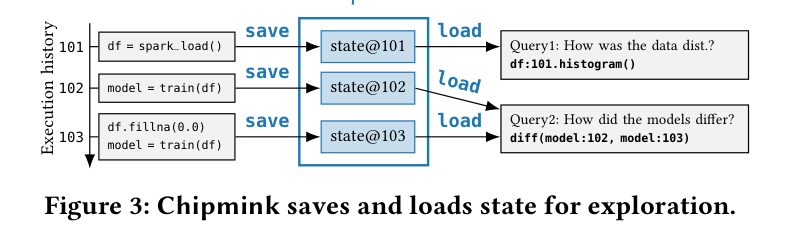
Figure 3: Chipmink は探索のために状態を保存・ロードする。実行履歴 101→102→103 で df/model が育つ。各 save は全部ではなく変わった部分だけを state@N として残し、load は欲しい変数だけを取り出す(Query1 は df:101 だけ、Query2 は model:102 と model:103 だけ)。名前空間まるごとを復元しないのが効きどころ。
数値で見ると効果は明確。dataset 10.1GB + imputer/model 各 0.1GB のとき、スナップショットで 3 状態保存すると 10.1 + 10.3 + 10.3 = 30.7 GB。構造を意識した差分なら、imputer が dataset の 5%(0.5GB)しか埋めないと検出して 10.1 + (0.5+0.1+0.1) + 0.1 = 10.9 GB(約 3× 削減)。部分ロードも、model が dataset の 25% を指すなら Query2 は (2.5+0.1)+(2.5+0.1)=5.2 GB で済む(いずれも論文 §3 の数値)。
1. 「Goldilocks 粒度」の差分 — pod(部分グラフ)
オブジェクト単位の差分でもグラフ全体のスナップショットでもなく、ちょうど良い(Goldilocks)粒度=オブジェクト グラフを部分グラフに分割して差分を取る。2 時点の部分グラフを比較し、一致しない部分グラフだけを永続化する。この部分グラフを pod と呼ぶ。まず土台となる ObjectGraph(オブジェクト=ノード、参照=辺、変数名=青い破線でルートのオブジェクトに接続)を押さえる。
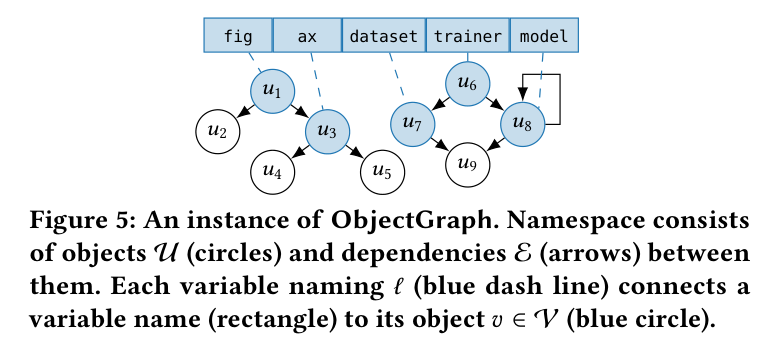
Figure 5: ObjectGraph のインスタンス。名前空間はオブジェクト U(丸)と依存 E(矢印)から成り、変数名(四角)が青い破線で根のオブジェクト v∈V(青丸)に結びつく。fig/ax/dataset/trainer/model という変数が、共有された入れ子オブジェクト群(u1…u9)を指している様子。podding はこのグラフを pod に切り分ける。
正しい粒度を得るには 2 つの課題がある。
- pod 内(within-subgraph):pod の構成と大きさを最適化する。構成は安定であるべき(前の版とほぼ同じ pod 集合になるように。新規 pod を減らすため)。大きさはバランス——dirty なオブジェクトだけを隔離できるほど小さく、かつ pod ごとの管理オーバーヘッドを抑えられるほど大きく。
- pod 間(cross-subgraph):dirty な pod を保存・復元するとき、pod をまたぐ参照を正しく保つ。pod 間参照は仮想アドレスとして扱い、復元時に適切なローカル参照へ解決する(Synonym Resolver)。
2. podding — 3 つの分割アクション
中核は podding:直列化(pickle)が ObjectGraph を深さ優先で巡回するのに相乗りし、各オブジェクトで「どう pod を作るか」を決める。選べるアクションは 3 つ。
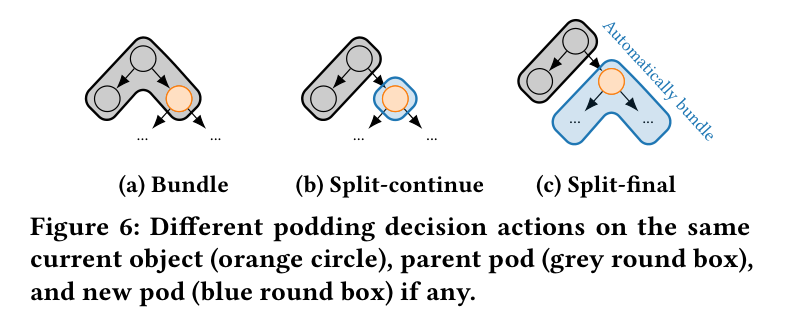
Figure 6: 同じ現在オブジェクト(オレンジ)・親 pod(灰色の角丸)に対する 3 つの podding アクション。(a) bundle=親 pod に同居させる。(b) split-continue=新しい pod(青)に分け、子オブジェクトにも判定を続ける。(c) split-final=新しい pod に分け、子はその pod に自動的にまとめて打ち切る。「全部バラす」と pod 管理費が爆発、「全部束ねる」と部分保存・部分ロードが効かなくなるので、この中間を賢く選ぶのが肝心。
3. LGA — 期待永続化コストを最小化する貪欲法
どのアクションを選ぶかを、期待永続化コストの最小化問題として定式化し、Learned Greedy Algorithm (LGA) で一度の巡回(one-pass greedy)で解く。各オブジェクトのサイズ s と、変わりやすさ λ(volatility) を使う。λ(u) は「1 回のコード実行あたりにそのオブジェクトが変化する回数(≤1)」を Poisson でモデル化したもので、pod の volatility は Poisson の合成性から λ(u_p)=Σ λ(u) で合算できる。λ は型に依らない軽量な特徴量から推定する。
LGA は各オブジェクトで「束ねる増分コスト ΔL_bundle」と「分ける増分コスト ΔL_split」を比べ、安い方を選ぶ(論文 式(4)(5))。
ΔL_bundle = s(u_p)·λ(u) + s(u)·(λ(u_p)+λ(u))… pod が大きく・変わりやすくなるぶんの増分。ΔL_split = c_pod + s(u)·λ(u)… 新しい pod 1 個ぶんの固定費c_podを払う代わり、親 pod の volatility は据え置ける。
つまり「大きくて変わりやすいオブジェクトは分けて隔離、小さくて安定なものは束ねる」という直感が、そのままコスト比較として出てくる。分ける場合は pod の入れ子の深さで split-continue / split-final を切り替える(深くなりすぎたら打ち切り)。

補足図(AI生成): LGA の 1 オブジェクトごとの判定(Algorithm 1)。束ねる費用 ΔL_bundle と分ける費用 ΔL_split を計算 → 束ねた方が安ければ bundle(灰=親 pod に同居)、そうでなければ pod の深さを見て split-continue / split-final(青=新 pod)。色は Figure 6 と揃え、オレンジ=対象オブジェクト・青=新 pod・灰=親 pod。
4. システム構成(部分保存・部分ロード・非同期)
全体のデータフローはこの 1 枚に集約されている。青=部分保存/ロード(§4)、オレンジ=podding 最適化(§5)、緑=探索を止めないための安全機構(§6)。
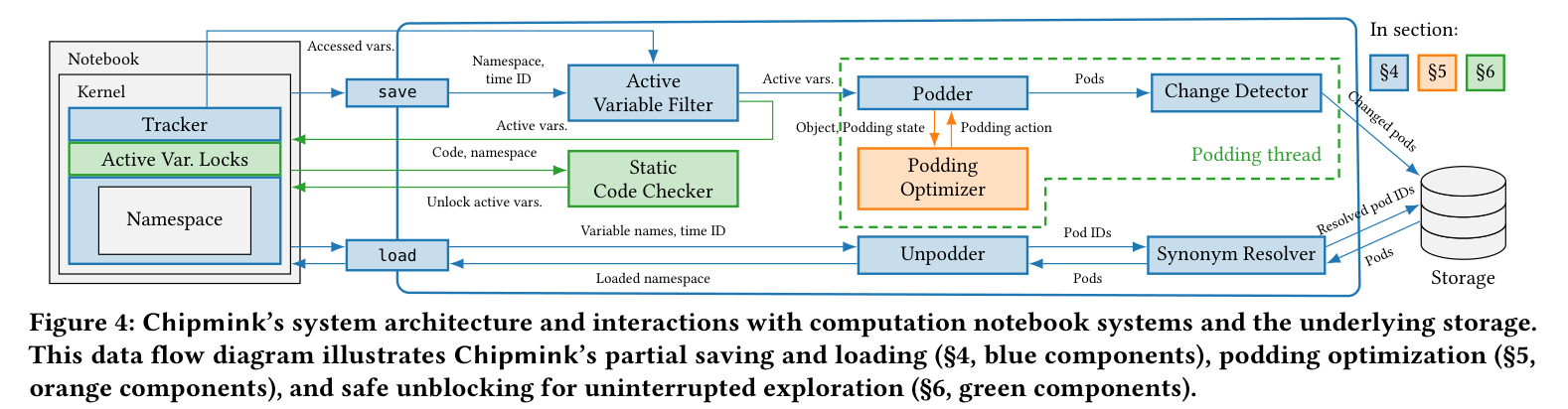
Figure 4: Chipmink のシステム構成と、ノートブック カーネル/ストレージとのやりとり。save から、Active Variable Filter →(podding スレッドで)Podder+Podding Optimizer → Change Detector → 変わった pod だけを Storage へ。load は逆向きに Synonym Resolver → Unpodder で必要 pod だけを組み立てる。Static Code Checker と Active Var. Locks(緑)が、保存中もカーネルの探索を止めない安全弁。
- 部分保存:(1) 保存すべき変数を特定(Tracker+Active Variable Filter)、(2) 依存オブジェクトを pod に分解(Podder+Podding Optimizer=LGA)、(3) 変わった pod を検出してストレージへ書き、変わらない pod は同義 pod ID にリンク(Change Detector)。
- 部分ロード:(1) 同義 pod を解決して必要な pod だけ読む(Synonym Resolver)、(2) pod から元オブジェクトを組み立てる(Unpodder)、(3) 要求変数を返す。名前空間全体をロードしないのが効きどころ。
- 非同期保存と安全性:関連変数を特定したら残りの podding を podding スレッドへオフロードし、関連変数を名前空間ロック(Active Var. Locks)で保護しつつ他変数へのアクセスを許す(探索を止めない)。allowlist ベースの静的コード チェッカ(ASCC) で安全性を担保。
5. 何を保存すれば足りるか — active / accessed 変数
毎回すべての変数を見る必要はない。あるセルが実際にアクセスした変数(accessed)に連結していないオブジェクトは変化しえないので、保存対象から外せる(Active Variable Filter)。
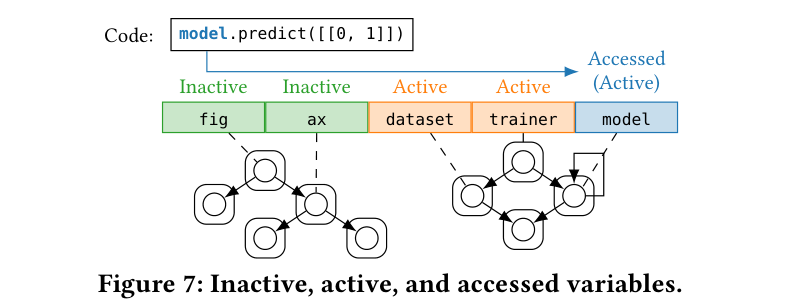
Figure 7: model.predict([[0,1]]) を実行したときの変数の区別。コードが触る model が accessed、それと ObjectGraph 上で連結する dataset/trainer が active(変化しうる)、連結しない fig/ax は inactive(このセルでは絶対に変わらない)。inactive を差分検査・保存からスキップすることで、巨大グラフでも検査コストを抑える。
API と互換性
save(namespace) -> TimeID で保存し load(names, time_id) -> NS で部分復元する。Pickle の汎用プロトコルに乗ることで広く互換。Python エコシステム(pandas・arrow・pytorch・tensorflow・scikit-learn・ray・matplotlib・seaborn など)を経験的に 100% カバーし、Pickle・Dill・Cloudpickle を完全に置換できる。
dirty 判定の土台は直列化バイト列の同値性で、Ser(G) ≠ Ser(G') なら変更とみなす(§3)。型ごとの直列化は Pickle/Dill が各型のレデューサに委譲するので、共有メモリ・GPU・リモートに散在するオブジェクトも、ライブラリ自身の直列化経路に乗る限りそのまま pod 化・差分できる(GPU 専用の差分機構は持たず、いったんホストへ直列化してから byte 単位で pod を比較する)。§7.4 が挙げる移植要件も①構造と共有参照を表せる直列化プロトコル、②コード実行の局所性の 2 つだけで、GPU 固有の前提は無い。
数式・アルゴリズム
LGA の定式化は「期待永続化コスト L を最小化するように pod の構成と大きさを決める」最適化で、貪欲法(Algorithm 1)で一度の巡回で近似解を得る。各オブジェクト u・現在 pod u_p について:
ΔL_bundle = s(u_p)·λ(u) + s(u)·(λ(u_p)+λ(u)) … 式(4) 束ねる増分
ΔL_split = c_pod + s(u)·λ(u) … 式(5) 分ける増分
if ΔL_bundle < ΔL_split: return bundle
elif pod_depth < MAX_POD_DEPTH: return split-continue
else: return split-final
ここで s=サイズ、λ=volatility(1 実行あたりの変化率、Poisson、λ(u_p)=Σλ(u))、c_pod=pod 1 個の固定オーバーヘッド。直感は「大きくて変わりやすいオブジェクトは独立 pod に隔離し、小さく安定なものは束ねて pod 数を抑える」。λ を Poisson と置くのは相関を無視する簡略化で、論文も限界として「相関・高次統計を入れた拡張」を将来課題に挙げている。
実験・結果
主結果は「保存ストレージ」と「保存レイテンシ」の 2 軸。まずストレージ。
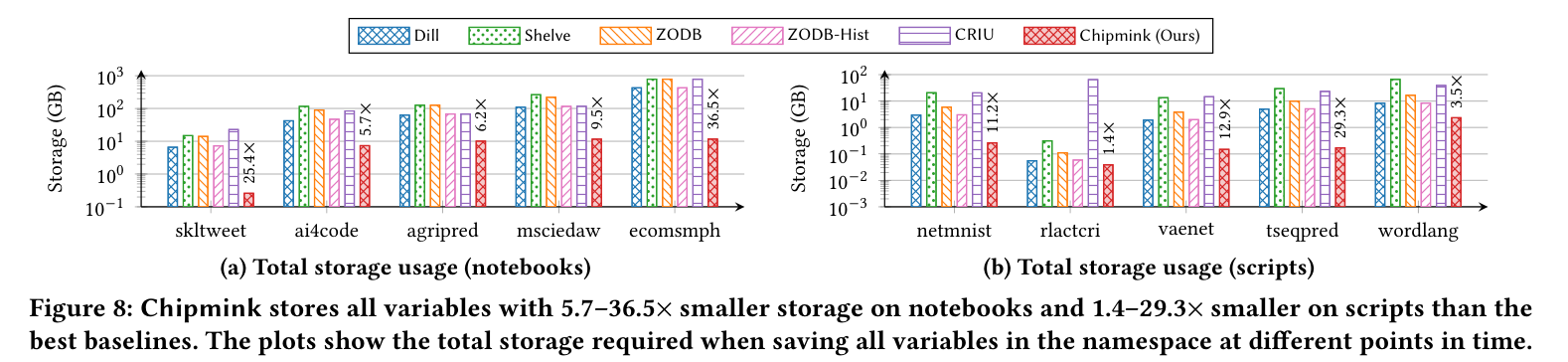
Figure 8: 名前空間の全変数を各時点で保存したときの総ストレージ(対数軸)。(a) ノートブック 5 本で 5.7–36.5× 小さい、(b) スクリプト 5 本で 1.4–29.3× 小さい。比較対象は Dill / Shelve / ZODB / ZODB-Hist / CRIU。赤=Chipmink(Ours)が一貫して最小。
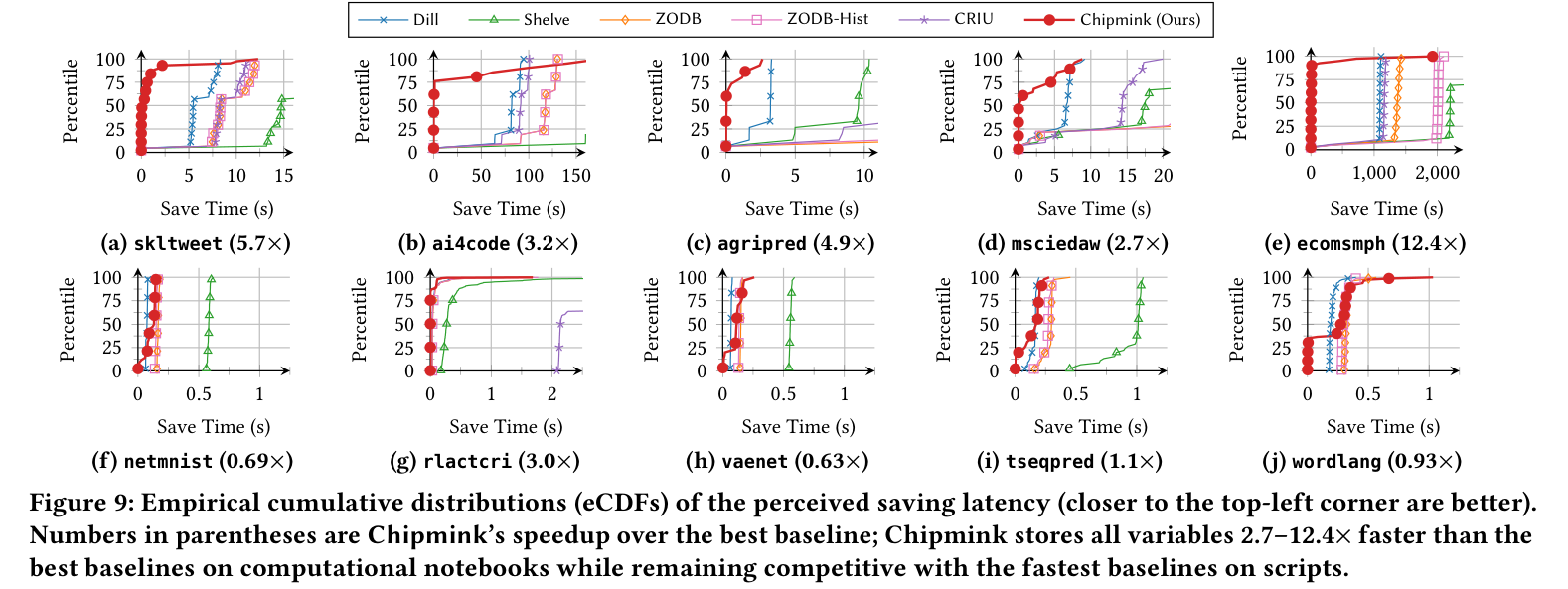
Figure 9: 体感保存レイテンシの経験的累積分布(eCDF、左上に寄るほど速い)。ノートブック (a)–(e) で最良ベースライン比 2.7–12.4× 速い。スクリプト (f)–(j) でも最速ベースラインに肉薄。Chipmink(赤)の曲線が左上に立ち上がる。
保存時間の内訳を見ると、Chipmink が何にコストを払っているかが分かる。
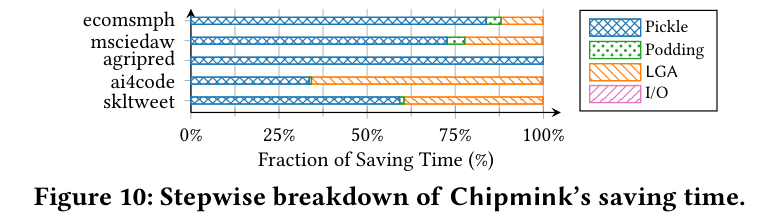
Figure 10: Chipmink の保存時間の段階別内訳。Pickle(直列化)・Podding・LGA・I/O の割合。多くのノートブックで I/O ではなく直列化と podding/LGA の計算が主で、つまり「書く量を減らした結果、ボトルネックがディスク I/O から CPU 側へ移っている」。
部分ロードは、欲しい変数のサイズに比例して速くなる(名前空間全体に依存しない)。
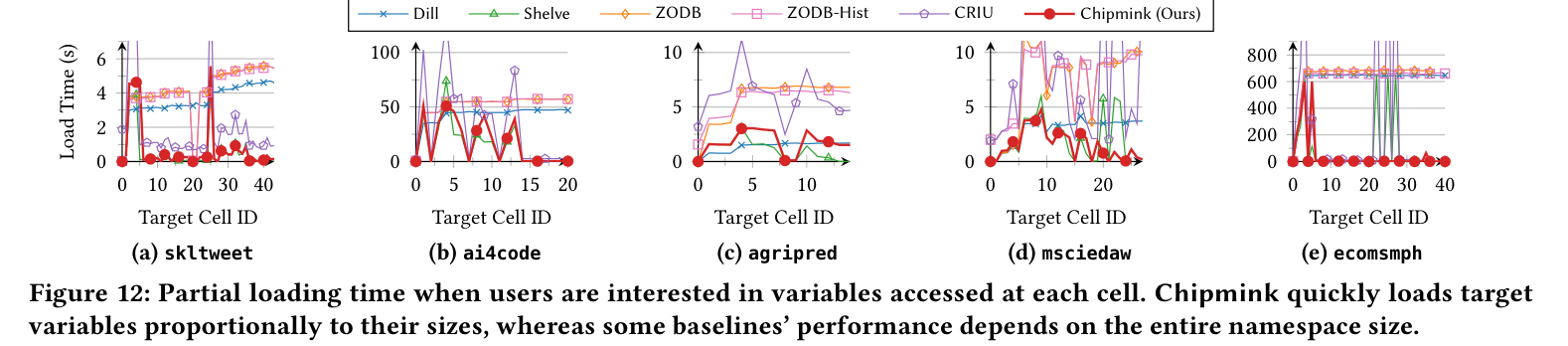
Figure 12: 各セルでアクセスされる変数だけを部分ロードしたときのロード時間。Chipmink(赤太線)は対象変数のサイズに比例して速く読むため、名前空間全体のサイズに引きずられるベースライン(ZODB-Hist・CRIU 等が上に張り付く)より一貫して低い。
数字の解釈:完全スナップショット系は「変わっていない巨大オブジェクトを毎回書く」ので、不変部分が多い・探索でちょっとずつ変えるワークロードほど無駄が積もる(buildats では実変化 6.1% に対し全保存は 16.5 倍の無駄)。Chipmink は変わった pod だけ書くのでそこで差が開く。共有メモリ・GPU・リモート オブジェクトに依存するライブラリでも動く一般性(経験的に 100% のライブラリ)も示されている。
関連研究との関係(メモ)
- Kishu(
li2025kishu、同 Park 研):Kishu の Co-variable 差分検知と Chipmink の pod による delta 同定は問題意識が直結する(どこが dirty かを安く見つける)。Chipmink はそれを、より大規模・散在(共有メモリ/GPU/リモート)なオブジェクト グラフへ一般化・効率化した後続と読める。 - ElasticNotebook(
li2023elasticnotebook):状態を「保存 vs 再計算」(min-cut)で最適化するライブ移行の先行。本論文は §3 の同値性の定義で「value と structural の両情報を見る」点が同様だと 一度引用するだけで、実験比較は無い。差分は単位(セル実行 vs オブジェクト)・機構(再計算/転送 vs 差分永続化)・目的(1 回の移行 vs 多数の版)で、Chipmink は保存そのものを構造的差分で安くするオブジェクト ストア(上位の移行/版管理システムの下回りになりうる)。詳細は Q&A の Q2。 - Pickle / Dill / Cloudpickle(
python2025pickle/uqfoundation2025dill/cloudpipe2025cloudpickle):本論文が比較・置換対象とする完全スナップショットのベースライン。「中央バッファ マネージャ(dirty 追跡)の不在」をこれらの根本欠点と位置づける。
Q&A
Q1. GPU は対応してる?
A. 「GPU 常駐オブジェクトでも壊れずに保存・差分できる」という意味では対応。ただし GPU ネイティブの差分機構は持たない。
- 論文での扱い(アブスト・§1・§7.4 のみ): GPU はアブストラクトで「shared memory・GPU・remote のオブジェクトに依存するライブラリも扱える」と一般性の主張としてのみ登場し、本文に GPU 専用の機構の説明は無い。対応ライブラリは pandas/arrow/pytorch/tensorflow/scikit-learn/ray/matplotlib/seaborn を「経験的に 100%」カバーと述べる(§1)。
- なぜ動くか: Chipmink の dirty 判定は直列化バイト列の同値性「
Ser(G) ≠ Ser(G')なら変更」で行う(§3)。型ごとの直列化は Pickle/Dill/Cloudpickle(各型の__reduce__)に委譲するので、CUDA テンソルのような GPU 常駐オブジェクトも、ライブラリ自身のレデューサが host(CPU) にコピーしてバイト化する経路に乗る限り、そのまま pod 化・差分できる。=いったんホストに直列化してから byte 単位で pod を比較するのであって、GPU 上で直接差分を取るわけではない。 - §7.4 の移植要件: ①構造と共有参照を表せる直列化プロトコル、②コード実行の局所性、の 2 つだけ。GPU 固有の前提は無い。
- ソースコード確認(
github.com/illinoisdata/pod、本文に無い実装詳細):pod/*.pyに cuda/gpu/device 専用パスは無い。低レベルで関係するのはpod/__pickle__.pyの PickleBuffer / pickle protocol 5 の out-of-band バッファ処理(numpy/torch のストレージのような連続メモリの大バッファを効率良く扱う)のみ。付属の torch ベンチ(notebooks/torch_mnist.py等)は--no-cuda(CPU) で実行されており、論文の実測も CPU。
Q2. ElasticNotebook との差分は?
A. 論文内に実験比較は無い(ElasticNotebook [61] は参照リストにあるだけ。本文での唯一の言及は §3 の同値性の定義で「我々の equality は Li et al.[61] と同様に value と structural の両情報を見る」と一度引用するのみ)。よって差分はソースコード(同 Park 研の pod レポジトリ)と両論文から整理する。
- ElasticNotebook:セッションのライブ マイグレーションが目的。Application History Graph(AHG=セル実行と変数の二部グラフ)を持ち、各変数を「保存して転送する」か「移行先でセル再実行して作り直す」かを min-cut で「保存 vs 再計算」最小化。基本は 1 回の引っ越し最適化。
- Chipmink(pod):永続オブジェクト ストア。API は
save(ns)->TimeID/load(names, tid)->ns。再計算もセル再実行も AHG も無い(必ず保存する)。効きどころは (1) pod 粒度の差分=変わった pod だけ書く、(2) 内容ハッシュによる重複排除(同一バイトの pod は synonym ポインタにして本体を書かない)、(3) 部分ロード。複数版を時系列に残す(バージョン管理/チェックポイント)用途で、1 回の移行ではない。ストレージ層も差し替え可能(File/圧縮/PostgreSQL/Redis/Neo4j)。 - 一言で:ElasticNotebook=「セル単位で 保存 vs 再計算 を選ぶライブ移行器(グラフ=セル実行)」、Chipmink=「オブジェクト単位で 変わった所だけ永続化する オブジェクト ストア(グラフ=オブジェクト)」。単位(セル vs オブジェクト)・機構(再計算/転送 vs 差分永続化)・目的(1 回の移行 vs 多数の版)がすべて違う。両者は補完的で、Chipmink はこうした上位システムの下回り(ストレージ層)になりうる。
Q3. チェックポイント ファイルはどこに・どうやって保存する?
A. (論文 §8.11 はストレージ層を ablation するが、ファイル配置の詳細はソースコード github.com/illinoisdata/pod。)
- どこ:既定は
FilePodStorageで/tmp/chipmink/(pod/__init__.pyの__DEFAULT_PICKLING__)。root_dirは差し替え可能。 - 単位:保存単位は pod。各 pod を
PodId = (tid, oid)で識別。tid=保存ごとに増える版 ID(step_time_id)、oid=id(obj)。同じオブジェクトの版はoidを共有しtidで区別。 - ファイル構成(FilePodStorage):
pod_<N>.pkl… pod 本体ページ。{PodId: pod_bytes}を pickle した辞書。小 pod(<1KB) はバッファに溜めて 1MB ごとに 1 ページ、大 pod(>1KB) は個別に 1 ページ。dep_<N>.pkl… 依存ページ{PodId: PodDependency}(pod 間参照dep_pids+rank+meta)。index_<N>.pkl…PodId → ページ番号の索引。pid_synonym_<N>.pkl… 重複排除マップPodId → PodId。stats.json… 各ページ数。
- どう保存する(
saveの流れ):Active Variable Filter で対象変数を絞る → Podder+LGA で pod 分割 → 各 pod を dill で直列化 → Change Detector がバイト列を xxh3_128 でハッシュし、既出と同一なら synonym ポインタを書くだけ(=変わらない pod は本体を書かない)、新規ならページに追記。podding はバックグラウンド スレッドで非同期。 - ロード:synonym 解決 → 必要 pod だけページから読み、Unpodder で組み立て、要求変数だけ返す(名前空間全体は読まない)。
- 別バックエンド(選択可):
CompressedFilePodStorage(lz4)、PostgreSQL(pod_storage/pod_dependencies/pod_synonyms/pod_ranksテーブル、本体は 90MB チャンクのBYTEA)、Redis(pod_bytes:/dep_pids:/pod_ranks:/pod_synonyms:キー)、Neo4j。Snapshot/CRIU はベースライン。
自分のコメント
(ここは自分で都度書く欄。例:pod の「構成を安定に保つ」設計が、自分の移行シナリオ(どの状態をどの粒度で運ぶか)にそのまま効きそう。LGA の式(4)(5) は「サイズ×変化率」で隔離を決めるだけなので、ElasticHub のスケーリング判断(どの状態をどの粒度で複製/移送するか)にも翻訳できそう。)