AI解説
情報源:arXiv の HTML 版は存在しない(v1 のみ・PDF/TeX ソースのみ)。本ノートは arXiv の TeX ソース(
aaai22.tex)全文を精読して執筆。図は TeX ソースに同梱の PNG(LaTeX/figs/)から、本文で実際に\includegraphicsされている図のみを取得して掲載した(\iffalseでコメントアウトされた図は除外)。論文 URL: https://arxiv.org/abs/2201.12901。 数値はすべて本文・表の記載値。なお、本文(contributions など)には DSP 解決率を「78%」「77.5%」と書く箇所、HumanEval を最適化した温度設定の話など、abstract(旧版の名残らしい別数値が併記)と本文で齟齬がある箇所があるため、本文 §Experiments の表(Table)の値を正として扱う。
一言で
公開 Jupyter ノートブックを丸ごと学習した seq2seq Transformer「JuPyT5」を訓練し、教育用ノートブックから自動で抽出した実行可能ベンチマーク「Data Science Problems (DSP)」で評価した論文。DSP は 306 ノートブック・1119 問題(自然言語/Markdown の問題文+assert ベースのユニットテスト+データ依存)からなる。300M パラメータの JuPyT5 は、最良構成(3 文脈セル+cell infilling)で pass@100 = 77.5% の DSP 問題を解いた。鍵は (1) 後続のテストセルを見せる cell-infilling 学習(pass@1 が baseline の数倍に跳ね上がる)、(2) 文脈セルを増やす、(3) Markdown リッチなデータに絞る、の 3 つ。
背景
- 知的アシスタント(GMail Smart Compose、GPT-3 など)の流れで、ソフトウェア工学タスク(行補完=GitHub Copilot 系、メソッド/クラス生成=Codex など)への応用が進んでいた。
- コード生成の評価は BLEU/ROUGE のような NLP 指標を超えて、実際にコードを実行してユニットテストを通すかで測る方向へ進化。先行は HumanEval(Codex、164 問の手書き問題+doctest)と MBPP(Mostly Basic Programming Problems、974 問の crowd-sourced 短コード+assert)。両者とも「モデルが大きいほど・サンプル数を増やすほど解ける問題が増える」「複数操作を連鎖させる記述に弱い」ことを示していた。
- ただし HumanEval / MBPP は 汎用コーディングを測るもので、データサイエンスに特化した教育的環境は手薄だった。
問題(problem)
学生にデータサイエンスの問題(Jupyter ノートブック上の課題)を解く提案ができるアシスタントを作れるか? という実現可能性が未検証だった。さらに、そのための評価指標が、データサイエンス・教育ドメインかつ「セル間依存・データ依存・LaTeX 数式」を含む現実的なノートブック環境で存在しなかった。
課題(task = 本論文がやること)
- DSP ベンチマークの構築:教育用ノートブックを自動収集・フィルタして、問題文+ユニットテスト+データ依存を持つ実行可能評価セットを作る。
- JuPyT5 の訓練:公開 Jupyter ノートブックほぼ全量を、新しい cell-infilling 事前学習目的で訓練する。
- 評価:DSP・HumanEval・MBPP で pass@k を測り、文脈量・Markdown 集中・テスト可視の効果をアブレーションする。
論文の貢献(contributions)の要約:
- DSP(教育用 Python ノートブック群。
nbgraderで自動採点。LaTeX/数式・データ依存・問題間の暗黙依存を含む)を新評価として導入。 - cell-infilling 事前学習目的を導入。各セルを 1 例のターゲットとし、ソースは周辺セル+「どのセル型をどこに挿入するか」を示す制御コード。これで訓練したモデルが JuPyT5(Jupyter Python Text-to-text Transfer Transformer)。
- モデルサイズ探索はせず、展開コストの低い 350M パラメータ(埋め込み除き 300M)一本に集中。DSP の 78% を 100 サンプルで解けることを示す。サンプル数・文脈セル数が増えると性能向上。後続セルを 1 つ先読みできるようにすると、3 セル後ろ向き baseline 比で DSP 性能が倍増するのが驚き。テストを見せると性能向上し、前の問題の解を後の問題に流用する挙動も学習。
- HumanEval / MBPP でも評価。MBPP では 300M の JuPyT5 が 68B の巨大モデルに匹敵。HumanEval では同サイズの Codex に負けるが、docstring を Markdown 風にすると差が縮む(=小さいモデルほど書式に敏感)。
- 全種ノートブックで訓練したモデルと、Markdown が多いサブセットで訓練したモデルを比較し、コードと Markdown の量を均すと DSP が改善。
Data Science Problems (DSP) とは
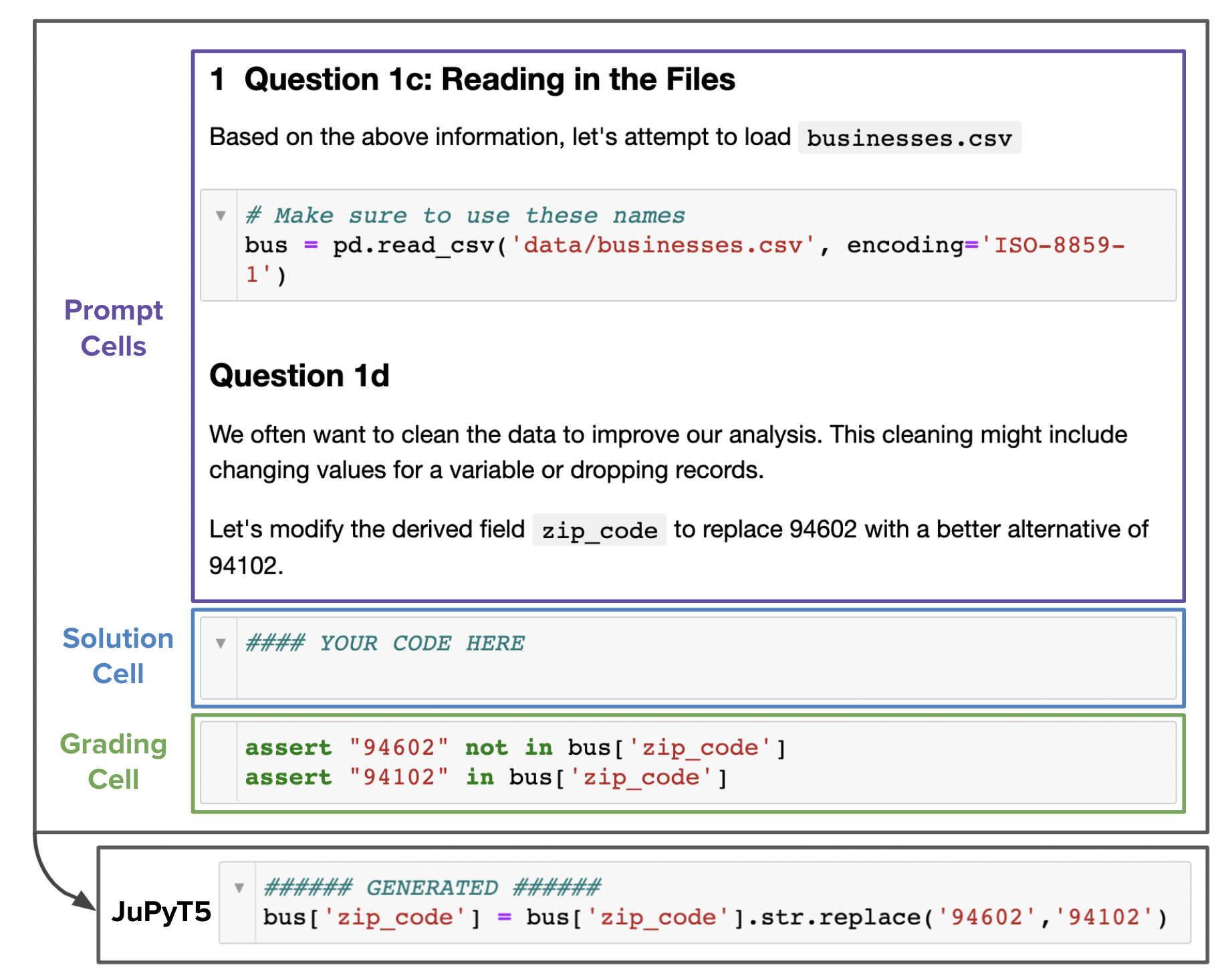
Figure 1:DSP の一例(上)。ファイルを読み込み、Pandas の dataframe のデータクレンジング(zip code の修正)を求める問題で、解は prompt セルと assert を含む採点セルの間に挿入される。JuPyT5 はこの文脈から正しく解を実装している(下)。

Figure 2:DSP の一例(上)。LaTeX で書かれた log-Bernoulli 損失関数の実装を求める問題。JuPyT5 は LaTeX の損失定義を torch を使って正しく解釈し、関数名・引数名も prompt の記述どおりに命名している(下)。
ノートブックの 3 種のセル
nbgrader(教員が課題を作成・検証するツール。コードを実行し instructor の書いた assert を検査する)で作られたノートブックは次の 3 種のセルからなる。
- prompt / context セル:解くべき問題を定義(データ読み込みなどを含む)。
- solution セル:学生(=モデル)が解を埋める。
- grading セル:解を検証するユニットテスト(assert)。DSP では 全ケースで solution セルの直後に grading セルが続く。
DSP の構築パイプライン(フィルタリング)
- JuICe(Jupyter Interactive Computing)開発セットの 448 GitHub リポジトリ=33K の nbgrader ノートブックから開始。
nbclientとデフォルトの Anaconda Python 3.9 環境で全 33K を実行。各セル 600 秒の制限を超えたものは破棄。データ依存を読み込めないノートブック、Python 標準ライブラリや Anaconda デフォルトのデータサイエンス環境に無いライブラリ・非ローカルモジュール・import 失敗を含むものも破棄 → 2134 ノートブックが通過。- 2134 のうち、grading セルの assert が solution セルで定義された メソッド名/関数名/変数名/クラス名を参照しているかでさらに厳格にフィルタ → 306 ノートブック・1119 solution セルを特定。
DSP の統計(Table)
| 項目 | 値 |
|---|---|
| GitHub リポジトリ | 69 |
| ノートブック | 306 |
| 問題-テストペア | 1119 |
| assert 文の総数 | 2298 |
| データファイル総数 | 92 |
| データ参照ノートブック | 70 |
| データ依存ノートブック中の問題数 | 395 |
Table(DSP の出典・特徴の統計)。1 ノートブックあたり平均 3.6 問。35% の問題が何らかのデータファイルに依存(task-grounded)。
DSP の問題内訳(50 問を手作業分類)
| ドメイン | 例 | 割合 |
|---|---|---|
| Math Problems | 微分の計算 | 39.5% |
| Programming Question | マージソート | 26% |
| Data Science | Pandas Groupby | 20% |
| Machine Learning | モデルの構築・訓練 | 12.5% |
| Miscellaneous | HTTP Get Request | 2% |
Table(DSP 50 例の定性分析)。手作業分類の 32.5%(DS+ML)が「35% がデータ依存」という測定とよく一致。
DSP で最頻のモジュール(Table):numpy(253)、matplotlib(180)、scipy(125)、pandas(99)、sklearn(53)、seaborn(47)、nose.tools(47)、math(30)。プロット・数値・データサイエンス系が支配的。
HumanEval / MBPP との違い
- 規模:DSP は 1000 超の問題-テストペアで、HumanEval(164)・MBPP(974) より大きい。
- ドメイン:DSP は教育ドメインかつ task-grounded(35% がデータ依存)。1 ノートブック内の問題列の文脈関係を測れる。
事前学習データセット
- 2021 年 4 月時点の GitHub で「主要言語 = Jupyter Notebook」とラベルされた全リポジトリをクローン。1.97M リポジトリ → 9.06M ノートブック(うちユニーク 7.24M)。
- データリーク防止:JuICe の test/dev セットにあるリポジトリと、それらの重複を訓練セットから除去(DSP 評価の正解漏れを防ぐ)。
- コーパス総セル数 2.21 億。うち 69.5%(1.53 億)がコードセル、残り 0.67 億が Markdown セル。
- PyMT5 の whitespace 拡張・byte-level BPE トークナイザで 総 272 億トークン。約 38%(103 億)が Markdown、169 億がコード。(参考:Codex は 1000 億、Austin et al. の MBPP モデルは 2.81 兆トークンで訓練。)
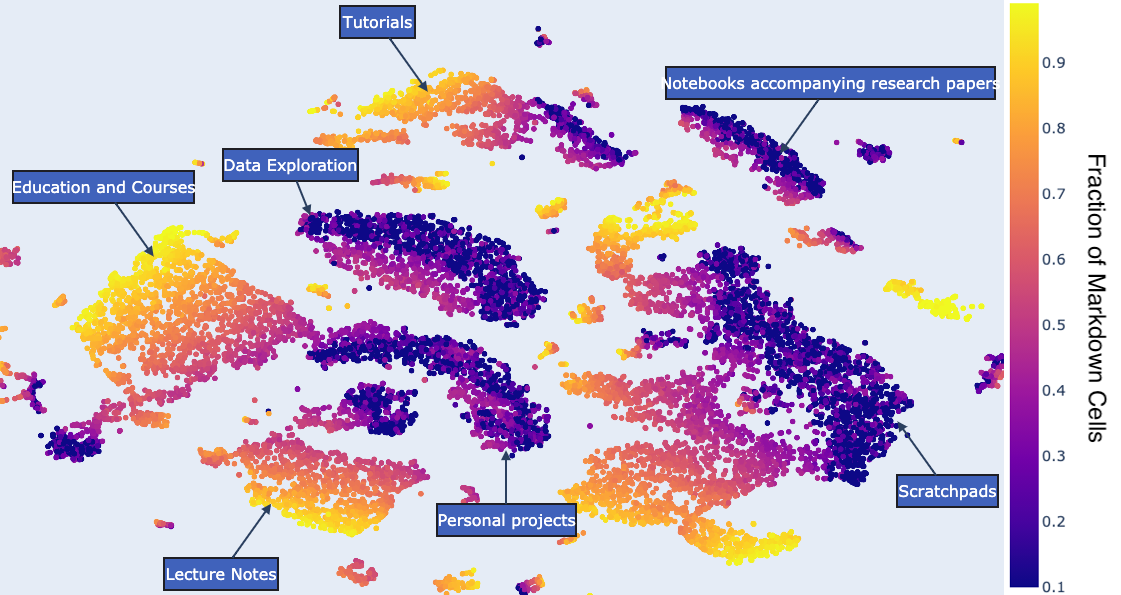
Figure 3:事前学習データから 17K ノートブックをサンプルした t-SNE 可視化。各点が 1 ノートブック、色は Markdown セルの割合。Markdown 量がノートブックを明瞭に分離する。低 Markdown(青)はスクラッチパッド・(意外にも)研究コード・個人プロジェクト、高 Markdown(黄)は教育的ノートブック(チュートリアル・大学課題)。クラスタラベルは各クラスタ約 10 件を目視して手付け。
訓練サブセット:Markdown Focused
訓練データに Markdown リッチ/プアの明確な分離が見えたため、「literate(文芸的)なコードに絞ると DSP 性能が上がるか」を検証するサブセットを定義。少なくとも 1 つのコードセルがあり、かつ全セルの 1/3 以上が Markdown セルのノートブック。4.1M ノートブック(全体の 3/5)・157 億トークン。
モデル(JuPyT5)
- アーキテクチャ:large BART(seq2seq Transformer)。PyMT5 の事前学習済みチェックポイントから開始し、ハイパラも PyMT5 と同じ。
- サイズ:350M パラメータ(埋め込み除き 300M)一本(サイズ探索はしない)。
Cell-Infilling 事前学習
BART は span-masking、PyMT5 は Python メソッドの構文要素(signature / docstring / body)の 1 つをマスクして再構成する目的で事前学習されていた。本論文はこれをセル単位に拡張し、cell-infilling を定義。
- 各セルを 1 つの source-target 例にする。
- source は C=1 文脈セル(baseline JuPyT5) または C=3 文脈セル(ターゲット直前)。最良モデルでは、さらにターゲット直後の 1 セルもソースに含める(cell infilling モデル)。
- これにより cell infilling モデルは「自分が判定される後続の grading セル(テスト)」をソースで見られる。
制御コード(Control Codes)
ターゲットがコードにも自然言語にもなるので、CTRL / PyMT5 に倣い制御トークンでドメインを指示。5 種:<markdown>、<code>、および(本稿外の研究用の)<function>、<class>、<import>。
訓練詳細
- 各 JuPyT5 を 5 エポック(全訓練セット or Markdown Focused サブセット)訓練。
- 80 基の 32GB Tesla V100 GPU。ハイパラは PyMT5 と同じ(データ並列でバッチサイズのみ変更)。
実験・結果
評価設定
- 各 DSP 問題について、ノートブック全文脈をコピーし、当該問題の solution セルだけを JuPyT5 の生成に差し替える。セル間依存でモデルの責任でない実行失敗が伝播するのを避けるため、前の問題は正解(teacher forcing)を見せる。それでも DSP は難しいまま。
- pass@k(Codex の不偏推定指標)で評価。1 試行 = 温度 T=0.8・nucleus sampling top-p=0.95 で 1 仮説生成(HumanEval を最適化して選んだ設定)。
- 実行環境はデフォルト Anaconda Python 3.9 + 元の GitHub リポジトリのコード。
- 合否は grading セルのユニットテストを通すか否かのみ。
DSP の結果(メイン表)
| 文脈 | 訓練方式 | pass@1 | pass@10 | pass@50 | pass@100 |
|---|---|---|---|---|---|
| C=1 | Baseline | 6.5% | 16.5% | 22.7% | 25.3% |
| C=1 | MD Focused | 7.1% | 17.3% | 26.2% | 27.8% |
| C=1 | Cell Infilling | 22.3% | 53.5% | 65.0% | 67.9% |
| C=3 | Baseline | 11.2% | 25.6% | 34.4% | 37.9% |
| C=3 | MD Focused | 11.2% | 28.4% | 40.6% | 43.9% |
| C=3 | Cell Infilling | 33.4% | 63.5% | 73.9% | 77.5% |
Table(DSP 上の JuPyT5、訓練方式と文脈セル数 C 別の pass@k)。最良は C=3 + Cell Infilling の pass@100 = 77.5%。読み取れる傾向:(1) 文脈が多いほど良い、(2) Markdown 集中は穏やかな改善、(3) テストを見せる cell infilling が最大の効果。
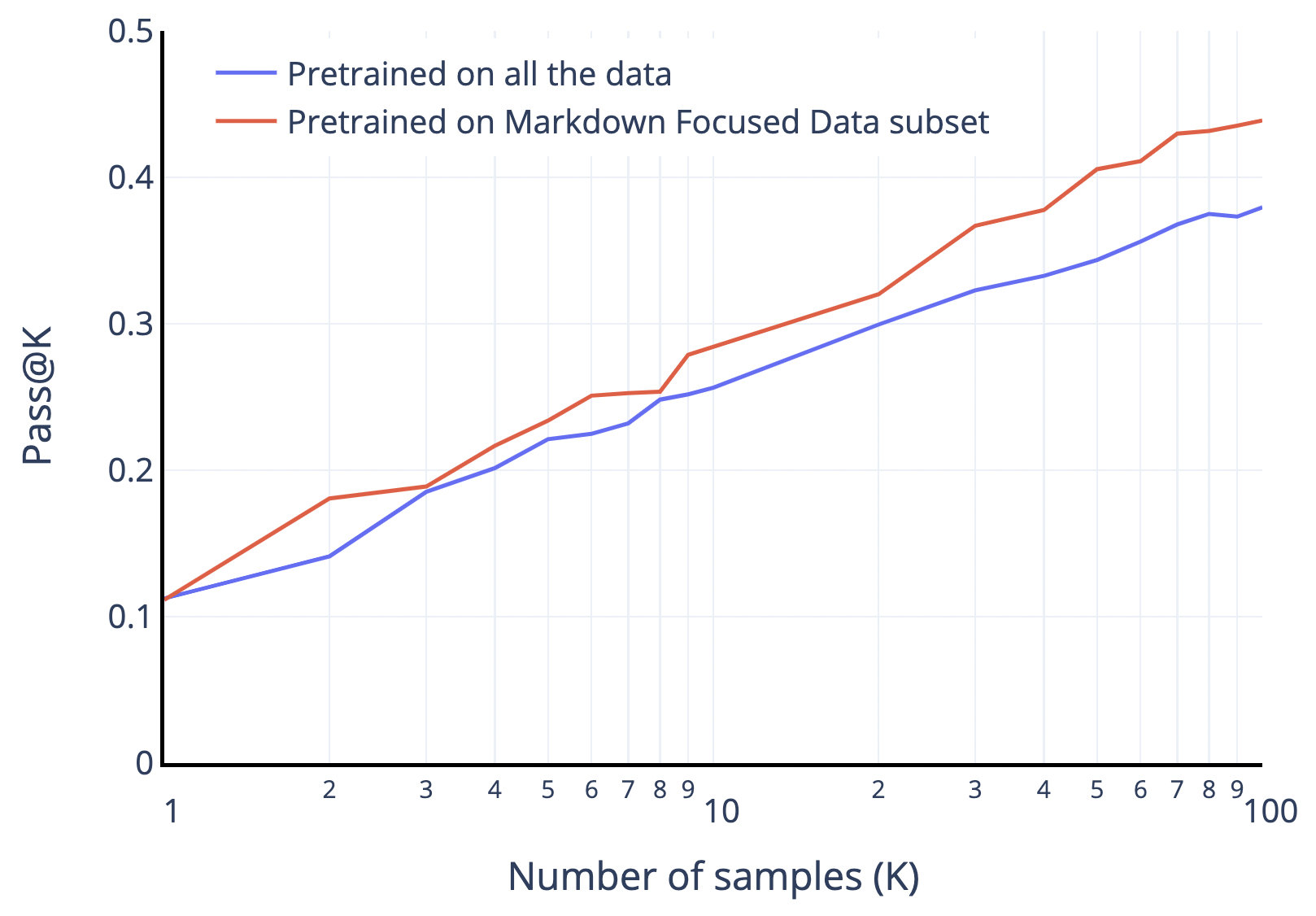
Figure 4:C=3 の 2 モデル(全データ訓練 vs Markdown Focused サブセット)の DSP pass@k 比較。Codex / Austin et al. と同じく pass 率は試行数に対し log-linear。Markdown リッチに絞ると(特に k=100 付近で)穏やかに改善。データ量が 2/5 減でも改善が穏やかだったため、この線は深掘りしていない。
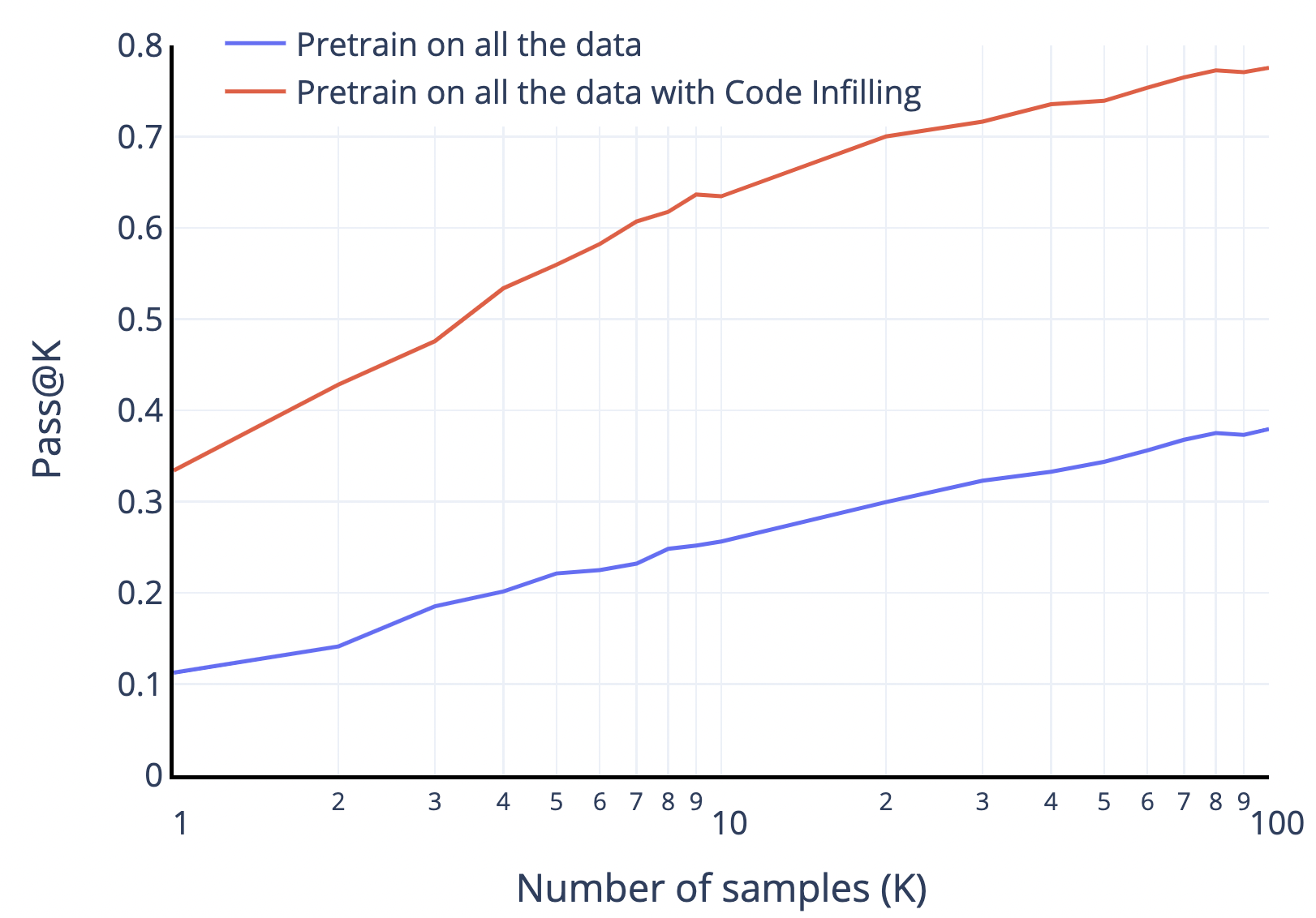
Figure 5:baseline モデルと cell infilling モデル(後続 1 セルを見せる)の DSP pass@k 比較(C=3)。劇的な改善。cell infilling の pass@1 が baseline の pass@100 に匹敵。理由は (1) モデルが判定されるテストを見られる、(2) 後続セルを見ないと assert を自分で生成してしまい(必ずしも正しくない)、それが失敗を招く(Figure 8 参照)。
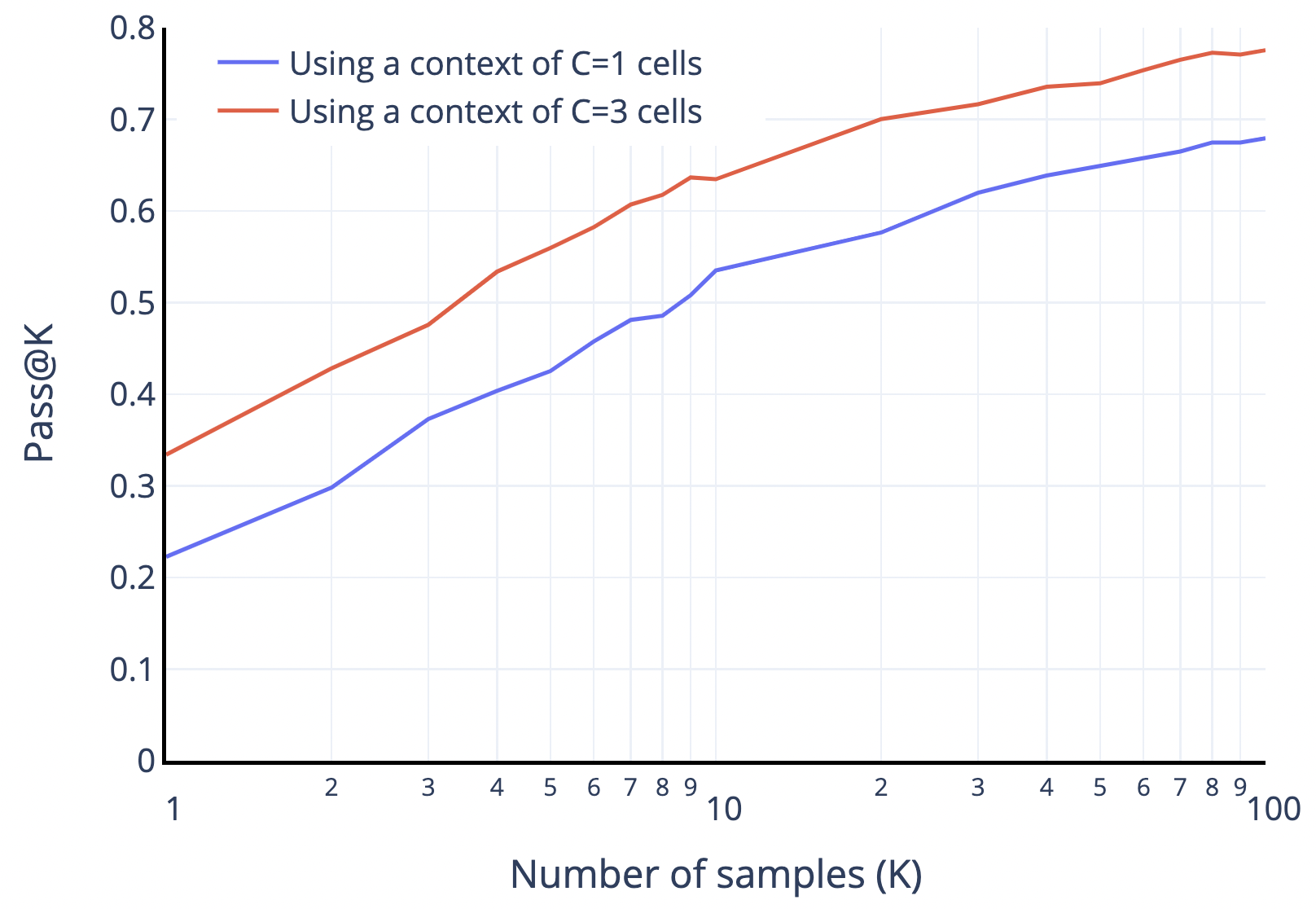
Figure 6:cell infilling モデル(後続テストセルを見せる)で C=1 と C=3(ターゲット前の文脈セル数)を比較。全 k で一貫して約 10% の pass@k 向上。前の問題の解が見えるため理にかなう(テンプレ流用挙動、Figure 9 参照)。
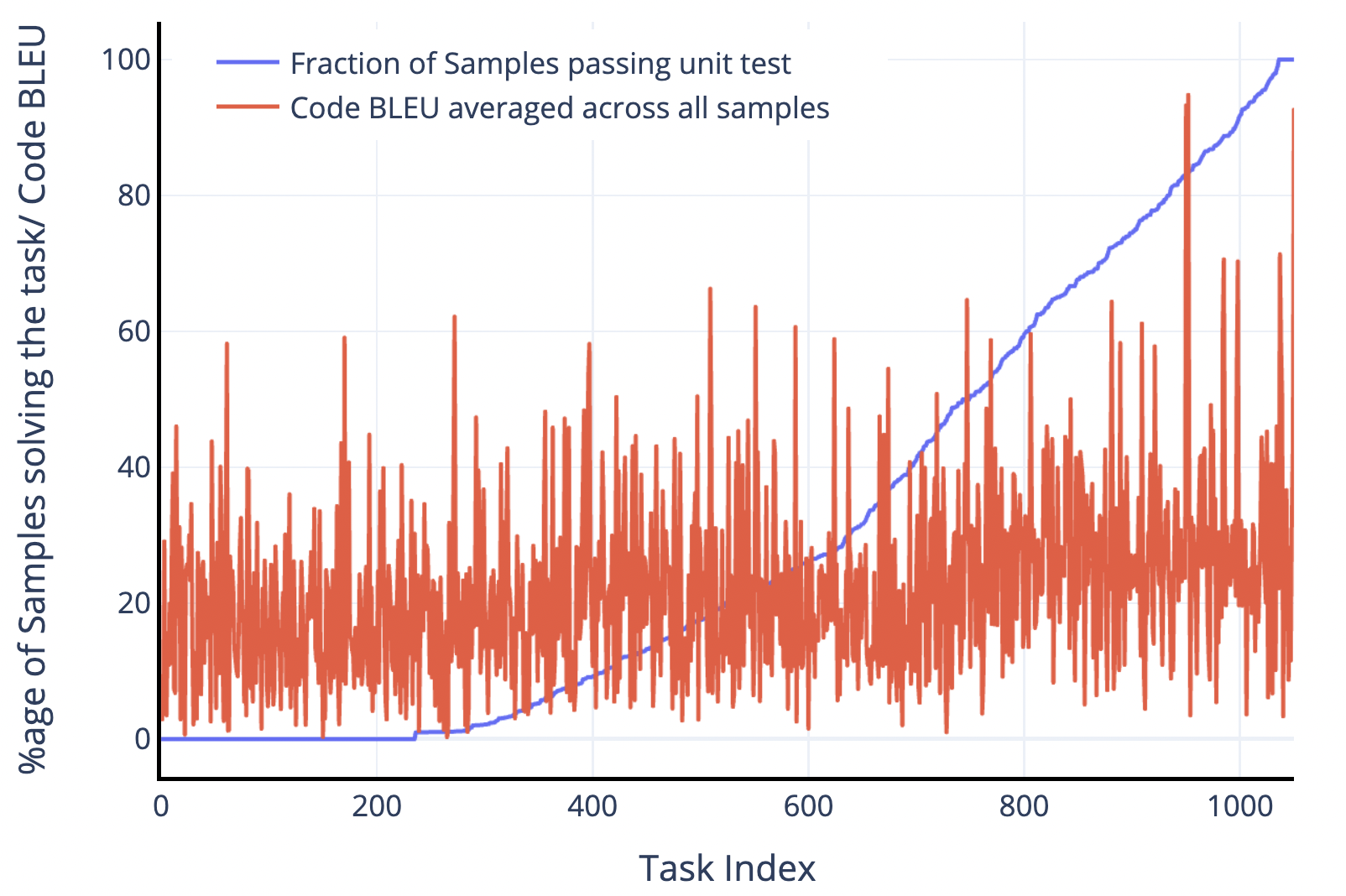
Figure 7:青曲線は全 DSP タスクを JuPyT5 の 100 サンプル pass 率順に並べたもの。赤線は正解コードと各仮説の平均 CodeBLEU。両者の相関は弱く、BLEU/CodeBLEU は仮説プログラムの正しさ判定に有用でないことを示す。
HumanEval / MBPP の結果
HumanEval(pass@k、対 Codex):
| モデル | k=1 | k=10 | k=100 |
|---|---|---|---|
| Codex-85M | 8.22% | 12.81% | 22.4% |
| Codex-300M | 13.17% | 20.37% | 36.27% |
| JuPyT5-300M | 5.4% | 15.46% | 25.6% |
Table(HumanEval)。同サイズ(300M)の Codex に JuPyT5 は負ける(85M Codex には勝つ)。Markdown とメソッド docstring の書式差が一因で、docstring を Markdown 風にすると差が縮む(=小さいモデルほど書式に敏感)。
MBPP(pass@k=80、80 サンプル。PS = Program Synthesis モデル):
| モデル | pass@80 |
|---|---|
| PS-422M | 15% |
| PS-4B | 33% |
| PS-68B | 54% |
| PS-137B | 63% |
| JuPyT5-300M | 52.2% |
Table(MBPP)。300M の JuPyT5 が 68B の巨大 PS モデルに匹敵(54% に対し 52.2%)。PS はコードを含む多様な英語文書で訓練されたのに対し、JuPyT5 はコードドメインに集中しているため。
考察
- 77% 超は pass@100 という最も楽観的な指標であり、100 仮説を許せない展開シナリオもある。ただしユーザが問題とテストを与える test-driven development 型なら、JuPyT5 は有効なアシスタントになりうる。
- モデルは前の解からブートストラップする(サンプル数によらず一貫して pass 率が上がる)ため、ユーザがプログラムを進めるほど有効になりうる。
- テストなしの単一仮説選択(トークンあたり対数尤度最大のサンプルを選ぶ)も試したが、1 サンプル評価に対し穏やかな改善のみ。

Figure 8:baseline JuPyT5 が仮説コードと一緒に assert 文まで予測してしまう例。訓練データにユニットテストが多いことの表れ。cell infilling が大きく改善するのは、後続の grading セルが見えると、モデルが(誤りうる)assert を余計に予測しなくなるため。

Figure 9:JuPyT5 がテンプレート的挙動で予測する例。prompt のコードと解が明らかに類似し、モデルは関数内のコメントまで(ほぼ正しく)適応している。


Figure 10:JuPyT5 がほとんど解けなかった DSP の「難問」2 つ。上は least-squared 損失関数の中にモデルが入っており、複数のロジック連鎖を組み立てるのが苦手(Codex / Austin et al. も報告)。下は難しくないが問題文に定義がなく、モデルが L1 ノルムの定義を「知っている」ことに依存する(大きなモデルなら改善しやすい類)。なお最易問は「列を落とす」など一般的な Pandas dataframe 操作だった。
まとめ
- 1000 問超・多くがデータ依存・全問実行可能でユニットテスト付きの新コード生成指標 DSP を導入。
- 公開 Jupyter ノートブックほぼ全量で JuPyT5 を訓練し、77% 超の DSP を解けることを示した。
- 楽観的見積もりではあるが、巨大 Transformer によるデータサイエンス・アシスタントの実現可能性を示す。複雑なコード合成(連鎖ロジック)の課題は残り、DSP がコミュニティの研究を後押しする。
Q&A
(まだなし)
自分のコメント
(まだなし)