AI解説
arXiv 版あり: https://arxiv.org/abs/2503.20591(実装: https://github.com/ds2-lab/NotebookOS) 情報源: arXiv 全文(HTML v2)を WebFetch で参照し、trace 数値・式・結果・図を確認済み。状態同期の大小判定とリモート実行の通信方式は論文本文に詳述がないため、実装リポジトリ(
ds2-lab/NotebookOS)のコードも確認して補った(該当箇所は「実装で確認」と明記している)。 図について: 基本は原論文(arXiv v2)の図を貼り(figures/x*.png、図番号・キャプションは原論文に対応)、論文図だけでは分かりにくい箇所は AI 生成の補足図(figures/replica-gpu.svg)で補っている。図はコミットして公開サイト(GitHub Pages)にも表示する。サイトは noindex メタ+robots.txtで検索除けされている。
一言で
対話的な深層学習トレーニング(IDLT: Interactive Deep Learning Training)向けのノートブック プラットフォーム。GPU をセッションに固定確保するのをやめ、セルを実行している瞬間だけ GPU を束縛する。各論理カーネルを 3 つの Raft 複製レプリカとして分散配置し、レプリカの動的選挙で実行担当を決める。こうして応答性を保ったまま GPU をオーバーサブスクライブする。実運用ワークロードの 17.5 時間で 1,187 GPU 時間以上を節約し、それでいて対話性も維持できたという。
背景・問題
Jupyter や Colab のようなプラットフォームは、長時間走るノートブック セッションに対して GPU を予約(reserve)しっぱなしにする。まずは前提となる Jupyter のクライアント・サーバ構成を押さえておく。
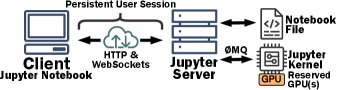
Figure 1: Jupyter のクライアント・サーバ型アーキテクチャ。クライアント(ノートブック UI)が長命なカーネルに接続し、セル実行のたびに execute_request を送る。
応答性のためには GPU を握り続けざるを得ない。だが IDLT のワークロードは、GPU 使用が断続的で散発的だ。論文が挙げる production トレースの実態は具体的だ。
- 予約された GPU は 8 割以上(>81%)の時間アイドル。
- 約 7 割の GPU はセッションの全期間を通じて完全にアイドルで、3 か月のトレース終盤に実際に使われたのは約 15%。
- タスク実行時間は中央値 2 分、75 パーセンタイル 5 分、90 パーセンタイル 17 分。一方、セル実行の到着間隔(IAT=inter-arrival time)は中央値 5 分、75 パーセンタイル 8 分と長い。ここでいう IAT は「あるセルを実行してから、次にセルを実行するまでの間隔」を指す(ユーザのログイン到着ではなく、実行イベントの到着間隔)。その中身の大半は考え事やコード編集の think time だ。IAT は「タスクとタスクの間の時間」という待ち行列論の一般概念で、実行時間そのものではない。トレースによって「タスク(到着イベント)」の単位が違う。AdobeTrace ではタスク=セル実行だが、後述のバッチ型 AlibabaTrace / PhillyTrace ではタスク=バッチ ジョブの投入なので、それらの IAT は「ジョブ投入の間隔」を指す(粒度が違うだけで概念は同じ。論文はこれを「やや非対称な比較」と認めている)。3 トレースとも IAT は「ユーザ セッションごとに独立して」測られる。原文は “the IATs were measured within each user session independently, … to ensure a fair comparison.”。クラスタ全体ではなく、1 ユーザが連続投入する間隔で揃えて比較する、という意味らしい(Q51)。
これらの特性は実トレース 3 種から定量化されている。3 種は性格が異なる。主役は IDLT(対話的)の AdobeTrace で、残り 2 つは従来のバッチ訓練との対比用だ。
- AdobeTrace:Adobe 社内研究クラスタの IDLT ノートブック本番トレース。2021 年 6〜8 月、545,467 件のトレーニング イベント、15 秒粒度。AWS EC2 GPU VM 上のコンテナ化ノートブック。本論文の主評価データ。
- AlibabaTrace(2020):Alibaba 本番クラスタの training + inference ジョブ。6,500 GPU / 1,800 サーバ、2020年7〜8月。従来型バッチ訓練(BDLT)の比較ベースライン。
- PhillyTrace:Microsoft 社内 Philly クラスタの first-party 深層学習訓練(DLT)。117,325 ジョブ / 2,490 GPU / 552 サーバ、2017年8月7日〜12月22日。長時間バッチ訓練の比較ベースライン。
AdobeTrace が「対話的で短く散発的」、Alibaba/Philly が「バッチで長時間」という対照になっていて、IDLT が従来のクラスタ ワークロードと根本的に違うことが見て取れる。
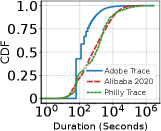
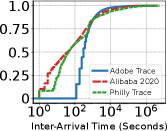
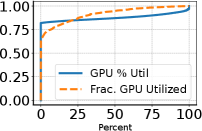
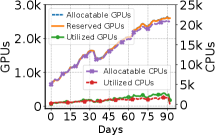
Figure 2: GPU クラスタ実トレース 3 種のワークロード特性。(a) タスク実行時間 CDF、(b) セル実行の到着間隔(IAT)CDF、(c) GPU 使用率 CDF(AdobeTrace)、(d) GPU・CPU 使用量(AdobeTrace)。タスクは短く(中央値2分)、間隔は長い(中央値5分)。
3 トレースが登場するのは (a)(b) だけで、(c) GPU 使用率と (d) GPU・CPU 使用量は AdobeTrace のみ(キャプションに明記)。Alibaba/Philly の利用率や使用量は論文に報告がない。(a)(b) は「バッチで長時間 vs 対話的で散発的」という対照のための比較なので 3 トレースを並べ、(c)(d) は「予約 GPU が 8 割以上アイドル」という中心的な問題提起なので主評価データの AdobeTrace で示す。そう読める構成だ(後者の意図は本文に明記がなく、こちらの解釈。Q52)。
トレースの規模感(夏季全期間のアクティブな学習数とセッション数の推移)はこちら。
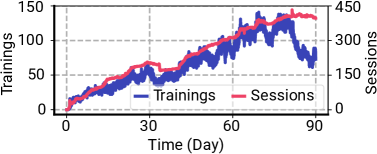
Figure 20: 夏季全期間(6〜8月)の、アクティブなユーザ投入トレーニング数とアクティブ ユーザ セッション数の推移。
ここで sessions(セッション)は、長命でステートフルなノートブック セッションそのものを指す(ユーザが居続ける「箱」、同時アクティブ最大 90)。trainings(トレーニング)は、その箱の中で時々走る GPU 計算タスクを指す(モデル訓練を伴うセル実行、同時アクティブ最大 141)。1 セッションの寿命の中で複数のトレーニングが時系列で発生しうるので、「箱はたくさんあるが、実際に GPU を使う実行はそのうち一部」という関係になる。これが「セッション基準で GPU を握り続けるのではなく、トレーニング(実行)中だけ束縛する」という設計動機につながる。
つまり、対話性のために GPU を握り続けると利用率が極端に低くなり、その結果コストが膨らむ。この連鎖が問題だ。かといって素朴にアイドル時に GPU を剥がすと、次にセルを実行するとき GPU を取り直す遅延が出て対話性が壊れる。この両立が狙いになる。
提案手法
NotebookOS の全体像は次のとおり。グローバル スケジューラの下に複数の GPU サーバが並び、各論理カーネルが複数サーバにまたがる複製レプリカとして配置される。
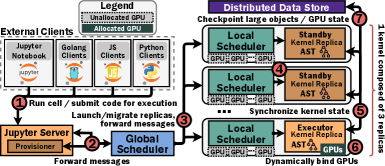
Figure 3: NotebookOS のアーキテクチャ全体像。グローバル スケジューラ+ローカル スケジューラ群の上に、複製された分散カーネルが乗る。
図中の①〜⑦は、セル実行要求が処理されるまでの制御・データの流れを表す。
- ① Run cell / submit code for execution:クライアント(Jupyter Notebook / Golang・JS・Python クライアント)が HTTP / WebSocket でセル実行要求を Jupyter Server に送る。
- ② Forward messages:Provisioner を内蔵する Jupyter Server が、その要求を Global Scheduler へ転送する。
- ③ Launch/migrate replicas, forward messages:Global Scheduler が(必要なら)3 レプリカの起動・マイグレーションを行いつつ、対象サーバを管理する Local Scheduler 群へメッセージを転送する。
- ④(Local Scheduler → kernel replica):Local Scheduler がメッセージを自サーバ上の対象カーネル レプリカ(実行担当 = Executor)へルーティングし、そのレプリカが実行を担う。
- ⑤ Synchronize kernel state:レプリカ間で Raft(リーダー選挙+状態機械レプリケーション SMR)により小さい CPU 側のカーネル状態を同期する。
- ⑥ Dynamically bind GPUs:ユーザのセル実行が走っている間だけ、Executor レプリカのコンテナに GPU を動的に束縛する(終われば解放)。
- ⑦ Checkpoint large objects / GPU state:大きいオブジェクト(モデル・テンソル等)/ GPU 状態を、プラガブルな分散ストア(Distributed Data Store)へ非同期に退避(チェックポイント)する。
右端の縦書き注記「1 kernel composed of 3 replicas」は、1 論理カーネルが 3 レプリカ(Executor 1 + Standby 2)で構成されることを示す。
スケジューラの動作場所:Global Scheduler はクラスタに 1 つ(中央)で、分散カーネルの生成、レプリカのプロビジョニング開始、資源(CPU/メモリ/GPU)の割当、障害処理、レプリカ マイグレーション、オートスケールを司る。Local Scheduler は各 GPU サーバに 1 つずつ配置され、Global Scheduler から来たメッセージを自サーバ上の対象カーネル レプリカへ転送し、コンテナのプロビジョニングを担う。
この研究で新しく作った部分:Figure 3 のうち、新規なのは Global Scheduler/Local Scheduler、複製分散カーネル(3 レプリカ+Raft SMR+AST)、実行担当の選挙プロトコル、動的 GPU 束縛、CPU 小状態は Raft・GPU 大オブジェクトは分散ストアというハイブリッド状態複製、Jupyter Server 内の Provisioner。一方、External Clients(Jupyter Notebook 等のクライアント)、Jupyter Server/IPython カーネルの素体、Raft アルゴリズム自体、Distributed Data Store の中身(Redis/S3/HDFS)、Docker コンテナは既存のものを利用している。論文自身の貢献は「(1) IDLT というワークロード類型の特徴づけ、(2) IDLT 向けに設計した NotebookOS の設計・実装、(3) 実 production ワークロードでのプロトタイプ+シミュレーション評価」の 3 点だ。
カーネルの起動経路(provisioner / spawner の話):図中の Provisioner は Jupyter の「カーネル プロビジョナ(Kernel Provisioning)」を指す。jupyter_client(7.0 以降)の仕組みで、カーネル プロセスの起動とライフサイクル管理を担うコンポーネントだ。既定は LocalProvisioner(カーネルをローカルの子プロセスとして起動)で、カスタム実装すればコンテナやリモート、k8s などにカーネルを起こせる。jupyter_client.kernel_provisioners エントリポイントで登録し、kernelspec から選択する。
NotebookOS は JupyterHub の Spawner(DockerSpawner / KubeSpawner 等)は使っていない(Spawner は JupyterHub がユーザの ノートブック サーバ を起こす別概念)。代わりに、このカーネル プロビジョナを自前実装した GatewayProvisioner(KernelProvisionerBase を継承、エントリポイント名 gateway-provisioner)を使い、これが StartKernel RPC を Global Scheduler に投げる。なお jupyter-server/gateway_provisioners(リモート カーネル起動用の既製パッケージ)とは別物で、名前は似ているが NotebookOS はそれに依存せず独自クラスを持つ(同じ「ゲートウェイ型のカーネル プロビジョナ」という系統ではある)。実体のコンテナ起動は、各サーバの Local Scheduler が StartKernelReplica RPC を受けて行う。オーケストレーションは Docker Swarm / Docker Compose(Kubernetes も対応)。つまり、JupyterHub spawner で単一カーネルを起こすのではなく、カスタム プロビジョナ → Global/Local Scheduler → 複数サーバに 3 レプリカのコンテナを起動、という独自経路をとる。
カーネルを別サーバで動かす仕組み(リモート実行の通信):通常の Jupyter は Jupyter Server と IPython カーネルを同じホストで起動し、両者を ZMQ(ZeroMQ)の 5 チャネルでつなぐ。NotebookOS ではカーネル(レプリカ)が別の GPU サーバ上で動く。これを SSH ではなくゲートウェイ方式で実現している(実装 ds2-lab/NotebookOS で確認)。カスタム プロビジョナ GatewayProvisioner が gRPC(既定 8080 番)で「Cluster Gateway」= Global Scheduler に接続し、各 GPU サーバの「Local Daemon」= Local Scheduler 経由でレプリカ コンテナを起動・制御する。ユーザのセル実行など Jupyter のメッセージは ZMQ ソケットで結線され、Global Scheduler → Local Scheduler → 対象レプリカへ転送される(Figure 3 の②③④の「Forward messages」がこれ)。発想としては Jupyter Enterprise Gateway / Kernel Gateway(Cybershuttle Notebook Gateway もこの系統)と同じで、リモート カーネルをゲートウェイ越しにプロキシするアーキテクチャだ。制御を gRPC、カーネル メッセージングを ZMQ 転送で担うのが NotebookOS の実装になる。

補足図(AI生成): リモートカーネルのゲートウェイ構成。制御は gRPC(GatewayProvisioner → Cluster Gateway=Global Scheduler → Local Daemon=Local Scheduler)、セル実行メッセージは ZMQ で対象レプリカへ転送。SSH ではない。(Q19・Q21・Q23)
provisioner の実体と、標準との違い:provisioner は独立したサーバではない。Jupyter Server プロセスの中にロードされる Python のプラグイン(KernelProvisionerBase を継承したクラス)で、「カーネルをどこに、どう起こすか」を差し替える部品だ。標準の LocalProvisioner は同じホストにカーネルを子プロセスとして fork するだけ。対して NotebookOS の GatewayProvisioner は、起こす代わりに gRPC で StartKernel を Global Scheduler へ投げるよう振る舞いを差し替えてある(GPU 割当、配置、選挙を決めるのは provisioner ではなく Global Scheduler 側)。この差を並べると次のとおり。なお論文の主役は「GPU サーバ」(Global Scheduler 配下に並び、Local Scheduler が 1 台ずつ常駐するマシン群)で、「CPU サーバ専用ノード群」という物理二分は本文に明示がない(GPU を持たない Jupyter Server はフロントとして別に居る、とは言える。「CPU 状態/GPU オブジェクト」は 状態の所在 の区別であって サーバの種類 ではない)。

補足図(AI生成): 標準 Jupyter(LocalProvisioner)は Jupyter Server と同じホストにカーネルを子プロセスで起こし GPU を予約しっぱなし。NotebookOS(GatewayProvisioner)は gRPC で Global Scheduler(Cluster Gateway)→ 各 GPU サーバの Local Scheduler(手足、k8s の kubelet 相当)→ 3 レプリカのコンテナを起動し、セル実行メッセージは ZMQ で転送、Raft はレプリカ間で直接同期する。(Q63・Q64)
この「クライアント → スケジューラ → 3 レプリカ(executor は空き GPU を束縛し、standby は Raft で同期)→ 分散ストア」という関係を、Figure 3 を読み解く補足図として描いておく。

補足図(AI生成): 1 論理カーネル K が 3 サーバに R1/R2/R3 として分散。セル実行要求は Global Scheduler → 各 Local Scheduler 経由でレプリカへ届き、空き GPU のあるサーバのレプリカ(ここでは R1)が executor となって GPU を束縛・実行する。R2/R3 は standby で、Raft で CPU 状態を同期。大オブジェクトは分散ストアへ退避し Raft ログにはポインタだけを載せる。全レプリカが GPU を取れない時だけ、空きサーバへマイグレーションする(フォールバック)。
「セル実行ボタンを押してから実行結果が表示されるまで」の時系列を、Figure 3 の①〜⑦と Figure 15/18 のE2E内訳に沿ってシーケンス図にすると次のとおり。

補足図(AI生成): セル実行ボタン → 実行結果表示までのシーケンス。① Client が execute_request を Jupyter Server へ送り、② Provisioner 経由で Global Scheduler、③(必要ならレプリカ起動/移行を伴い)Local Scheduler 群へ、④ 3 レプリカへ配送。選挙で R1 が executor(GPU を取れない R2/R3 は yield_request 化)、⑥ GPU を動的束縛し host→VRAM ロード(数百ms)してコード(訓練)を実行、⑤ 小さい CPU 状態を Raft 同期・⑦ 大オブジェクトを分散ストアへ非同期 checkpoint(ログにはポインタだけ)。実行後 GPU を即解放(to_cpu() でモデルを VRAM→host RAM へ退避し empty_cache() で VRAM を空ける。モデルは消さず host に残すので次の実行は host→VRAM コピーだけで済む。durable な原本は ⑦ で分散ストアにある)し、execute_reply が ⑩ Local Scheduler → Global Scheduler → Jupyter Server → Client と返って結果が表示される。対話遅延(Fig 9a)は「①送信〜⑥実行開始」まで(標準で 89.6% が即 GPU 確保=移行不要。ただし即確保でも選挙+host→VRAM のぶん遅延は 0 ではない)、Raft 同期・大オブジェクト I/O は IAT(中央値5分)の隙間に隠れるのでクリティカルパスには乗らない。(Q54)
1. 複製カーネル — 1 論理カーネル = 3 レプリカ
ここでいう「カーネル」は、Jupyter(ノートブック)のカーネル、つまりセルを実行するプロセスを指す。GPU/CUDA の「カーネル(GPU 上で走る関数)」ではない。「1 kernel composed of 3 replicas」も、1 つの論理的な Jupyter カーネルを 3 レプリカに分散実体化する、という意味だ。GPU はその Jupyter カーネルのコンテナに実行中だけ束縛される「資源」という位置づけになる。
ここでいう「レプリカ」とは、その論理 Jupyter カーネルのコピー、すなわちコンテナ化された IPython カーネル プロセスの 1 インスタンスを指す(モデルやデータを複製した「データのレプリカ」ではなく、カーネルそのものの複製)。既定ポリシー(LongRunning)では各レプリカはセッション中ずっと生きる長命コンテナで、Raft で状態を同期し続ける(コンテナの寿命とセル/セッションの対応は §2 を参照)。各論理カーネルはこのレプリカを 3 つ持ち、別々の GPU サーバに分散配置する。選挙に勝った 1 つが executor レプリカ(コードを実行し、実行中だけ GPU を束縛)、残り 2 つが standby レプリカ(待機し、Raft で状態を同期)。
なぜ 3 なのか:Raft は過半数(quorum)で合意するため、最低でも 3 必要だ(2 では Raft が成立しない)。一方 5 にすると、メモリやストレージ、ネットワークのコストが大きく増えるわりに性能的な見返りが乏しい。3 なら 1 台の fail-stop 障害まで耐えられる(残り 2 で過半数を維持)。つまり「合意が成立する最小、かつ 1 故障耐性を得られる最小」として 3 が選ばれている。同時に 3 レプリカは、セル実行のたびに空き GPU を探せる候補サーバが 3 つある、という意味も持つ(次節)。

補足図(AI生成): Raft の役割(リーダー=Executor 経由で書き込み→過半数で commit)と、レプリカ数を 3 にする理由(2 は合意不可・3 が最小で 1 故障耐性・5 は過剰)。(Q7・Q16)
どの 3 サーバに置くか(レプリカ配置アルゴリズム、論文 §3.2.1):クラスタの N 台の GPU サーバから 3 台を選び、1 サーバに 1 レプリカずつ置く(3 台に分散)。選び方は 2 段階だ。(1) 候補(viable candidate)の絞り込み。Global Scheduler が全サーバを走査し、ユーザの resource request(CPU=millicpu/メモリ=MB/GPU 数/VRAM=GB)を満たす容量があり、かつクラスタ全体の SR(subscription ratio)≤ 1 を崩さないサーバを候補にする(原文: “If a server meets the requirements, this server becomes a candidate.”)。(2) 候補が 3 より多ければ(N>3)pluggable なポリシーで 3 台選抜し、既定は least-loaded(“the least-loaded hosts—those with the fewest actively used GPUs—are chosen”=今アクティブに使用中の GPU が最少のサーバ)。選んだ各サーバの Local Scheduler に StartKernelReplica RPC を 1 つずつ発行する。候補が 3 台に満たなければ pluggable handler を起動してスケールアウト(“initiate a scale-out operation to provision however many additional servers are required”)し、必要数のサーバを増設してから配置する(§4 のスケールアウト契機 (1))。つまり bin-packing やランダムではなく、負荷分散寄り(least-loaded)が既定で、ポリシーは差し替え可能だ。least-loaded にするのは、実行時に各レプリカが GPU を取れる確率を上げ、移行なしの即時 executor 化(標準 89.6%)を狙うためと整合する。

補足図(AI生成): N サーバから 3 台を選ぶ手順(論文 §3.2.1)。① 全サーバ走査 → ② resource request(CPU/メモリ/GPU/VRAM)+SR≤1 を満たすものを候補化 → ③a 候補が 3 超なら既定 least-loaded で 3 台選抜/③b 3 台に満たなければスケールアウト → ④ 各サーバの Local Scheduler に StartKernelReplica を 1 つずつ(1 サーバ 1 レプリカ・別サーバに分散)。(Q66)
3 レプリカの資源コスト(VRAM/RAM は無駄にならない?):余分な資源は確かに使う。ただし一番高い GPU/VRAM は 3 倍にはならない。ここがポイントだ。VRAM を使うのは executor が実行している間だけで、実行が終われば to_cpu()+empty_cache() で解放する(standby は VRAM を使わない)。一方、host RAM にはモデルの実体が(最大)各レプリカに載るので実質 ~3 倍になる。実装では、モデルのポインタが Raft でコミットされた時点で、提案元でない(standby 側の)レプリカが __load_model_from_remote_storage でストアからモデルをダウンロードし、自分の名前空間(host RAM)に実体化する(durable な原本は分散ストア、Raft ログにはポインタだけ。§3)。これは即時フェイルオーバーや即時 executor 昇格(host→VRAM コピーだけ)を可能にするための先読みで、純粋な無駄ではない。つまり 3 倍化のコストは host RAM やストレージ、ネットワーク側へ寄せ、希少な VRAM を空ける、という配分だ。論文も replication factor=5 を「メモリ・ストレージ・ネットワーク コストが大きく増えるわりに見返りが乏しい」と退けており、3 を最小コストの妥協点としている。要は、潤沢で安い host 資源を払って希少で高い GPU を解放する、というトレードオフだ。
各ノートブック(Jupyter)カーネルを、GPU サーバに分散した 3 つのレプリカとして実体化する(3 は Raft が過半数合意を取れる最小構成)。レプリカ間は Raft(合意=コンセンサス プロトコル)で状態を同期する。レプリカを複数持っておけば、セル実行のたびに「今 GPU が空いているサーバのレプリカ」を実行担当に選べるので、特定サーバの GPU 解放を待たずに済む。この「1 論理カーネル = 3 レプリカ、GPU は実行中だけ束縛」という考え方を、原論文の図にはない補足図として描いておく。

補足図(AI生成): 1 論理カーネルが 3 レプリカとして別々の GPU サーバに分散し、セル実行中のレプリカだけが GPU を束縛する様子。
カーネル生成時の手順(Docker Compose / Docker Swarm の両モード)はこう進む。
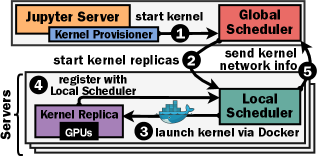
Figure 4: NotebookOS の Docker Compose / Docker Swarm モードにおける新規カーネル生成プロセス。3 レプリカを別々の GPU サーバに配置する。
2. GPU はセル実行中だけ束縛 + 動的選挙
GPU をセッション全体ではなく、アクティブなセル実行中だけ割り当てる。具体的には、レプリカがユーザのコードを実行する直前に GPU を束縛(bind)し、タスクが終わった瞬間に解放する。これが「dynamically bind GPUs」だ。従来(予約方式)はカーネル=セッションの生存中ずっと GPU を予約し続ける(考え事やコード編集の think time も握りっぱなし)。この before / after を図にすると次のとおり。

補足図(AI生成): ①通常(予約方式)はセッション全体で GPU を占有し、実行していない大半の時間も握り続ける(縞模様=無駄)。②NotebookOS はセル実行中だけ GPU を束縛し、終われば即解放して空き時間は他カーネルに回す。
束縛/解放の実装+コンテナ寿命はポリシー依存(GitHub ds2-lab/NotebookOS で確認):コンテナの寿命はスケジューリング ポリシーの ContainerLifetime で決まり、ここが「動的束縛」の実体を左右する。
- 既定の NotebookOS(Dynamic 系ポリシー)=
LongRunning:1 レプリカ=1 つの長命コンテナをセッション中ずっと保持する(セルごとに作り直さない)。コンテナ自体は--gpus all付きで起動されるが、VRAM を実際に使うのは実行中だけだ。実行直前にモデルを host RAM → VRAM にロードし(PyTorch、数百ms)、実行後にto_cpu()+torch.cuda.empty_cache()で VRAM を解放する。あわせてスケジューラが GPU 割当をコミット/デコミット(execute_reply時に解放)してオーバーサブスクライブの会計を保つ。つまり「動的束縛」はモデルの VRAM 出し入れと割当会計で実現しており、走っているコンテナのデバイス集合を実行ごとに付け替えているわけではない。 - NotebookOS(LCP) / Batch / Gandiva =
SingleTrainingEvent:コンテナは 1 トレーニング(≒1 セル実行)単位。Batch/Gandiva は毎回作って捨てる。LCP(実装の MiddleGround = “Large Container Pool”)は暖機済みコンテナのプールから借りて、実行後にプールへ返す。この単発系は--gpus 'device=0,2'(DockerInvoker.InitGpuCommand)のように特定デバイスを付けて invoke する。 - Reservation(比較対象)=
LongRunning+--gpus all:長命コンテナで GPU をセッション中ずっと予約。
物理束縛は Docker の --gpus(all か device=N)で、裏で NVIDIA Container Toolkit が NVIDIA_VISIBLE_DEVICES を設定、GPU 情報取得は NVML/go-nvml。解放するのは実際に実行した executor だけ(YIELD したレプリカは対象外)。
モデルはいつ VRAM に載る? 復元をどうクリティカルパスから外す?:モデルの実体は host(CPU)main memory と Distributed Data Store にあり、VRAM に載るのは実行の瞬間だけだ(実行直前に host→VRAM、数百ms。論文いわく「a couple hundred ms」でクリティカルパス上だが、IAT に比べれば無視できる)。重いのは分散ストアとの読み書き(Figure 11:99% が読み 3.95s・書き 7.07s 未満)だが、これを到着間隔(think time / IAT、中央値 5 分)の隙間に非同期で重ねて隠す。実装ではポリシーが ReadOperationIsOnCriticalPath / WriteOperationIsOnCriticalPath フラグを持ち、状態の読み(復元)と書き(チェックポイント)をクリティカルパスに載せるかを切り替えられる。具体的には、モデルのポインタが Raft でコミットされた時点で、提案元でない(standby 側の)レプリカが __model_committed → __load_model_from_remote_storage でストアからモデルをダウンロードし、自分の host メモリに実体化しておく(この複製を非同期にして IAT に吸収する)。だからユーザが次のセルを叩く頃には executor 候補の host メモリにモデルが揃っており、クリティカルパスに残るのは host→VRAM の数百ms だけになる(その代わり standby も host RAM にモデルを持つので ~3 倍の host RAM、§1)。

補足図(AI生成): モデルの居場所(分散ストア=原本/host RAM=standby も先読み保持で ~3 倍/VRAM=Executor 実行中だけ)と、復元 I/O を IAT に隠して host→VRAM の数百ms だけをクリティカルパスに残す流れ。VRAM は 3 倍にならない。(Q22・Q28・Q33)
「いつ host RAM で・いつ分散ストアで管理しているか」を、ユーザがセルN の実行ボタンを押してから結果が表示されるまでの流れに沿ってシーケンス図にすると次のとおり。ポイントは「ストアへの書き戻し(⑧以降)は、結果をユーザに返した後(⑦の後)に非同期で行う」ことで、ユーザはそれを待たない。

補足図(AI生成): 赤帯=ユーザが待つ(ボタン→結果表示)クリティカルパス/黄帯=結果を返した後に裏で行う非同期処理(IAT に隠す)。① セルN の実行ボタンで execute_request、② 選挙で R1 が executor、③ host RAM→VRAM ロード(数百ms)、④ セルN を実行(モデル更新)、⑤ to_cpu で VRAM→host 退避+empty_cache、⑥ execute_reply、⑦ セルN の結果を表示(ここでユーザに返る)。ここから下は裏側:⑧ 更新モデルを分散ストアへ checkpoint(durable 原本を更新)、⑨ ModelPointer を Raft で commit、⑩ ポインタを standby に複製、⑪ standby が原本をストアから download して自分の host RAM に先読み。次のセルN+1 は空き GPU のあるレプリカが executor 昇格して host RAM→VRAM で即実行(ストアから取り直さない)。host RAM = 常時保持するワーキングコピー(実行の出入り口・次のセルもここから)、分散ストア = 実行後に書き戻す durable な原本(standby が読む)、Raft = ポインタだけ。ユーザが待つのは ②〜⑦ だけで、⑧〜⑪ は IAT(中央値5分)の隙間に隠れる。(Q56・Q57)
なお --gpus は常にコンテナ起動時に付くもので、走行中コンテナへ後付けはしない(Docker の制約)。ここで重要なのは、LongRunning(既定)のコンテナが「セッション/カーネル生成時」(StartKernelReplica RPC、最初のセル実行より前)に起動し、以後セッション中ずっと走り続ける点だ。だから standby の間もコンテナは既に起動済みで(--gpus all 付き。論文も「サーバ上の全 GPU を、そのサーバが抱える全レプリカ コンテナに束縛する」と明記)、executor 昇格時にやるのは割当会計と host→VRAM コピーだけ。一方 SingleTrainingEvent では実行のたびにコンテナを起こすので、その起動時に --gpus 'device=N' が付く(Batch は実行の合間にはコンテナが無い/LCP は暖機プールの起動済みコンテナを使う)。つまり「--gpus を付ける起動時」とは、既定では executor になった時ではなくセッション開始時を指す。また LongRunning / SingleTrainingEvent や DynamicV3/MiddleGround/Gandiva といったポリシー名は実装(コード)由来で、論文本文の用語ではない(論文の評価方式は Reservation / Batch / NotebookOS / NotebookOS(LCP))。

補足図(AI生成): コンテナ寿命ポリシーの違い。既定 LongRunning は 3 長命コンテナをセッション中常駐(--gpus all は起動時)、Batch は毎回 create→破棄、LCP は暖機プールから借りて返す。対話性 LongRunning>LCP>Batch。(Q25・Q29・Q34・Q38)
猶予期間について:GPU 資源そのものに毎セルの猶予期間はなく、実行が終われば即解放する(VRAM を to_cpu+empty_cache で空け、割当をデコミット)。ただし別レイヤにセッション単位のアイドル回収(IdleSessionReclamationPolicy:既定 none、ほかに google-colab/adobe-sensei/custom)があり、「一定時間アイドルなセッションをカーネルごと回収する」猶予はこちらで設定する(実行中は回収されない)。なお連続セル実行の 89.45% が同じレプリカを再利用するのは、コンテナ(レプリカ)を温かく保つ話であって、GPU を握り続けることとは別だ。
セル実行要求が来ると、レプリカ間で実行担当(LEAD)を動的に選挙する。論文では「最初に LEAD を取ったレプリカが勝つ」方式に加え、スケジューラが空き状況を見て、GPU を取れないレプリカの execute_request を yield_request(実行を譲る要求)に変換するショートカットで素早く実行担当を確定させる。選挙に失敗(どのレプリカも GPU を取れない)した場合は、レプリカ マイグレーションで空きサーバへレプリカを移してから実行する。
なぜレプリカを持つのか(都度移行ではダメなのか):もしレプリカを持たず「単一カーネル+GPU が空いてなければ毎回別サーバへ状態を移行」する設計だと、移行(モデル等の大状態の運搬)の遅延が毎回の実行クリティカルパスに乗り、対話性が壊れる。NotebookOS はあらかじめ 3 サーバにレプリカを置いておくことで、少なくとも 1 つのレプリカが即座に GPU を確保できる確率を上げる。標準では 89.6% のタスクが移行なしに即実行できている。standby レプリカは Raft で CPU 状態を常時同期済みなので、どれが executor になっても状態の運搬は要らない。マイグレーションは、3 レプリカ全部が GPU を取れなかった最悪ケースだけのフォールバックであり、常用パスではない。要するに「都度移行」を「3 つの候補を先に配って移行をほぼ不要にする」へ置き換えたわけだ。

補足図(AI生成): 「単一カーネル+都度移行」は大状態の運搬が毎回クリティカルパスに乗る。NotebookOS は 3 レプリカを先配りして即実行(標準 89.6%)、3 台全滅時だけ移行(フォールバック)。(Q17)
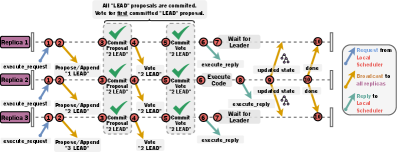
Figure 5: NotebookOS の executor(実行担当)選挙プロトコル。セル実行要求ごとに、GPU を確保できたレプリカが LEAD となり実行する。
セル実行要求が他のベースライン(Reservation / Batch など)と比べてどのワークフロー手順を辿るかの対比は次の図。
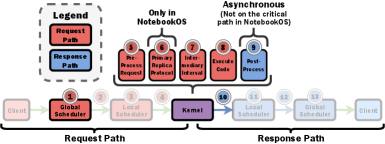
Figure 15: NotebookOS と各ベースラインにおける、ノートブック セル実行要求のワークフロー手順の対比。NotebookOS 固有のステップ(事前処理・選挙・中間処理)が示される。
3. 状態の同期 — 小さい CPU 状態と大きい GPU 状態を分ける
すべてを Raft で同期すると重い。そこで状態を二分する。なお論文の一次的な区別は「small kernel state(小さいカーネル状態)vs large objects(大きいオブジェクト)」だ。「小さい/大きい」はデータ量(サイズ)を修飾し、CPU/GPU は所在(どこに載っているか)を表す。両者は別軸だが相関している。「CPU で管理しているから小さい」のではない。軽い名前空間状態がたまたま CPU メモリ側にあって小さく、モデル等の重いオブジェクトが GPU 側にあって大きい、という対応関係だ(このノートでは便宜上「小さい CPU 状態/大きい GPU 状態」と呼ぶ)。
- 小さい CPU 側の状態:Python レベルの変数や、ネイティブ(C/C++)コードで宣言された状態など、カーネルの名前空間(namespace)から参照される状態。Raft ログでレプリカ間に同期する。
- 大きい GPU 側のオブジェクト(モデル・データセット・テンソル等、数百MB〜GB級):プラガブルな分散ストア(Redis / S3 / HDFS)へ非同期に退避し、Raft ログにはそのポインタだけを載せる。
振り分けの起点は AST(抽象構文木)解析だ。executor レプリカが実行コードの Python AST を解析して「複製が必要なランタイム状態(グローバル変数)」を把握する(図中のカーネル レプリカに AST が描かれているのはこのため。実装では SyncAST(ast.NodeVisitor)がグローバル変数名を収集する)。
大/小の判定(論文本文は詳述なし → 実装コードで確認):論文本文は「大変数は分散ストアへ逃がす」という方針までで、判定の具体(バイト数しきい値など)を述べていない。実装(GitHub ds2-lab/NotebookOS)を見ると、判定はバイト数しきい値ではなく型ベースだった。カーネルが名前空間の各変数を isinstance(v, DeepLearningModel) / isinstance(v, CustomDataset) で検査し(distributed_notebook/kernel/kernel.py)、これらフレームワーク独自の抽象基底クラス(ユーザがモデル/データセットをこれらを継承して書く)のインスタンスを「大オブジェクト」と見なす。該当すれば実体を分散ストアへチェックポイントし、Raft ログには ModelPointer / DatasetPointer(=ポインタ)だけを載せる。つまり任意の巨大変数をサイズで自動検出するのではなく、モデル/データセットという既知の型に絞ってポインタ化する設計だ。なお汎用 pickler(SyncLogPickler)はオブジェクト単位のバイトサイズも計測しており、一般オブジェクトは permanent reference(PRID)で参照化する仕組みも併存する。

補足図(AI生成): 名前空間の変数を AST+型検査(isinstance)で振り分け、小さい状態は Raft ログ、大きいモデル/データセットは分散ストアへ実体を退避しログにはポインタ(ModelPointer/DatasetPointer)だけ載せる。「小/大=サイズ、CPU/GPU=所在」は別軸。(Q8・Q11・Q20)
合意プロトコルに巨大データを流すとレイテンシが跳ねる。だから実体は分散ストア、合意ログには参照、と分離する。さらに同期コストを到着間隔(think time)の隙間に隠すことで、ユーザ体感の遅延に出さない。
状態同期の汎用性(限界):host→VRAM の移動は PyTorch API を使う(論文: “NotebookOS automatically loads model parameters from the host’s main memory onto all allocated GPUs using the PyTorch API on the critical path of execution requests.”)。任意の Python オブジェクトを GPU に載せる汎用機構ではなく、PyTorch のモデル/データセットが前提だ。状態同期も二層で割り切っている。小さい CPU 側状態は Raft で複製するが、外部プロセスや libC(ネイティブ)側の状態は同期できない(論文: “State of external processes or libC cannot be synchronized under the current implementation and is left as future work.”)。大きいオブジェクトは「モデル/データセットという既知の型(DeepLearningModel/CustomDataset を継承)」に絞ってポインタ化する(Q20)。よって、生の CUDA テンソルや JAX/TF の配列、独自 CUDA 確保など、フレームワークの型に乗らない GPU 状態は対象外で、汎用性は IDLT(PyTorch 訓練)向けに限定される。
前提・限界(host メモリ容量とレプリカのスケーラビリティ):この設計は「モデルが host main memory に収まる」ことを暗黙の前提にし、standby も host RAM にモデルを先読み保持する(§1・Q33)。つまり 1 カーネルあたり最大 ~3 倍の host RAM だ。ただし 3 レプリカは別々のサーバに分散配置されるので、3 倍は 1 台に集中せずクラスタ全体に散る(例:100 アクティブ カーネル=300 レプリカを 30 サーバに置けば ~10 レプリカ/サーバ。モデル ~1GB なら ~10GB/サーバで収まるが、~20GB 級の巨大モデルだと ~200GB/サーバで逼迫する)。また原本は分散ストアにあり、host RAM はあくまでキャッシュだ。論文は “NotebookOS also employs a simple node-level cache to limit storage and memory costs.” と、ノード単位のキャッシュで storage・memory コストを抑えると述べる(実装にも復元をクリティカルパスに載せるか選ぶ ReadOperationIsOnCriticalPath フラグがあり、先読みを諦めれば host RAM を節約できる=即時昇格との引き換え)。それでも、host RAM < 必要量 のときの spill・eviction・OOM 処理やキャッシュ追い出し方針の詳細、host RAM を考慮した受け入れ/配置制約は本文未記載だ。オーバーサブスクリプション(SR)の計算は GPU のみ(§4)で、host memory は資源要求パラメータ(MB 単位)には入るが、枯渇を防ぐ保証は示されていない。要するに、評価レンジ(控えめなモデル+host RAM に余裕)では成立するが、巨大モデルや高密度な相乗りでは host RAM がボトルネックになりうる、論文未対応の限界だ。

補足図(AI生成): 3 レプリカは別サーバに分散するので ~3 倍の host RAM は 1 台に集中しない。原本は分散ストアにあり host RAM はキャッシュ(node-level cache)。控えめなモデルなら収まるが、巨大モデル・高密度相乗りでは逼迫しうる。SR は GPU のみで host RAM の受け入れ/eviction/OOM は本文未記載。(Q49・Q50)
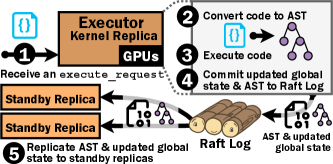
Figure 6: NotebookOS の分散カーネルが使う Raft ベースの状態同期プロトコル概要。小さい CPU 状態は Raft ログで、大きい GPU オブジェクトは分散ストア+ポインタで同期する。
Raft はどこで動く/ログはどこ/ポインタ複製は誰が発火するか(実装で確認):Raft の処理は 3 つのカーネル レプリカ(コンテナ)の中で行われ、3 レプリカがピアツーピアで直接合意する。Global/Local Scheduler は合意プロトコルの参加者ではない(スケジューラはメッセージ転送と資源会計の係)。executor レプリカが Raft の Leader、standby 2 つが Follower だ。Raft ログは 3 レプリカそれぞれが自分のコピーを持つ(複製ログこそ Raft の核)。ログに載るのは小さい CPU 状態と大オブジェクトのポインタ(ModelPointer/DatasetPointer)だけで、モデルの実体はログに入らず分散ストアにある。ポインタ複製の「発火」は、① executor が実体を分散ストアへ書き → ② executor(Leader)が ModelPointer を Raft ログに propose(提案) → ③ Raft が follower へ複製し過半数 ack で commit → ④ commit 時に全レプリカで __model_committed コールバックが発火 → ⑤ 提案元でない standby が __load_model_from_remote_storage で実体を download して host RAM に先読み、という連鎖になる(発火の起点は executor の propose、確定させるのは Raft の commit、download を起こすのは commit 時のコールバック)。

補足図(AI生成): Raft は 3 レプリカのコンテナ内で P2P 同期(スケジューラは関与しない)。ログは各レプリカが自分のコピーを保持し、中身は小 CPU 状態+ポインタだけ(実体は分散ストア)。ポインタ複製の発火連鎖①〜⑤:executor が実体をストアへ書く→Leader が ModelPointer を propose→過半数 ack で commit→__model_committed 発火→standby が実体を download して host RAM へ先読み。(Q65)
4. オーバーサブスクリプションとオートスケール
利用率を上げる軸が、資源のオーバーサブスクライブだ。各カーネルのサブスクリプション率を SR = S / (G × R)(S=要求 GPU、G=実 GPU 数、R=レプリカ数)として、クラスタ全体で Σ S / (Σ G × R) ≤ 1 を保つように受け入れる。高負荷時はレプリカ マイグレーションと自動クラスタ スケーリングで対応し、必要 GPU を Σ G' = f × Σ C(C=同時アクティブ実行数、f=1.05 のヘッドルーム係数)に合わせて増減させる。
オーバーサブスクライブはなぜ破綻しないか(時間軸で考える):オーバーサブスクライブとは、物理にある以上の GPU を「予約」として配ることだ(飛行機の overbooking と同じ。SR>1 がこの状態)。成立する理由は IDLT のデューティ比が低いからだ。タスク実行は中央値 ~2 分だが、次の実行までの間隔(IAT)は中央値 ~5 分で、1 カーネルが実際に GPU を使うのは時間のごく一部。だから予約した多数のカーネルは大半が think 中(GPU 不要)で、どの瞬間で時間軸を縦に切っても「実行中(ΣC)」は物理 GPU に収まる(ΣC ≪ ΣS)。実際にぶつかるのは、同じ瞬間に物理 GPU 数を超えて実行したくなった時だけ。そのときは溢れたレプリカを空きサーバへマイグレーションし、無ければスケールアウトで吸収する(同時実行が疎なので衝突は稀。標準 89.6% は移行なしで即実行)。

補足図(AI生成): 8 カーネルに GPU を予約(ΣS=8)しても物理は 2(ΣG=2)で足りる理由を時間軸で図解。各カーネルは緑(実行 ~2分)+灰(think ~5分)で、互い違いに並ぶのでどの瞬間も実行中は ~2 個(ΣC≪ΣS)。物理超えで同時実行したくなった瞬間だけ衝突=マイグレ/スケールアウトで吸収(IDLT では稀)。(Q71)
スケールアウト/スケールインの仕組み(いつ・どう動くか):GPU サーバのスケールアウト(増設)は論文本文(§3.4.2 Scale-Out Operations)に明記がある。Global Scheduler 内の auto-scaler が、設定可能なインターバルでクラスタ使用率を監視し、増減を判断する。
- スケールアウト(増設)の契機は 2 つ。(1) レプリカ配置の失敗。3 レプリカを置ける viable な空きサーバがクラスタに無いとき(原文: “there are no viable candidate servers across the cluster to serve the kernel replicas”)。(2) オートスケール方針(バースト用バッファ)。期待容量
Σ G' = f·Σ C(C=同時アクティブ実行数、f=1.05)を計算し、“If the current cluster capacity is smaller than ∑G′, additional GPU servers are provisioned.” つまり現在容量がΣ G'を下回れば GPU サーバを増設する。f=1.05は経験的に決めた「少しの余裕」だ。 - 配置失敗 scale-out では、その間カーネルの配置は待たされる:原文 “the placement of the corresponding kernel replicas is paused”。緩和として “Resources are immediately reserved for the paused kernel replicas on newly provisioned servers, i.e., before the servers are fully added to the … cluster”(完全参加前に資源を先行予約)を置くが、サーバ起動時間や scale-out 全体の所要時間の数値は本文に無い。通常実行(即 GPU 確保 89.6% /既存空きサーバへのマイグレーション)にはノード起動は絡まない。ただしクラスタ飽和で候補ゼロのときの初回配置は、ノード起動レイテンシを被りうる(定量化されていない)(Q70)。
- スケールイン(削減):使用率が低すぎる(
Σ G'< 現在の起動サーバ数)と、“NotebookOS’s auto-scaler attempts to release 1-2 idle servers at a time (where idle servers are those with no active training kernel replicas)”。つまりアクティブな訓練レプリカを持たない idle サーバを 1〜2 台ずつ徐々に解放する。
限界(本文未記載):スケールイン時に、削減対象サーバ上に(既定 LongRunning で)常駐している standby レプリカをどう退避するか、そのマイグレーション手順は本文に明記がない(”no active training kernel replicas” の idle 判定の具体も詳述なし)。Figure 10 の scale out(緑)と kernel migration(橙)が、この動的挙動の実測だ。

補足図(AI生成): オートスケール制御ループ。期待容量 ΣG'=f·ΣC(f=1.05)を基準に、配置失敗/容量不足ならスケールアウト、低使用率なら idle サーバを 1〜2 台ずつスケールイン。(Q47)
auto-scaler のフロー(制御ループとして):Global Scheduler 内の auto-scaler は、設定インターバルでポーリングするリアクティブな閉ループで、予測(forecasting)は持たない。1 周は (1) 実需要 ΣC(=今 commit 中=実行中の GPU 数。予約量 S でも割当量でもない瞬時値)を計測 → (2) 目標容量 ΣG' = 1.05·ΣC を計算 → (3) 現在のプロビジョニング容量と ΣG' を比較し、現在 < ΣG'(不足)なら scale-out、ΣG' < 現在(過剰)なら scale-in(idle サーバ=アクティブ訓練レプリカ無しを 1〜2 台ずつ、条件が消えるまで反復)、ほぼ等しければ何もしない、という分岐だ。つまり ΣG'=1.05·ΣC という 1 つの目標値に現在容量を追従させ、下回れば out、上回れば in(容量ベースの out と in は同じ目標を挟んだ表裏)。ただし scale-out にはもう 1 本、1.05 を通らないイベント駆動経路がある。レプリカ配置失敗(候補サーバが 3 台揃わない)の瞬間に即 scale-out する経路だ。なお 1〜2 台ずつ の漸進解放が唯一のダンピングで、明示的な hysteresis/cooldown、scale-in 時の standby 退避手順、1 回の増設台数は本文未記載、f=1.05 も経験則(需要モデル/SLO からの導出なし)。インターバルは論文では “configurable interval” とだけだが、実装の既定は 30 秒(scaling-interval、validateCapacity の呼び出し周期、0 で無効。Q68)。

補足図(AI生成): auto-scaler のフローチャート(§3.4.2)。インターバルごとに ΣC 計測→ΣG’=1.05·ΣC→現在容量と比較で out/in/no-op を分岐、配置失敗は 1.05 を通らず即 out、各分岐後は次インターバルへ戻る閉ループ。下段に elasticity 観点の本文未記載点(予測なし・hysteresis なし・standby 退避未記載・f 経験則)。(Q67)
ΣC の定義(auto-scaler の制御入力):ΣC は論文 §3.4.2 で “the total number of GPUs actively committed (∑C) to kernel replicas (that are actively executing GPU code)” と定義される。すなわち「今まさに GPU コードを実行中(commit 中)のレプリカに束縛されている GPU 数」をクラスタ全体で合計した値だ。standby レプリカが持つ GPU や空き GPU は数えない(実行している分だけ)。ここで紛らわしい 3 つを区別しておく。ΣS(subscribed=予約)はユーザが要求した GPU 数の総和(SR=S/(G·R) の分子、オーバーサブスクライブで物理を超えうる)。ΣC(committed=実行中)は今まさに走っている GPU 数(auto-scaler が追従する量、IDLT では ΣC ≪ ΣS)。ΣG'(target)は 1.05·ΣC、用意しておく容量の目標。auto-scaler は、予約量 ΣS ではなく実行中の ΣC に 1.05 を掛けたぶんだけ物理容量を追従させる。これが「予約ぶんを丸ごと確保せず、実際に走っている分だけ確保する」という節約の要だ(C ≪ S がトレースから保証される)。

補足図(AI生成): ΣC=各サーバの「実行中(commit 中)GPU」をクラスタ全体で合計した値(standby・空き GPU は数えない)。目標容量 ΣG’=1.05·ΣC。紛らわしい ΣS(予約)/ΣC(実行中)/ΣG’(目標)の区別つき。IDLT では ΣC ≪ ΣS。(Q69)
実験・結果
評価環境は 8GPU の EC2 GPU VM を 30 台。各セルが実際に走らせるプログラムは、実トレース(AdobeTrace)の到着パターンに沿って投入される実際の深層学習トレーニングだ(Table 1)。CV は CIFAR-10 / CIFAR-100 / Tiny ImageNet を VGG-16、ResNet-18、Inception v3 で、NLP は IMDb(Large Movie Reviews)と CoLA を BERT、GPT-2 で、音声認識は LibriSpeech を Deep Speech 2 で訓練する。ワークロード ドライバが各クライアントにアプリ ドメインをランダムに割り当て、さらにデータセットとモデルをランダムに決め、各セル タスク要求は割り当てられたモデルを割り当てられたデータセットで訓練する(データ/モデルはレプリカが AWS S3 から取得)。つまり Figure 9 などの「セル」は、この実モデル訓練タスクだ。
比較方式(ベースライン)の定義:Reservation は今の Jupyter/Colab 流で、セッション生存中ずっと GPU を予約する。Batch は、長時間 GPU 訓練向けのバッチ型 GPU クラスタ スケジューラを模したベースライン(原文 “Batch provisions a kernel replica container each time a user submits code and a job request for execution (e.g., to a slurm scheduler). The new container serves the training request before terminating.”)。すなわち Batch は「セルに書かれたプログラムを 1 つのジョブとして(slurm 等の)バッチ スケジューラに投入する」方式で、提出のたびにカーネル レプリカ コンテナを 1 つ起こし、その訓練を処理したらコンテナを終了する(実行の合間に常駐コンテナは無い)。NotebookOS / NotebookOS(LCP) が提案方式だ。
なお Batch の実装は FCFS だ(原文: “We implemented Batch using a first-come, first-serve (FCFS) job scheduling and GPU allocation policy within NotebookOS to approximate the performance of these GPU schedulers”)。重要なのは、この Batch ベースラインが「ジョブの実行時間(wall-time)見積もりに基づくスケジューリング」をモデル化していない点だ。実 slurm のように wall-time を申告してバックフィルや実行時間優先で詰める、という挙動は無い。単に要求が来た順(FCFS)に、空き GPU があれば割り当て、無ければ待つ。各セルの実行時間は割り当てモデル/データの実訓練時間で(プロトタイプでは実測、シミュレーションではトレース由来)、Batch はそれを最後まで走らせて解放するだけ。だからバースト時の「スケジューリング遅延」は、FCFS で空き GPU を待つ待ち時間から生じる(実行時間見積もりからではない)。論文も job duration の決定法までは詳述していない(does not detail how job duration is determined)。

補足図(AI生成): Batch ベースラインは FCFS。空き GPU があれば一時コンテナを起こして実訓練時間ぶん走らせ破棄、無ければ待つ。実 slurm のような wall-time 申告→バックフィルはモデル化していない。バースト時の遅延は「空き GPU 待ち」から生じる。(Q43・Q48)
まず評価に使ったワークロード(17.5時間の AdobeTrace)のアクティブ タスク数・セッション数の推移はこちら。
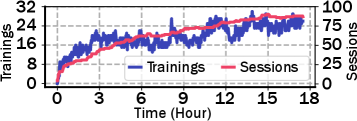
Figure 7: 17.5 時間 AdobeTrace 中の、アクティブなユーザ投入トレーニング タスク数とアクティブ ユーザ セッション数。
- 実 production の IDLT ワークロード 17.5 時間で、1,187.66 GPU 時間を節約(コンテナを大きめのプールに保持する LCP 変種=後述では 1,662.53 GPU 時間)。

Figure 8: プロビジョニングされた GPU のタイムライン。Batch(左)/ NotebookOS(中)/ NotebookOS(LCP)(右)の GPU 数推移。NotebookOS は実行中ぶんだけ束縛するので大きく下がる。
Figure 8 の読み方。3 枚とも横軸=経過時間(Hour、0〜約18h)、縦軸=その時点でプロビジョニングしている GPU 数だ。各パネルには 3 本の基準線がある。
- Reservation(予約方式):1 セッション=GPU を予約しっぱなしにした場合に必要な GPU 数。各パネルの上側の基準(最も多く確保する従来方式)。
- Oracle(理想):未来を完全に知っていれば最小限で足りる GPU 数。各パネルの下側の基準(理論的な下限)。
- 方式の線(Batch / NkOS / NkOS(LCP)):その方式が実際にプロビジョニングした GPU 数。
- 緑の網掛け = Saved:Reservation と方式の線の間の面積=予約方式に対して節約できた GPU(大きいほど良い)。
- 橙の網掛け = Over-provisioned:方式の線と Oracle の間の面積=理想に対して余分に確保してしまった GPU(小さいほど良い)。
読み方の要点(※当初ここを逆に書いていたので訂正)。Batch(左)はむしろ線が Oracle 近くまで下がり、橙(over-provision)が小さく緑(節約)が大きい。Batch は実行中だけ GPU を割り当て、実行が終わればコンテナごと破棄するので GPU 効率自体は高い。一方 NotebookOS(中)と NotebookOS(LCP)(右)は Batch より少し多めに確保する、つまり橙(over-provision)がやや大きい。論文はこの差の理由を明記している。原文: “because NotebookOS maintains three long-running replicas per kernel as well as a small buffer of ‘extra’ GPU servers for request bursts, NotebookOS provisions more servers than Batch”(NotebookOS は 1 カーネルあたり 3 つの長命レプリカを維持し、加えてリクエスト バースト用に少量の”予備”GPU サーバを持つため、Batch より多くのサーバをプロビジョニングする)。
ここで紛らわしいのは、「プロビジョニング(provision)」と「VRAM を計算で実際に使う」が別物である点だ。Figure 8 の縦軸は起動中(=課金中)のサーバが抱える GPU の総数であって、「いま計算のために VRAM を束縛している GPU 数」ではない。standby レプリカは確かに計算では VRAM を使わない(VRAM を束縛するのは実行中の executor だけ)。この意味で「standby は GPU を消費しない」という見方は正しい。だが既定の LongRunning では、standby レプリカも“セッション中ずっと生きる長命コンテナ”として GPU サーバ上に常駐し(§2)、3 レプリカは別々のサーバに分散配置される。この常駐コンテナ群を載せる(=それらのサーバを起動したままにする)ぶん、実行の合間にコンテナを一切持たない Batch よりも起動サーバ数が増える。つまり Figure 8 の「上乗せ」は VRAM の二重・三重確保 ではなく、長命レプリカ コンテナを載せるサーバを立てておくコスト + バースト用予備サーバ だ(standby が GPU の VRAM を握っているわけではない)。ただし上乗せは小さく、3 方式とも Reservation よりは大幅に下(緑は大)。
線(水位)が滑らか=変動が小さい理由(standby が GPU を握るからではない。standby はオーバーサブスクライブの原則どおり GPU を握らない)。Figure 8 の線の正体は、オートスケーラが維持するプロビジョニング容量 ΣG′ = 1.05·ΣC だ(§4)。ΣC はその瞬間にクラスタ全体で実行中(commit 中)の GPU 数の瞬時値、1.05 はバースト用 5% バッファ。つまり線は全ユーザの同時実行数の合算 ΣC に追従しており、セッション数でも個々のセル実行でもない。滑らかさは 2 つから来る。(1) 統計多重(推論)。ΣC は「実行 ~2分/間隔 ~5分」の低デューティ比カーネルを数百個ぶん合算した量なので、1 人ぶんは鋭いパルスでも、誰かが始め誰かが終わって合算はほぼ一定になる(プール効果で ΣC(t) 自体が滑らか)。(2) スケールインを鈍らせている(論文明記)。scale-in は idle サーバを 1〜2 台ずつしか解放しないうえ 5% バッファを持つので、バーストが引いても水位がカクッと落ちない。対照的に Batch はバッファ無しで実行が終わるたび即手放すため、より Oracle 近くまで落ちてギザギザに追随する。長命レプリカの常駐は「Batch より少し高い位置(オフセット)」の理由ではあっても、滑らかさの主因ではない(Q78)。

補足図(AI生成): 「provisioned=起動中サーバの GPU 数(課金)」と「VRAM を計算で使う GPU」の区別。standby は VRAM を握らないが、長命コンテナ常駐のためサーバは起動のまま=provisioned に数えられる。Batch は実行の合間にサーバを手放せる。(Q30・Q40)
したがって Figure 8 の主張は「NotebookOS は Batch/LCP よりほんの少し多く確保するだけで済む(過剰には確保しない)」であって、GPU 節約で Batch を上回ることではない。NotebookOS の本当の勝ちは Figure 9 の対話性にある(後述)。なお NotebookOS 系の中では、節約量は LCP 1,662.53 > NotebookOS 1,187.66 GPU 時間(LCP の方がよりバッチ寄りで over-provision が少ない)。Batch も GPU 効率は高いが、その代償に対話性が最悪になる。
ここで NotebookOS(LCP) の LCP は “Large Container Pool” だ。デフォルトの NotebookOS よりもプリウォーム済みコンテナを大きめのプールに保持し、セル実行要求が来たらプールの暖機済みコンテナを割り当て、実行後はコンテナを破棄せずプールへ戻す変種。対話性を一部犠牲にする代わりに資源コストをさらに下げるベースラインとして比較され、Figure 8(右)の通り NotebookOS 系の中では節約量が最大(1,662.53 GPU 時間)。
NotebookOS と NotebookOS(LCP) が Figure 8 で差がつく理由:既定の NotebookOS は 1 セッションにつき 3 つの長命レプリカ(LongRunning)を常駐させ続ける(§1)。対して LCP は長命レプリカを抱えず、暖機済みコンテナのプール(SingleTrainingEvent)から実行のたびに借りて返す。常駐させる GPU サーバ付きコンテナが少ないぶん、LCP は over-provision が小さく節約量が大きい。その代償が対話性の悪化だ。LCP は実行のたびに ①プールから暖機コンテナを割り当て ②モデル/データの I/O をクリティカルパスで行う ので、その遅延がセル実行の待ちに乗る(Figure 9(a) で NotebookOS より遅延が悪化し Batch 寄りになる)。なお LCP は完全なコールドスタートではなく「暖機済みプール」なのでコンテナ起動そのものは省けるが、コンテナの割り当てと I/O は毎回かかる。要するに、LCP はコンテナを使い回す(≒よりバッチ寄り)ことで資源は下げるが対話性を犠牲にする。既定 NotebookOS は 3 レプリカを温存し(モデルも host RAM に保持)対話性を取る代わりに、少しだけ多く確保する。そのトレードオフの差だ。
- タスクの 89.6% がセル実行要求時に即座に GPU を獲得でき(=移行不要)、対話性(低遅延)を維持する。選挙プロトコルはせいぜい数十ms(残りは host→VRAM の数百ms)、連続するセル実行の 89.45% が同じレプリカを再利用。(※「90%ile で約 50ms」と書いていたが、これは論文に無い数字だったため削除)
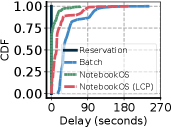
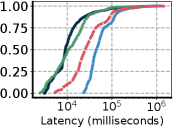
Figure 9: 各スケジューリング方式における (a) 対話遅延、(b) タスク完了時間(TCT)の CDF。NotebookOS は予約方式に近い対話遅延を、低い資源確保で達成する。
Figure 9 の読み方。両方とも CDF で、曲線が左/上にあるほど良い(値が小さい=速い)。どちらも小さい方が良い。2 つの指標の定義(論文)はこうだ。
- (a) 対話遅延(interactivity delay)=client が
execute_requestを送った瞬間から、カーネルがコードを実行し始める瞬間までの間隔。実行時間そのものは含まない(=走り出すまでの待ち時間。選挙、GPU 割当、スケジューラ overhead が中身)。x 軸は秒。 - (b) TCT(task completion time)=セル提出から、セルの実行が完了する瞬間まで(x 軸ラベルは “Latency”)。実行時間+事前・事後 I/O を含む(=
execute_replyが返るまで)。 - 関係:TCT = 対話遅延 + 実行時間 + 事後処理(GPU→host コピー等)。だから (a) は走り出しの速さ、(b) は終わるまでの総時間を見ている。

補足図(AI生成): 1 セルのタイムラインを Figure 9 の用語で。(a) 対話遅延 (interactivity delay)=execute_request 送信→実行開始(実行時間は含まない、x 軸=秒、=Fig 9(a))、(b) TCT (task completion time)=送信→完了(実行+事前・事後 I/O を含む、軸ラベルは “Latency”、=Fig 9(b))、次の実行までの think time が IAT (inter-arrival time)。TCT=対話遅延+実行時間+事後処理。Raft 同期・大オブジェクト I/O はこの IAT に隠して対話遅延に出さない。(Q35・Q37・Q72)
- (a) 対話遅延:Reservation が最良(GPU を予約済みなので即実行)。NotebookOS はほぼ Reservation 並み(89.6% が要求時に即 GPU 獲得=移行不要。選挙は数十ms)。Batch と NotebookOS(LCP) は遅延が悪化する。実行のたびにコンテナ/カーネルを起こす&データ I/O のオーバーヘッドが、要求の待ち時間に乗るためだ。
- (b) TCT:Reservation が(構造上の)下限=ベストで、Batch が最悪(一番右)。論文の正確な言い方は「NotebookOS は Reservation と comparable(同等)、ただし 38〜90 パーセンタイルだけ slightly higher(少し遅い)」だ。その範囲はオーバーサブスクライブでサーバが満杯になり、別サーバへマイグレーション+暖機コンテナ枯渇時のコールドスタートが乗るため(Q73)。Reservation は GPU を予約しっぱなし=束縛オーバーヘッドゼロ、しかも Figure 8 で最多の GPU を確保=GPU 待ちも無いので、NotebookOS がこれを上回ることはない(0〜38、90%tile 超では両者ほぼ重なる)。Batch が最悪なのは、①オンデマンドでカーネル/コンテナをコールド起動 ②提出ごとにモデル/データの事前・事後 I/O が必須 ③FCFS の GPU 待ち、が毎回 TCT に乗るからだ。NotebookOS はレプリカ(とモデル)を温存し I/O を IAT に隠すので、これらを避ける。
- (a) と (b) の軸の違いに注意:(a) delay は線形・秒(0〜270s)、(b) TCT は対数・ミリ秒(10⁴〜10⁶ ms=10s〜1000s)。だから「delay では Batch と NotebookOS の差が ~30s 程度」でも、「TCT では低パーセンタイルで桁違い」に見える。理由は 3 つ重なる。(i) 対数軸の拡大効果、(ii) delay は”起動+GPU待ち”だけだが TCT はそこに毎回のモデル/データ I/O(事前ロード+事後書き戻し)が上乗せされる(NotebookOS はこれを秘匿)、(iii) 短いタスクほど固定オーバーヘッド(起動+I/O)が実行時間を飲み込み、NotebookOS ~10⁴ms に対し Batch ~10⁵ms と約 1 桁開く(Q74)。
要するに、Batch は GPU 効率は良い(Figure 8)が対話遅延と TCT が最悪(Figure 9)。NotebookOS は Figure 8 で Batch よりわずかに多く確保するだけで、Figure 9 では Reservation 並みの対話性と TCT を出す。この両立が主眼だ(Reservation に”勝つ”のではなく”並ぶ”のがゴール)。
主要イベントのタイムラインと、その時々のサブスクリプション率(第2軸)はこう動く。
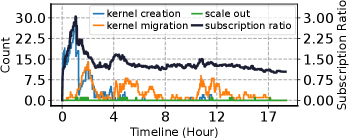
Figure 10: 17.5 時間ワークロード実行中の主要イベントのタイムライン。第2軸に NotebookOS のサブスクリプション率をプロット。
Figure 10 の読み方。横軸=経過時間(0〜約18h)。左軸=イベント発生数(Count)、右軸=サブスクリプション率(0〜3.0)。プロットされる系列は 4 本だ。
- kernel creation(青):その時刻に新規作成されたカーネル レプリカの数。ワークロード立ち上がりの序盤(〜1h)に大きく跳ね、以後は落ち着く。
- scale out(緑):クラスタのスケールアウト(新しい GPU サーバを増設した)イベント数。負荷が増えて GPU が足りなくなる局面で発生。
- kernel migration(橙):レプリカ マイグレーション(GPU が取れず空きサーバへレプリカを移した)数。
- subscription ratio(黒線・第2軸):オーバーサブスクリプション率
SR = S/(G·R)(§4)。序盤に最大 ~3 まで跳ね、その後 ~1〜1.5 で推移する。
要点(論文)。マイグレーションのスパイクは SR のスパイクと一致して起こる。「SR が登り始める=オーバーサブスクライブが詰まってくる」と、GPU を取れないレプリカが空きサーバへ移るためだ。論文は「最初の SR スパイクに最初のマイグレーション スパイクが一致し、4 時間後と 12 時間後にも追加のマイグレーションが起きる」と記す。つまり Figure 10 は、SR(混み具合)に応じてマイグレーションとスケールアウトで吸収する動的挙動を表した図だ。
- Raft 同期のオーバーヘッドは到着間隔の隙間に隠れて、ユーザ体感に出ない(小オブジェクト同期は 90 パーセンタイル 54.79ms、大オブジェクト I/O は 99% が読み 3.95s・書き 7.07s 未満で、5 分級の IAT に吸収される)。
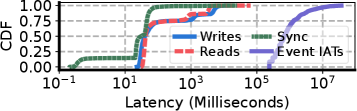
Figure 11: 大オブジェクトの読み書きと、小オブジェクト状態の Raft 同期レイテンシの CDF。いずれも IAT(中央値5分)の隙間に吸収される水準。
Figure 11 の読み方。横軸=レイテンシ(ミリ秒、対数軸)、縦軸=CDF。4 本の CDF が引かれる。
- Writes(大オブジェクトの書き込み):モデル等を分散ストアへ退避(チェックポイント)するレイテンシ。99% が約 7.07s 未満。
- Reads(大オブジェクトの読み込み):分散ストアからモデル等を host へ復元するレイテンシ。99% が約 3.95s 未満。
- Sync(小オブジェクトの Raft 同期):名前空間の軽い状態を Raft で同期するレイテンシ。90 / 95 / 99 パーセンタイルが 54.79 / 66.69 / 268.25 ms。
- Event IATs(セル実行の到着間隔):比較用に重ねた IAT の分布(中央値 ~5 分 ≒ 30 万 ms)。いちばん右に位置する。
主張はこうだ。Writes / Reads / Sync の 3 本はいずれも Event IATs(最も右の曲線)よりはるかに左にある。つまり状態同期や大オブジェクト I/O は、ユーザの思考時間(IAT)の隙間に余裕で収まる。だからこれらを非同期にしておけばユーザ体感の遅延に出ない、という設計の裏付けになる図だ。
- シミュレーションではプロバイダ コストを最大 69.87% 削減。
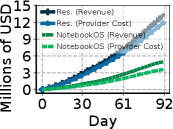
Figure 12: (a) プロバイダ側コスト(プロビジョニングした EC2 資源)と収益、(b) 利益率のタイムライン。
Figure 12 の読み方。横軸=日(0〜92日、90日規模シミュレーション)。(a) 縦軸=百万USD。Reservation と NotebookOS それぞれの Revenue(収益)と Provider Cost(プロバイダ側コスト=プロビジョニングした EC2 資源の費用)を 4 本プロット。NotebookOS は Provider Cost が大きく低い(GPU を握りっぱなしにしないため)。(b) 縦軸=利益率(%)。NotebookOS ~25〜30% に対し Reservation ~10〜15% で、同じ収益でもコストが低いぶん利益率が高い。これがコスト最大 69.87% 削減の、収益面での効果だ。
なお「15-min … 120-min」の凡例は Figure 12 ではなく、次の Figure 13(figures/x18.png)にある(混同しやすいので注意)。
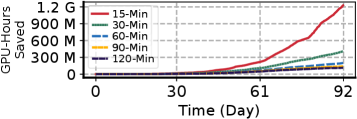
Figure 13: アイドル回収後のセル再実行を回避することで NotebookOS が節約した GPU 時間数。
Figure 13 の読み方。横軸=日(0〜92日)、縦軸=節約した GPU-Hours(M=百万、G=十億のオーダー、クラスタ規模の累積)。5 本の線(15-Min / 30-Min / 60-Min / 90-Min / 120-Min)はそれぞれ「アイドル回収インターバル(idle reclamation interval)の設定値」、つまり「ノートブック セッションが何分アイドルであれば、そのカーネルを回収(reclaim)してよいか」の猶予時間だ。回収されると状態が失われ、ユーザが戻ってきたときセルを再実行して状態を作り直す必要があり、その再実行が GPU 時間を食う。NotebookOS は状態を分散ストアにチェックポイントしているのでこの再実行を回避でき、その回避ぶんが「節約した GPU 時間」になる。インターバルが短い(15-Min)ほど回収が頻繁で、再実行も多くなるはずのところを回避できる量が大きい。だから 15-Min の線が最上位(92日で ~1.2G GPU-Hours)、120-Min が最下位、という並びになる。要するに、アイドル回収を積極的にする運用ほど NotebookOS の再実行回避メリットが大きい、と示す図だ。

補足図(AI生成): アイドル回収と再実行回避。回収で状態が消えても NotebookOS はチェックポイントから復元するので再実行の GPU 時間を節約。回収インターバル(15〜120 分)が短いほど節約量が大きい(Figure 13)。(Q45)
90日規模のシミュレーションでの、クラスタ全体の割当可能 GPU 数と GPU 使用率はこちら。
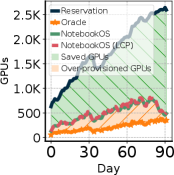
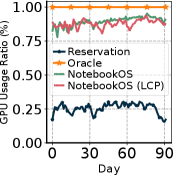
Figure 14: シミュレーションにおける (a) クラスタ全体の割当可能 GPU 数、(b) GPU 使用率。NotebookOS は使用率を大きく引き上げる。
数字の解釈。節約の源は「アイドル GPU を握らない」ことだ。即時獲得率 89.6% が示すのは、3 レプリカ+動的選挙+(必要時の)マイグレーションが、GPU 確保の待ちをほぼ無視できる水準まで詰めた、ということ。これが「剥がすと遅くなる」という素朴解放の弱点を克服している。
補足:方式別のエンドツーエンド遅延内訳
execute_request メッセージの処理がどの段階に時間を使うかを、方式ごとに分解した内訳が Figure 16〜19 だ。横軸の各項目は Figure 15(figures/x21.png)のワークフロー手順の段階に対応し、括弧内の数字がその手順番号。縦軸はレイテンシ(ミリ秒、対数)の分布(バイオリン)。各項目の意味は次のとおり。
- E2E:end-to-end。要求受信から応答までの総レイテンシ(以下の各段階の合計)。
- GS P Rq (1):Global Scheduler Process Request。Global Scheduler が要求を処理する段階(手順①)。
- K PP Rq (5):Kernel Pre-Process Request。カーネル側の前処理(手順⑤)。Figure 15 で「Only in NotebookOS」とされる NotebookOS 固有段階。
- K PRP (6):Kernel Primary Replica Protocol。実行担当を決める“主レプリカ プロトコル”=executor 選挙(手順⑥、§2)。NotebookOS 固有。
- K PRP Exec (7):手順⑦の Intermediary Process(中間処理=実行直前の取りまとめ)。NotebookOS 固有。
- K Exec (8):Kernel Execute Code。実際にセルのコード(モデル訓練)を実行する段階(手順⑧)。
- K P Rsp (9):Kernel Process Response / Post-Process。カーネルの後処理・応答生成(手順⑨)。
- LS←K (10):Local Scheduler ← Kernel。カーネルからの応答を Local Scheduler が受け取る段階(手順⑩、応答パスの起点)。
読み方。Reservation(Figure 16)には K PRP (6) と K PRP Exec (7) が無い(選挙・中間処理は NotebookOS 固有なので空)。NotebookOS(Figure 18)はこの (6)(7) が加わるぶん段階が増えるが、それらは小さく、かつ大オブジェクト I/O は IAT に隠れる。だから E2E は対話性を損なわない、というのがこの一連の図の主張だ。

補足図(AI生成): 遅延内訳図(Figure 16〜19)の横軸の各段階と手順番号。(5)(6)(7) は NotebookOS 固有(前処理・選挙・中間処理)で Reservation には無い。E2E は全段階の合計。(Q46)

Figure 16: Reservation が処理する execute request の詳細なエンドツーエンド遅延内訳。

Figure 17: Batch が処理する execute request の詳細なエンドツーエンド遅延内訳。
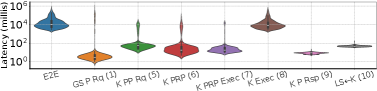
Figure 18: NotebookOS が処理する execute request の詳細なエンドツーエンド遅延内訳。選挙・同期の段階が加わるが IAT に吸収される。
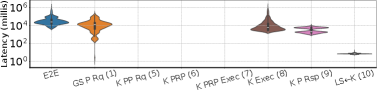
Figure 19: NotebookOS(LCP) が処理する execute request の詳細なエンドツーエンド遅延内訳。
関連研究との関係(メモ)
- ElasticNotebook / Kishu:ノートブック状態の保存・移行という上位テーマを共有するが、狙いが違う。あちらは「別マシンへ状態を効率移行/過去状態へ戻る」、NotebookOS は「GPU 効率のためにレプリカを移し、GPU を実行時だけ束縛する」。レプリカ マイグレーションで「大きい GPU 状態は分散ストア+ポインタ」とする設計は、ElasticNotebook の「保存 vs 再計算」と同じ”巨大オブジェクトをどう運ぶか”問題に、別の答えを出している。
- GPU スケジューリング / systems for AI:本論文の主戦場。Raft(合意)をノートブック カーネルの可用性と実行担当決定に使うのが新しい。
- JupyterHub のアイドル対策(
jupyter2026idlecullerのような idle culler)は「アイドルを殺す」発想だが、NotebookOS は「アイドルでも生かしたまま GPU だけ剥がす」点で対照的だ。
将来課題・限界
論文が「将来課題/未対応」として挙げているもの(§7 + 本文各所。日本語の通称で整理)。
- GPU の分割共有(fractional GPU)への対応:現状は 1 レプリカが整数個の GPU を占有するだけで、MIG やタイムシェアリングのような分割割り当ては未対応。将来は GPU 仮想化(HAMi など)を組み込む(§7)。
- マルチノード分散学習への対応:現状は単一サーバ内の学習のみで、複数サーバにまたがる分散学習(データ並列・モデル並列)は未サポート。Ray のような分散学習フレームワークと連携して実現する想定(コアの設計は大きく変えずに済む、という立場)(§7)。
- CPU オンリーのセルの実行最適化:GPU を使わないセルについて、ステートフルなサーバレス実行の技術(Wukong / Cloudburst)を取り込み、バースト並列で弾力的にスケールさせる余地(§7)。
- 外部プロセス・ネイティブ(libC)側の状態の同期:状態複製は Python 名前空間が対象で、カーネル外の外部プロセスや C/C++(libC)レイヤの状態は同期できない(§3.2.4)。
- 多様なランタイム依存をもつコンテナの事前ウォームアップ:暖機プールはライブラリ依存がバラバラなケースまではカバーしない。将来はチェックポイント/リストアや fork ベースの手法で対応しうる(§3.2.3)。
- コンテナ共有のセキュリティ・プライバシー(マルチテナント分離):レプリカ/コンテナ相乗りに伴うテナント間分離は本論文のスコープ外(既存研究を活用して対処しうる)(§5.1.1)。
- 本番品質の GPU 管理機構:プロトタイプの GPU 管理は簡易実装にとどめ、本番ではフル機能の仕組みに置き換える想定(§3.3。GPU 分割共有と関連)。
論文が将来課題として挙げていない(が、本ノートで整理した)暗黙の限界、elasticity の観点での穴は次のとおり。
- 予測スケーリングの不在:auto-scaler は瞬時の実需要
ΣCを見るだけのリアクティブ制御で、バーストの先回り(forecasting)が無い(§4)。 - hysteresis/cooldown の欠如:減衰は「scale-in を 1〜2 台ずつ」のみで、スケールアウト⇄インのオシレーション保護が明示されない。
- scale-in 時の standby レプリカ退避手順が未定義(idle 判定の具体も)。
- host RAM 枯渇時の spill / eviction / OOM 処理が未記載(SR の会計は GPU のみ、§3)。
- 耐故障は実質 1 台まで(3 レプリカ・Raft 過半数。replication factor を上げるコスト/便益の踏み込みは浅い)。
Q&A
Q1. Figure 1(figures/x1.png)を通して何を伝えたいのか? GPU はどのように使われる?
A. Figure 1 は NotebookOS の提案図ではなく、比較対象となる「素の Jupyter」の構成だ。狙いは、GPU がセッション全体に張り付いて無駄の温床になっている、という問題の起点を見せることにある。図を左から読むと、Client(ノート UI)⇄ Jupyter Server は HTTP & WebSockets で接続し、その上に書かれた Persistent User Session が「ユーザがノートを開いている間ずっと張りっぱなし(長命)」を表す。Server ⇄ Kernel は ØMQ(ZeroMQ)で接続し、実際にコードを走らせる Kernel に Reserved GPU(s) が紐づく。
GPU の使われ方(この従来方式の場合)は、①セル実行で execute_request が WebSocket → Server → ØMQ → Kernel と流れ、②Kernel が予約済みの GPU 上で計算する。問題は、③実行が終わっても GPU を手放さないことだ。Persistent User Session が生きている限り、カーネルは think time(考え事・コード編集)中も GPU を予約したまま握り続ける。つまり「1カーネル=1セッション=GPU 占有が寿命いっぱい続く」というビフォー像で、NotebookOS の「セル実行中だけ束縛」と対比させている。
Q2. Figure 2(figures/x2.png〜figures/x5.png)をもう少し詳細に。
A. Figure 2 は4枚組で、「IDLT はタスクが短く、間隔が長く、GPU はほぼ遊んでいる」ことを実トレース3種から定量化し、オーバーサブスクライブが成立する前提(C ≪ S)を裏づける。
- (a) タスク実行時間 CDF(x2):横軸 Duration(秒・対数)、縦軸 CDF。3トレースとも 10²秒(≒数分)あたりで急に立ち上がり、すぐ 1.0 に張り付く。つまり長時間タスクはほぼ無い(中央値2分、90%ile 17分)。
- (b) 到着間隔 IAT CDF(x3):横軸 IAT(秒・対数)。立ち上がりが (a) より右にずれる、つまり実行と実行の間隔は長い(中央値5分)。その正体が think time。(a) と (b) を並べて「実行は短く、間隔は長い」と読むのが要点。
- (c) GPU 使用率 CDF(x4、AdobeTrace):横軸 Percent、縦軸 CDF。
GPU % Util(青実線)は 0% 付近で一気に 0.8 近くまで立ち上がる。8割以上の時間、GPU 使用率がほぼゼロということだ(>81% アイドル)。Frac. GPU Utilized(橙破線)も低い側に寄り、多くの GPU が一度もまともに使われていない(約7割は全期間アイドル)。 - (d) GPU・CPU 使用量の推移(x5、AdobeTrace):横軸 Days(0〜90)、左軸 GPUs・右軸 CPUs の二軸。
Reserved(予約)はAllocatable(割当可能)に迫る高さまで積み上がるのにUtilized(実使用)は低いまま。つまり「予約 ≫ 実使用」のギャップが90日スケールで常態化している。3 本の関係は常に Allocatable(供給の上限=クラスタが払い出せる GPU 総数)≥ Reserved(セッションが確保して握っている数。予約方式では計算していなくても寿命いっぱい握る)≥ Utilized(いま実際に計算に使っている数)。allocatableとreservedの違いは「供給の上限」と「そのうち需要側が押さえた分」で、予約方式では Reserved が Allocatable に迫る一方、Utilized は >81% がアイドル(終盤の実使用は ~15%)。この「予約 ≫ 実使用」が本論文の中心的な問題になる(Q58)。
Q3. 3つのトレースの詳細について説明して。
A. 評価・分析に使う実トレースは3種で、性格が異なる(NotebookOS の主役は AdobeTrace、残り2つは「従来のバッチ訓練(BDLT/DLT)」との対比用)。
- Adobe Trace(AdobeTrace):Adobe 社内の研究クラスタから取得した、IDLT(対話的深層学習トレーニング)ノートブック セッションの本番トレース。2021年6〜8月、545,467 件のトレーニング イベント、15秒粒度。AWS EC2 GPU VM 上のコンテナ化ノートブック。本論文の主評価データで、「タスクの50%が2分以下」など IDLT の短時間・低頻度の性質を示す。
- Alibaba GPU Cluster 2020(AlibabaTrace):Alibaba の本番クラスタ。training と inference の両方(SOTA な ML アルゴリズム)。規模は 6,500 GPU / 1,800 サーバ、2020年7〜8月。従来型バッチ訓練(BDLT)の比較ベースライン。
- Philly GPU Trace(PhillyTrace):Microsoft の社内 Philly クラスタ。first-party の深層学習訓練(DLT)ジョブ。規模は 117,325 ジョブ / 2,490 GPU / 552 サーバ、2017年8月7日〜12月22日(代表サブセット 6.6GB)。長時間バッチ訓練の典型例としての比較ベースライン。
要は AdobeTrace が「対話的で短く散発的」、Alibaba/Philly が「バッチで長時間」という対照を作り、IDLT が従来のクラスタ ワークロードとは根本的に違うことを示している。
Q4. Figure 20(figures/x26.png)の trainings と sessions は何を示しているの?
A. Figure 20 は夏季全期間(6〜8月、AdobeTrace)にわたる「アクティブなユーザ投入トレーニング数」と「アクティブ ユーザ セッション数」の時系列。両者は粒度が違う。
- sessions(セッション):長命でステートフルなノートブック セッションそのもの。ユーザが作業を続けている永続的なコンテキストの数。論文では同時アクティブ セッションの最大は 90。
- trainings(トレーニング):そのセッションの中で走る個々の GPU 計算タスク(モデル訓練を伴うセル実行)。論文では同時アクティブ トレーニングの最大は 141。
違いは「セッション=ユーザが居続ける箱、トレーニング=その箱の中で時々起きる GPU を使う実行」。1つのセッションの寿命の中で複数のトレーニングが時系列で発生しうるので、瞬間ごとに「箱はたくさんあるが、実際に GPU を使っている実行はそのうち一部」という関係になる。GPU を握り続ける(セッション基準)のではなく実行中だけ束縛する(トレーニング基準)、という設計動機が、ここから直接読み取れる。
Q5. Figure 3(figures/x6.png)の①〜⑦の説明を加えて。
A. 本文 提案手法 の Figure 3 直下に①〜⑦の流れを追記した。要約すると:① クライアントがセル実行要求を Jupyter Server へ → ② Jupyter Server が Global Scheduler へ転送 → ③ Global Scheduler がレプリカの起動・マイグレーションと転送 → ④ Local Scheduler が対象(Executor)レプリカへルーティングして実行 → ⑤ レプリカ間で Raft により CPU 状態を同期 → ⑥ 実行中だけ GPU を動的束縛 → ⑦ 大きいオブジェクト/GPU 状態を分散ストアへ退避。右端の「1 kernel composed of 3 replicas」は 1 論理カーネル=3 レプリカ(Executor 1 + Standby 2)の注記。
Q6. 「1 kernel」は Jupyter kernel のこと? それとも GPU kernel のこと?
A. Jupyter kernel(ノートブックのセルを実行するプロセス)のこと。GPU/CUDA の「カーネル(GPU 上で走る関数)」ではない。本論文の “kernel” は一貫して Jupyter/IPython カーネルを指し、「1 kernel composed of 3 replicas」も 1 つの論理 Jupyter カーネルを 3 レプリカに分散実体化する、という意味。GPU はその Jupyter カーネルのコンテナに実行中だけ束縛される「資源」。本文 §1 複製カーネル 冒頭にも明記した。
Q7. Raft って何?
A.(※ Raft 自体の一般的な定義は論文外の背景知識。論文では “Raft consensus protocol” として利用される。)Raft は、分散システムで複数ノードに同じログ(状態)を一貫して複製するための合意(コンセンサス)プロトコルだ。要点は3つ。(1) リーダー選挙、つまりノード群が1つの leader を選び書き込みは leader 経由にする。(2) ログ複製 / 状態機械レプリケーション(SMR)。leader がログを follower に複製し、過半数(quorum)が確認したら確定(commit)する。全ノードが同順でログを適用して状態が揃う。(3) 過半数で前進する。3 ノードなら過半数 2 なので 1 ノード落ちても合意できる。本論文がレプリカ数を「3=過半数合意を取れる最小構成」とするのはこのためだ。NotebookOS での用途は、①実行担当(LEAD/Executor)の選挙、②小さい CPU 側カーネル状態のレプリカ間同期(大きい GPU オブジェクトは分散ストア+ポインタにして Raft には載せない)。
Q8. 「小さい CPU 状態」と「大きい GPU 状態」って何? どうやって小さい/大きいを決めている?
A. 小さい CPU 状態とは、Python レベルの変数や、ネイティブ(C/C++)コードで宣言された状態など、カーネルの名前空間から参照される軽い状態を指す。これは Raft ログで同期する。大きい GPU 状態とは、モデルやデータセット、テンソルといった数百MB〜GB級の大オブジェクトのこと。これは Raft には載せず、実体を分散ストア(Redis/S3/HDFS)へ退避し、ログにはポインタだけ置く。振り分けは固定のバイト数しきい値ではなく型(種類)ベースで、executor レプリカが AST 検査で変数の型を解析し、大オブジェクト(モデル/データセット等)を特定して分散ストアへ回す。本文 §3 状態の同期 に反映済み。
Q9. Figure 8(figures/x11.png)の見方は? 各項目が何を示しているのか分からない。
A. 本文 Figure 8 直下に読み方を追記した。横軸=経過時間、縦軸=その時点でプロビジョニング中の GPU 数。基準線は Reservation(予約方式=上側の基準、最大確保)と Oracle(理想=下側の基準、理論下限)、それに各方式の実プロビジョニング線。網掛けは、緑=Saved(Reservation に対し節約できた GPU、大きいほど良い)、橙=Over-provisioned(Oracle に対し余分に確保した GPU、小さいほど良い)。当初の説明を訂正すると、Batch はむしろ Oracle 近くまで下がり、橙が小さく緑が大きい(GPU 効率は高い)。NotebookOS / LCP は standby レプリカ+バースト備えのぶん Batch より少し多めに確保するので橙がやや大きい。Figure 8 の主旨は「NotebookOS は Batch/LCP よりほんの少し多く確保するだけ」というところで、対話性のほうは Figure 9 で示される。詳細は Q30 参照。
Q10. NotebookOS と NotebookOS(LCP) は何が違う?
A. LCP は “Large Container Pool” の略。デフォルトの NotebookOS よりプリウォーム済みコンテナを大きめのプールに保持し、実行要求にはプールの暖機済みコンテナを割り当て、実行後はコンテナを破棄せずプールへ戻す変種だ。対話性を一部犠牲にする代わりに資源コストをさらに下げるベースラインで、17.5 時間ワークロードでの節約は NotebookOS の 1,187.66 GPU 時間に対し LCP は 1,662.53 GPU 時間と最大になる。本文 Figure 8 直下に定義を追記済み。
Q11. 「小さい/大きい」は CPU・GPU を修飾している? それとも状態を修飾している? CPU で管理しているから小さい、ということ?
A. 「小さい/大きい」はデータ量(サイズ)を修飾し、CPU/GPU は所在を表す。別の軸だ。論文の一次区別も「small kernel state vs large objects」とサイズ基準になっている。「CPU が管理するから小さい」という因果ではなく、軽い名前空間状態がたまたま CPU メモリ側にあって小さく、モデル等の重いオブジェクトが GPU 側にあって大きい、という相関にすぎない。だから小さい方は Raft で同期でき、大きい方は分散ストアに逃がす。本文 §3 に補足済み。
Q12. Figure 3 でこの研究が新しく作ったものはどれ?
A. 新規なのは、Global Scheduler/Local Scheduler、複製分散カーネル(3 レプリカ+Raft SMR+AST)、実行担当の選挙プロトコル、動的 GPU 束縛、ハイブリッド状態複製(小=Raft、大=分散ストア)、Jupyter Server 内の Provisioner。既存の流用は、クライアント(Jupyter Notebook 等)、Jupyter Server/IPython カーネルの素体、Raft アルゴリズム、Distributed Data Store の実体(Redis/S3/HDFS)、Docker。本文 提案手法 の Figure 3 直下に追記。
Q13. Global Scheduler と Local Scheduler はそれぞれどこで動作する?
A. Global Scheduler はクラスタに 1 つ(中央)で、分散カーネル生成、レプリカのプロビジョニング開始、資源(CPU/メモリ/GPU)割当、障害処理、マイグレーション、オートスケールを統括する。Local Scheduler は各 GPU サーバに 1 つずつ動き、Global からのメッセージを自サーバ上の対象レプリカへ転送し、コンテナのプロビジョニングを担う。本文 Figure 3 直下に追記。
Q14. 「レプリカ」って何を指している?
A. その論理 Jupyter カーネルのコピー、つまりコンテナ化された IPython カーネル プロセスの 1 インスタンスを指す。データの複製ではなく、カーネルそのものの複製だ。1 論理カーネル=3 レプリカを別々の GPU サーバに分散し、選挙に勝った 1 つが executor(実行+実行中だけ GPU 束縛)、残り 2 つが standby(待機、Raft で状態同期)になる。本文 §1 に定義を追記。
Q15. 「dynamically bind GPUs」の仕組みが分からない。通常はどう GPU を使う? before/after を図にして。
A. 通常(予約方式)はカーネル=セッションの生存中ずっと GPU を予約し、考え事やコード編集の think time も握りっぱなしになる(>81% アイドル)。NotebookOS はレプリカがコードを実行する直前に GPU を束縛し、タスクが終わった瞬間に解放する(=dynamically bind GPUs)。空いた時間は他カーネルが GPU を使える。before/after を本文 §2 に補足図(figures/gpu-binding-beforeafter.svg)として追加した。
Q16. なんで 1 カーネルで 3 レプリカを持つの? 3 という数値の妥当性は?
A. Raft は過半数合意なので最低 3 必要だ(2 は Raft が成立しない)。5 にするとメモリやストレージ、ネットワークのコストが大きく増えるが、性能の見返りは乏しい。3 なら 1 台の fail-stop 障害まで耐えられる(残り 2 で過半数)。つまり「合意が成立し、かつ 1 故障耐性を得られる最小」が 3 ということだ。加えて 3 レプリカは「セル実行ごとに空き GPU を探せる候補サーバが 3 つ」という意味も持つ。本文 §1 に反映済み。
Q17. どのレプリカも GPU を取れない時に空きサーバへレプリカを移すのはなぜ? そもそもなぜレプリカが必要? レプリカ無しで、GPU が取れない時だけ別サーバへ状態を移行すれば良くない?
A. 「単一カーネル+毎回 GPU が空いてなければ状態移行」だと、移行(モデル等の大状態の運搬)の遅延が毎回のクリティカルパスに乗り、対話性が壊れる。NotebookOS は先に 3 サーバへレプリカを置くことで、少なくとも 1 つが即 GPU を確保できる確率を上げている(標準で 89.6% が移行なしに即実行)。standby は Raft で CPU 状態を常時同期済みなので、どれが executor になっても状態運搬は要らない。マイグレーションは 3 レプリカ全部が GPU を取れなかった最悪ケースのみのフォールバックだ。要は「都度移行」を「3 候補を先配りして移行をほぼ不要化」へ置き換えた、という設計になっている。本文 §2 に反映済み。
Q18. アーキテクチャ理解の補助になる図がほしい(before/after 図は意味は分かるが理解の助けになっていない)。
A. Figure 3 を読み解く補足図を作成し、本文 提案手法 に追加した(figures/architecture-replica-election.svg)。クライアント → Global Scheduler →(各 Local Scheduler 経由)→ 3 サーバの R1/R2/R3、空き GPU を持つ R1 が executor になり GPU を束縛、R2/R3 は standby で Raft 同期、大オブジェクトは分散ストアへ、全滅時のみマイグレーション、という関係を 1 枚にまとめている。
Q19. JupyterHub の spawner があるが、この論文はどの spawner を使っている?
A. JupyterHub の Spawner(DockerSpawner / KubeSpawner 等)は使っていない。代わりに Jupyter のカーネル プロビジョナ(kernel provisioner, jupyter_client)をカスタム実装し、それが StartKernel RPC を Global Scheduler に出す。コンテナの実起動は各サーバの Local Scheduler が StartKernelReplica RPC を受けて行う。オーケストレーションは Docker Swarm / Docker Compose(Kubernetes も対応)。本文 提案手法 の Figure 3 直下に反映済み。
Q20. 小さい/大きいの振り分けを「AST 検査で変数の型を解析」と書いてあるが、具体的にはどうやっている?(GitHub の実装も見て)
A. 実装(GitHub ds2-lab/NotebookOS)を確認したところ、論文本文より具体的に分かった。判定はバイト数しきい値ではなく型ベースだ。カーネルが名前空間の各変数を isinstance(v, DeepLearningModel) / isinstance(v, CustomDataset) で検査し(distributed_notebook/kernel/kernel.py)、これらフレームワーク独自の抽象基底クラス(ユーザがモデル/データセットをこれらを継承して書く)のインスタンスを「大オブジェクト」と判定する。該当すれば実体を分散ストアへチェックポイントし、Raft ログには ModelPointer / DatasetPointer(=ポインタ)だけを載せる。グローバル変数の捕捉自体は SyncAST(ast.NodeVisitor)が担う。つまり「任意の巨大変数をサイズで自動検出」するのではなく、モデル/データセットという既知の型に絞ってポインタ化する設計だ。なお汎用 pickler SyncLogPickler はオブジェクト単位のバイトサイズ計測+ permanent reference(PRID)参照化の仕組みも併せ持つ。本文 §3 を実装出典付きで更新済み。
Q21. 普通は Jupyter Server と IPython kernel は同じサーバで起動するよね。この研究では別サーバで起動する? だとしたらどう実現している(SSH? 通信は? Cybershuttle Notebook Gateway みたいな方法)?
A. はい、カーネル(レプリカ)は Jupyter Server とは別の GPU サーバで動く。実現は SSH ではなくゲートウェイ方式だった(実装で確認)。カスタム プロビジョナ GatewayProvisioner が gRPC(既定 8080)で「Cluster Gateway」= Global Scheduler に接続し、各サーバの「Local Daemon」= Local Scheduler 経由でレプリカ コンテナを起動・制御する。ユーザのセル実行など Jupyter メッセージは ZMQ ソケットで結線され、Global → Local → 対象レプリカへ転送される(Figure 3 の②③④)。発想は Jupyter Enterprise Gateway / Kernel Gateway(Cybershuttle Notebook Gateway もこの系統)と同じで、リモート カーネルをゲートウェイ越しにプロキシする。制御が gRPC、メッセージングが ZMQ 転送という分担だ。本文 提案手法 の Figure 3 直下に反映済み。
Q22. 補足図のように 3 レプリカを用意していると、無駄に資源(各 GPU サーバの RAM か VRAM かは分からないが)を使っているのでは?
A. 余分な資源は確かに使うが、一番高い GPU/VRAM は 3 倍にならない。ここが要点だ。GPU は executor が実行中だけ束縛するので、ある瞬間に VRAM を使うレプリカは最大 1 つ、standby はモデルを VRAM に載せない。大きいモデル/データも各レプリカの host RAM に 3 重には持たず、分散ストアへ退避して Raft ログにはポインタだけ置く。3 倍化するのは「軽い CPU 状態の同期」と「コンテナ プロセス常駐」程度で、ここに host RAM やストレージ、ネットワークのコストが乗る。論文も replication factor=5 を「コスト増のわりに見返り乏しい」と退け、3 を最小妥協点にしている。要は、安い host 資源を少し払って高い GPU を解放するトレードオフだ。本文 §1 に反映済み。
Q23. 「provisioner」ってどこで使われる単語? 何を指す? Jupyter 界隈で登場する? jupyter-server/gateway_provisioners のこと?
A. Jupyter の用語だ。jupyter_client(7.0 以降)の「Kernel Provisioning」フレームワークのことで、カーネル プロセスの起動とライフサイクル管理を担うのが provisioner。既定は LocalProvisioner(カーネルをローカル子プロセスで起動)で、カスタム実装でコンテナ/リモート/k8s に起こせる。jupyter_client.kernel_provisioners エントリポイントで登録し kernelspec から選ぶ。
リンクの jupyter-server/gateway_provisioners は実在する別パッケージ(リモート カーネル起動用、Enterprise Gateway の後継的な provisioner 群)。ただし NotebookOS はそれを使っていない。実装を確認すると、自前の GatewayProvisioner(KernelProvisionerBase 継承、エントリポイント名 gateway-provisioner)を持ち、その既製パッケージに依存していなかった。名前は紛らわしいが、同じゲートウェイ型 provisioner という系統の独自実装、ということらしい。なお JupyterHub の Spawner とも別概念だ(Spawner はユーザのノートブック サーバを起こす役、provisioner はカーネルを起こす役)。本文 提案手法 の Figure 3 直下に反映済み。
Q24. 「大オブジェクト」と書いてあるけど、どのくらいのサイズ?
A. 論文は「数百MB〜GB級」(hundreds of MBs to GBs)と特徴づけている(モデル・データセットを想定)。ただしこれは目安で、固定のバイト数しきい値ではない。判定は型ベースだ(DeepLearningModel / CustomDataset、Q20)。サイズ感の傍証として、Figure 11 の大オブジェクト I/O 実測は 99% が読み 3.95s、書き 7.07s 未満で、これが「数百MB〜GB を分散ストアに出し入れする」コストの実測になる(IAT 中央値5分の隙間に吸収される水準)。本文 §3 に「数百MB〜GB級」と記載済み。
Q25. セル実行中だけレプリカが GPU を確保する? それとも実行後も確保しておく猶予期間がある?
A. GPU 資源そのものには毎セルの猶予期間はなく、実行が終われば即解放する。実装では execute_reply(セル完了応答)受信時に processExecuteReply が確保済み資源をデコミットし、解放するのは実際に実行した executor だけだ(YIELD したレプリカは解放対象なし)。ただし別レイヤにセッション単位のアイドル回収(IdleSessionReclamationPolicy:既定 none/google-colab/adobe-sensei/custom)があり、「一定時間アイドルならカーネルごと回収」という猶予はこちらで設定する(実行中は回収不可)。連続実行の 89.45% が同じレプリカを再利用するのは「コンテナを温かく保つ」話(特に LCP)で、GPU を握り続けるのとは別の話。本文 §2 に反映済み。
Q26. 「レプリカが GPU を確保」とあるが、具体的にどんなコマンドで確保/解放している?
A.(実装で確認)物理束縛は Docker の --gpus フラグでやる(DockerInvoker.InitGpuCommand:--gpus all か --gpus 'device=0,2'。NVIDIA Container Toolkit が NVIDIA_VISIBLE_DEVICES を設定、GPU 情報は NVML/go-nvml)。ただしやり方はコンテナ寿命ポリシーで違う。既定(LongRunning)ではコンテナは --gpus all 付きの長命プロセスで、実行のたびにモデルを host→VRAM にロードし、終了後 to_cpu()+empty_cache() で VRAM を解放する。加えてスケジューラが割当をコミット/デコミットする(execute_reply 時)。コンテナのデバイス集合を付け替えるのではなく、モデルの VRAM 出し入れ+資源会計で束縛/解放するわけだ。単発系(LCP/Batch/Gandiva, SingleTrainingEvent)は実行ごとに --gpus 'device=N' 付きでコンテナを起こす(Batch は破棄、LCP は暖機プールへ返す)。特別な CUDA API ではない。Docker Swarm/Compose モードの話で、k8s は device plugin 経由になる。本文 §2 に反映済み。
Q27. jupyter-server/gateway_provisioners は Cybershuttle Notebook Gateway と関係しているプロジェクト?(※本論文の範囲外の周辺知識)
A. 直接の関係はなく、別系統の別プロジェクト。jupyter-server/gateway_provisioners は Project Jupyter(jupyter-server org)で、Jupyter Enterprise Gateway / Kernel Gateway の流れを汲み jupyter_client のカーネル プロビジョナとして YARN/Kubernetes/Docker 等にリモート カーネルを起こす。一方 Cybershuttle Notebook Gateway は Apache Airavata / cyber-shuttle(SciGaP)で、HPC ノードにカーネルを起こし ZMQ ポートを SSH で gateway IP 越しにプロキシする科学ゲートウェイ(Airavata 2.0 で OSS 公開予定)。「リモート カーネルをゲートウェイ越しに使う」同じ問題領域だが、組織も実装系譜も独立。(論文外の話題のため AI解説本体へは反映しない。)
Q28. standby はモデルを VRAM に載せないなら、いつモデルを VRAM に載せる? 復元時間をクリティカルパスに入れない工夫はどう実現している?
A. モデルの実体は host(CPU)main memory と分散ストアにあり、VRAM に載るのは実行の瞬間だけだ。executor が実行直前に host→VRAM へロードし(PyTorch、論文いわく「a couple hundred ms」)、実行後に to_cpu()+torch.cuda.empty_cache() で VRAM を解放する。復元をクリティカルパスから外す仕組みは、大オブジェクトの読み書き(分散ストア⇄host、レプリカ間複製)を非同期にして、到着間隔(think time / IAT、中央値5分)の隙間に隠すこと(Figure 11:99% が読み 3.95s、書き 7.07s 未満で IAT に吸収)。実装ではポリシーが ReadOperationIsOnCriticalPath / WriteOperationIsOnCriticalPath フラグで読み(復元)・書き(チェックポイント)をクリティカルパスに載せるか選べる。結果、ユーザが次セルを叩く頃には host メモリにモデルが揃い、クリティカルパスに残るのは host→VRAM の数百msだけになる。本文 §2 に反映済み。
Q29. 1 セル実行するたびに 1 コンテナが起動する? 1 セッション1 コンテナではなく 1 セル1 コンテナ?
A. ポリシー次第で、既定の NotebookOS は「1 セル1 コンテナ」ではない。既定(LongRunning)は 1 レプリカ=1 つの長命コンテナがセッション中ずっと生きる(1 論理カーネル=3 レプリカなので 1 セッションあたり 3 つの持続コンテナ)。セルごとに作り直さず、Raft で同期し続ける。一方 SingleTrainingEvent 系は「1 トレーニング(≒1 セル)=1 コンテナ」で、Batch/Gandiva は毎回作って捨て、LCP は暖機プールから借りて返す。だから「1 セル1 コンテナ」は LCP/Batch の挙動であって、既定 NotebookOS は「1 セッション×3 レプリカ=3 長命コンテナ」になる。本文 §1・§2 に反映済み。
Q30. Figure 8 の over-provisioned について。「Batch は緑が小さく橙が大きい=あまり節約できていない」と書いてあるが本当? NotebookOS の2つの方が over-provisioned の面積が大きく見える。
A. ご指摘どおりで、当初の私の記述が逆でした。訂正します。正しくは、Batch はむしろ Oracle 近くまで下がり、橙(over-provisioned)が小さく緑(節約)が大きい。Batch は実行中だけ GPU を割り当てるので、GPU 効率自体は高い。NotebookOS / NotebookOS(LCP) は Batch より少し多めに確保するので橙が大きくなる。standby レプリカを保ち、リクエスト バーストに備えるぶんの上乗せだ(論文に「NotebookOS は複製カーネルとバースト対応のため Batch/LCP よりわずかに多く確保する」と明記)。よって Figure 8 の主旨は、NotebookOS は Batch/LCP よりほんの少し多く確保するだけで済む(過剰確保はしない)ということであって、GPU 節約で Batch に勝つことではない。NotebookOS の本当の強みは Figure 9 の対話性のほうにある。本文 Figure 8 直下を訂正済み。
Q31. Reservation って何を示している?
A. 比較対象(ベースライン)の一つで、「今の Jupyter/Colab 流」、つまりカーネル(セッション)の生存中ずっと GPU を予約しっぱなしにする方式だ。Figure 8 では各パネルの上側の基準線=「全セッションがフルに GPU を予約したら必要になる GPU 数」を表す。最も多く確保するので、緑(Saved)は「この Reservation に対してどれだけ GPU を減らせたか」を意味する。対話遅延(Figure 9a)は Reservation が最良(常に GPU があるので即実行)だが、その代償が膨大な GPU 確保、つまり低利用率になる。NotebookOS は「Reservation 並みの対話性を、ずっと低い確保量で出す」のが狙いだ。
Q32. Figure 9 はどう見る? delay も latency も小さい方が良い? Batch がどちらも一番大きいのはなぜ?
A. 両方とも CDF で、曲線が左/上にあるほど良い(小さい=速い)。(a) 対話遅延(要求→実行開始まで)も (b) TCT(タスク完了時間)も小さい方が良い。
- (a) 対話遅延:Reservation が最良(予約済みで即実行)、NotebookOS はほぼ Reservation 並み(89.6% 即獲得=移行不要)。Batch と LCP は悪化する(実行毎にコンテナ/カーネル起動+ I/O のオーバーヘッドが待ちに乗る)。
- (b) TCT:Reservation が最良、Batch が最悪(一番右)。
- Batch がどちらも大きい理由(論文明記):Batch は ①オンデマンドでカーネルを起動 ②提出ごとにモデル/データの事前・事後 I/O が必須 ③バースト時のバッチ スケジューリング遅延、これらが毎回クリティカルパスに乗る。NotebookOS はレプリカを温存し I/O を IAT に隠すので回避できる。要は「Batch は GPU 効率は良い(Fig 8)が対話性は最悪(Fig 9)」で、NotebookOS は両立させている、というところ。本文 Figure 9 直下に反映済み。
Q33. standby 時はモデルを host RAM に置いておき、executor 選出後に(GPU 割当後)RAM→VRAM へ移す、という理解で合ってる? standby 中は ~3 倍の RAM を使う?
A. 合っています。実装で確認したところ、モデルのポインタが Raft でコミットされると __model_committed が走り、提案元でない(standby 側の)レプリカは __load_model_from_remote_storage でストアからモデルをダウンロードして host RAM に実体化する。だから standby 時はモデルが host RAM に載り(VRAM には載せない)、executor 昇格時に host→VRAM コピー(数百ms)して実行し、終了後 to_cpu+empty_cache で VRAM を解放する。結果、モデルは最大3レプリカの host RAM に載る、つまり実質 ~3 倍の host RAM を使う。ただし純粋な無駄というより、移行レイテンシをゼロにして即時昇格するための先読みだ。本文 §1・§2 に反映済み。
Q34. レプリカは standby の時にもう起動済み? --gpus フラグは実行時に付ける? それとも起動時?
A. 既定(LongRunning)では standby 時にもコンテナは起動済みだ(セッション中ずっと生きる長命コンテナ)。--gpus all はコンテナ起動時に付き、以後変わらない。走行中コンテナへ --gpus を後付けはしない(Docker の制約)。executor 昇格時にやるのは「スケジューラの割当会計+モデルの host→VRAM コピー」で、デバイス集合の付け替えではない。単発系(Batch/Gandiva/LCP, SingleTrainingEvent)はコンテナを実行のたびに起こすので、その起動時に --gpus 'device=N' を付ける。つまり --gpus は常に「コンテナ起動時」で、違いは「コンテナをいつ起こすか(セッション頭で1回か実行ごとか)」にある。本文 §2 に反映済み。
Q35. 「到着間隔(中央値5分)」って何? ユーザの到着間隔のこと?
A. 連続するセル実行(execute_request)の間隔、つまり「あるセルを実行してから次にセルを実行するまでの時間」のこと。ユーザのログイン到着ではなく実行イベントの到着間隔で、中身の大半は think time(出力を読む、コードを書く、考える)だ。中央値5分なので「GPU は5分のうち数分しか要らない」となり、オーバーサブスクライブが成立する根拠になる。本文 背景に注記済み。
Q36. コンテナ寿命ポリシーの LongRunning / SingleTrainingEvent / Gandiva などは論文に書いてある?
A. 主に実装(コード)由来の名前だ。論文が評価する方式は Reservation / Batch / NotebookOS / NotebookOS(LCP)(+シミュレーションで Gandiva 等の既存スケジューラ。Gandiva は外部の既存 DL クラスタ スケジューラ名)。ContainerLifetime の LongRunning / SingleTrainingEvent や DynamicV3、MiddleGround といった enum/クラス名はコード由来で、論文本文の用語ではない(論文は「コンテナを実行毎に起こす/使い回す」等の挙動として記述している)。前ターンで使ったこれらの名前は実装出典です。本文 §2 に注記済み。
Q37. Figure 9 の delay と latency は何の話? execute_request を送って ack が返るまでが delay、execute_reply が返る(タスク完了)までが latency?
A. ほぼその理解で正解(delay の終点は「ack」ではなく「実行開始」)。論文の定義はこうだ。(a) 対話遅延(interactivity delay)は execute_request を送った瞬間から、カーネルがコードを実行し始める瞬間までの間隔(実行時間は含まない。選挙、GPU 割当、スケジューラ overhead が中身)。(b) TCT(”Latency”)はセル提出から実行が完了するまで(実行時間+事前・事後 I/O を含む=execute_reply が返るまで)。関係は TCT = 対話遅延 + 実行時間 + 事後処理。つまり delay は「送ってから走り出すまで」、latency(TCT) は「execute_reply が返る=タスク完了まで」で合っている。本文 Figure 9 直下に反映済み。
Q38. 「--gpus は常にコンテナ起動時」なら、standby のときコンテナはまだ起動していないのでは?
A. いいえ、既定(LongRunning)では standby 時もコンテナは起動済みだ。コンテナはセッション/カーネル生成時(StartKernelReplica RPC、最初のセル実行より前)に --gpus all 付きで起動し、セッション中ずっと走り続ける(standby も executor も同じ走行中コンテナ)。論文も「サーバ上の全 GPU を、そのサーバの全レプリカ コンテナに束縛する」と明記している。つまり「起動時に --gpus を付ける」の“起動時”は、executor になった時ではなくセッション開始時を指す(私の表現が紛らわしかった点を明確化)。executor 昇格時にやるのは割当会計+host→VRAM コピーだけだ。単発系(Batch)は実行ごとにコンテナを起こすので実行の合間にはコンテナが無く、LCP は暖機プールの起動済みコンテナを使う。本文 §2 に明確化済み。
Q39. host RAM が VRAM より小さい場合、VRAM のデータが host RAM に乗り切らないのでは? そのケースは考えていない?
A. 論文はそのケースを扱っていない(本文未記載)。設計は「モデルが host main memory に収まる」前提で、VRAM⇄host RAM コピー、standby も host RAM 保持、分散ストア退避を組んでいる。host RAM < モデルサイズ のときの spill/eviction/OOM 処理は記述がない。通常 GPU サーバは host RAM ≫ 合計 VRAM なので成立するが、多数 GPU にまたがる巨大モデル(合計 VRAM > host RAM)や、1 ホスト相乗りで各レプリカが大モデルを host RAM にキャッシュする状況(~3倍 host RAM、Q33)では破綻しうる。host memory は資源要求パラメータ(MB)には入るが、オーバーサブスクリプション(SR)の計算は GPU のみで、host RAM 枯渇を防ぐ配置制約があるかも未記載だ。原本は分散ストアにあるので原理的には「host にキャッシュせずストアからストリーム」も考えられるが、論文は記述していない。論文の前提・限界として残る点といえる。本文 §3 に注記済み。
Q40. 「これは standby レプリカを保ち、リクエストのバーストに備えるぶんの上乗せ」と書いてあるが本当? standby レプリカを持っていても、standby は GPU を provision しないので正しくないのでは?
A. 記述自体は論文に忠実だが、「provision」と「VRAM を計算で使う」を区別すると疑問が解ける。論文は Figure 8 の差の理由をこう明記している。“because NotebookOS maintains three long-running replicas per kernel as well as a small buffer of ‘extra’ GPU servers for request bursts, NotebookOS provisions more servers than Batch”(3 つの長命レプリカの維持+バースト用予備サーバのため Batch より多く provision する)。ここで重要なのは、Figure 8 の縦軸が「起動中(課金中)のサーバが抱える GPU 総数」であって、「いま計算で VRAM を束縛している GPU 数」ではない、という点だ。
ご指摘どおり standby レプリカは計算で VRAM を使わない(VRAM を束縛するのは実行中の executor だけ)。この直感は正しい。ただし既定の LongRunning では、standby レプリカも「セッション中ずっと生きる長命コンテナ」として GPU サーバ上に常駐し、3 レプリカは別々のサーバに分散される。実行の合間にコンテナを一切持たない Batch と違い、NotebookOS はこの常駐コンテナ群を載せるサーバを起動したままにする必要があるので、起動サーバ数(=provisioned GPU 数)が Batch より増える。つまり「上乗せ」は VRAM の二重・三重確保 ではなく、長命レプリカ コンテナを載せるサーバを立てておくコスト + バースト用予備サーバ のことだ。だから「standby は GPU の VRAM を握っていない」は正しく、それでも「provisioned GPU 数」は増える、という両立が成り立つ。本文 Figure 8 直下の表現を、この区別が伝わるよう訂正・補強した(VRAM 利用と provision を取り違えない書き方に)。(補足の推測:常駐レプリカを 1 サーバに無制限に詰められないのは、各レプリカが host RAM にモデルをキャッシュし(Q33)3 レプリカを別サーバに分散するため。この配置制約も provision 増の一因と考えられるが、論文本文はそこまで詳述していない。)
Q41. Figure 8 で NotebookOS と NotebookOS(LCP) の差が出る理由は? LCP の方が対話性を犠牲にしている? つまり LCP はコンテナをコールドスタートしている?
A. 差の理由はこうだ。既定 NotebookOS は 1 セッションに 3 つの長命レプリカ(LongRunning)を常駐させ続けるが、LCP は長命レプリカを持たず、暖機済みコンテナのプール(SingleTrainingEvent)から実行のたびに借りて返す。常駐する GPU サーバ付きコンテナが少ないぶん、LCP は over-provision が小さく、節約量が大きい(1,662.53 > 1,187.66 GPU 時間)。対話性は LCP の方が犠牲になっている(Figure 9(a))。LCP は実行のたびに ①プールから暖機コンテナを割り当て ②モデル/データ I/O をクリティカルパスで実施 し、その遅延が待ちに乗るためだ。ただし「コールドスタート」ではない。LCP は暖機済み(プリウォーム)プールを使うのでコンテナ起動自体は省ける。省けないのは「コンテナの割り当て+毎回の I/O」のほうだ。要は、LCP はコンテナを使い回してよりバッチ寄りに資源を下げる代わり対話性を犠牲にし、既定 NotebookOS は 3 レプリカ温存(モデルも host RAM 保持)で対話性を取り、少しだけ多く確保する。本文 Figure 8 直下に反映済み。
Q42. Figure 9 ではどういうプログラムが書かれたセルを実行している?
A. 実際の深層学習トレーニングだ(論文 Table 1)。CV は CIFAR-10 / CIFAR-100 / Tiny ImageNet を VGG-16、ResNet-18、Inception v3 で、NLP は IMDb・CoLA を BERT・GPT-2 で、音声認識は LibriSpeech を Deep Speech 2 で訓練する。ワークロード ドライバが各クライアントにドメイン→データセット→モデルをランダムに割り当て、各セル タスク要求は「割り当てられたモデルを割り当てられたデータセットで訓練する」(データ/モデルは S3 から取得)。つまり Figure 9 の「セル」は print 文のような軽いものではなく、毎回が実モデル訓練タスクだ。本文 実験・結果 の評価環境に反映済み。
Q43. 「Batch」は何を指している? ジョブスケジューラ環境で、そのセルのプログラムをジョブとして投入した、という意味ではない?
A. むしろまさにその意味だ(「〜ではない」ではなく「そうだ」が正解)。論文の定義はこう。“Batch provisions a kernel replica container each time a user submits code and a job request for execution (e.g., to a slurm scheduler). The new container serves the training request before terminating.” つまり Batch は長時間 GPU 訓練向けのバッチ型クラスタ スケジューラ(slurm 等)を模したベースラインで、セルのプログラムを 1 ジョブとしてバッチ スケジューラに投入し、そのたびにカーネル レプリカ コンテナを 1 つ起こし、訓練を処理したらコンテナを終了する。実行の合間に常駐コンテナは無い。だから GPU 効率は高い(実行中だけ確保)が、毎回のコンテナ起動+ I/O +バースト時のスケジューリング遅延で対話性が最悪になる(Figure 9)。本文 実験・結果 にベースライン定義として追記。
Q44. Figure 10・11 をもっと詳しく。Figure 10 の kernel create / … / subscription ratio はそれぞれ何を示す?
A. Figure 10(x14)は、横軸=経過時間、左軸=イベント発生数、右軸=サブスクリプション率。4 系列ある。kernel creation(青)=新規カーネル レプリカ作成数(序盤に急増)、scale out(緑)=クラスタのスケールアウト(GPU サーバ増設)イベント、kernel migration(橙)=レプリカ マイグレーション(GPU が取れず空きサーバへ移動)数、subscription ratio(黒線・第2軸)=オーバーサブスクリプション率 SR=S/(G·R)(序盤 ~3、その後 ~1〜1.5)。要点は「マイグレーションのスパイクが SR のスパイクと一致する」こと、つまり混んでくる(SR 上昇)と GPU を取れないレプリカが移動するという動的挙動だ。Figure 11(x15)は、横軸=レイテンシ(ms・対数)、縦軸=CDF。4 本ある。Writes(大オブジェクト書き:99% < 7.07s)、Reads(大オブジェクト読み:99% < 3.95s)、Sync(小オブジェクト Raft 同期:p90/95/99 = 54.79/66.69/268.25 ms)、Event IATs(セル実行の到着間隔:中央値 ~5 分で最も右)。主張は「I/O・同期はすべて IAT(最右の曲線)より十分左、つまり think time の隙間に収まる」というもの。本文 Figure 10・11 直下に詳説を追記。
Q45. Figure 12 は 15-min … 120-min とあるが、これは何を示している?
A. まず番号を整理すると、「15-Min … 120-Min」の凡例があるのは本ノートの Figure 13(figures/x18.png)で、Figure 12(x16/x17)ではない(混同しやすい)。Figure 12 は (a) プロバイダ側コストと収益、(b) 利益率(NotebookOS ~25-30% vs Reservation ~10-15%)を 90 日で示す図だ(コスト最大 69.87% 削減の収益面)。Figure 13 が「15/30/60/90/120-Min」の 5 本で、各線はアイドル回収インターバル(セッションが何分アイドルならカーネルを回収するかの猶予)の設定値を表す。回収されると状態が消え、戻ってきたユーザはセルを再実行して状態を作り直す必要があり、GPU 時間を食う。NotebookOS は状態をチェックポイントしているので、その再実行を回避でき、その回避ぶんが「節約 GPU 時間」になる。インターバルが短い(15-Min)ほど回収が頻繁になり再実行回避の効果が大きいので、15-Min が最上位(92日で ~1.2G GPU-Hours)、120-Min が最下位だ。本文 Figure 12・13 直下に反映済み。
Q46. 補足の遅延内訳図の e2e / … / ls←k(10) の各項目を説明して。
A. 各項目は Figure 15(figures/x21.png)のワークフロー手順の段階で、括弧内が手順番号だ。E2E=総レイテンシ、GS P Rq (1)=Global Scheduler Process Request(手順①、GS の要求処理)、K PP Rq (5)=Kernel Pre-Process Request(手順⑤、カーネル前処理、NotebookOS 固有)、K PRP (6)=Kernel Primary Replica Protocol(手順⑥、主レプリカ プロトコル=executor 選挙、NotebookOS 固有)、K PRP Exec (7)=手順⑦の Intermediary Process(中間処理、NotebookOS 固有)、K Exec (8)=Kernel Execute Code(手順⑧、コード=モデル訓練の実行)、K P Rsp (9)=Kernel Process Response/Post-Process(手順⑨、後処理・応答生成)、LS←K (10)=Local Scheduler がカーネルから応答を受け取る(手順⑩、応答パス起点)。Reservation(Figure 16)には (6)(7) が無く、NotebookOS(Figure 18)はそれが加わる。選挙と中間処理が NotebookOS 固有の上乗せ段階だが、小さいので E2E は対話性を損なわない、というのがこの図群の主張だ。本文 補足:方式別のエンドツーエンド遅延内訳 に決定版の対応表を追記。
Q47. GPU サーバのスケールアウト/スケールインはいつ・どうやっている?
A. Global Scheduler 内の auto-scaler が、設定可能なインターバルでクラスタ使用率を監視して増減を決める。スケールアウト(増設)の契機は 2 つある。(1) レプリカ配置の失敗、つまり 3 レプリカを置ける空きサーバがクラスタに無いとき。(2) オートスケール方針、つまり期待容量 Σ G' = f·Σ C(C=同時アクティブ実行数、f=1.05)を計算し、現在容量が Σ G' を下回れば GPU サーバを増設する(バースト用バッファ)。スケールイン(削減)は、使用率が低すぎる(Σ G' < 現在の起動サーバ数)と、アクティブな訓練レプリカを持たない idle サーバを 1〜2 台ずつ徐々に解放する。ただし削減対象サーバ上の standby レプリカをどう退避するか(マイグレーション手順)は本文未記載だ。Figure 10 の scale out(緑)と kernel migration(橙)がこの実測になる。本文 §4 に反映済み。
Q48. Batch はジョブ スケジューラ環境だと言うが、ジョブ スクリプトに書く実行時間はどう扱っている? 普通はスケジューラが実行時間でスケジューリングするはずだが。
A. この論文の Batch ベースラインは、実行時間(wall-time)に基づくスケジューリングをモデル化していない。Batch は FCFS(first-come, first-serve)の job scheduling + GPU 割当ポリシーとして実装されており(原文: “We implemented Batch using a first-come, first-serve (FCFS) job scheduling and GPU allocation policy within NotebookOS to approximate the performance of these GPU schedulers”)、実 slurm のように「wall-time を申告してバックフィル/実行時間優先で詰める」挙動は無い。単に「要求が来た順に、空き GPU があれば割り当て、無ければ待つ」だけだ。各セルの実行時間は割り当てモデル/データの実訓練時間(プロトタイプは実測、シミュレーションはトレース由来)で、Batch はそれを最後まで走らせて解放するだけ。だからバースト時のスケジューリング遅延は「FCFS で空き GPU を待つ待ち時間」から生じる(実行時間見積もりからではない)。論文も job duration の決定法までは詳述していない(does not detail how job duration is determined)。つまりご想定の「実行時間でスケジューリング」は現実の slurm の話で、本論文は Batch を意図的に FCFS へ単純化している。本文 実験・結果 のベースライン定義に反映済み。
Q49. host RAM→VRAM へ PyTorch API でデータを送ると書いてあるが、すべての Python オブジェクトに対応している? 汎用性は?
A. いいえ、汎用ではない。PyTorch のモデル/データセットが前提だ。論文は host→VRAM ロードを “…using the PyTorch API on the critical path of execution requests.” と明記しており、任意の Python オブジェクトを GPU に載せる仕組みではない。状態同期は二層になっている。①小さい CPU 側状態は Raft で複製する(ただし “State of external processes or libC cannot be synchronized … left as future work” =外部プロセス/ネイティブ状態は同期不可)。②大きいオブジェクトは DeepLearningModel/CustomDataset を継承した既知の型だけを分散ストアへ退避しポインタ化する(Q20)。よって生の CUDA テンソルや JAX/TF 配列、独自 CUDA 確保などフレームワークの型に乗らない GPU 状態は対象外で、汎用性は IDLT(PyTorch 訓練)向けに限定される。本文 §3 に反映済み。
Q50. standby は分散ストアのデータを host RAM 上に保有するんだよね? host RAM が足りなくなるのでは? 1 カーネル=3 レプリカなら、アクティブ 100 ユーザで 300 レプリカ。host RAM は足りる?
A. 前提は合っている(standby も host RAM にモデルを先読み保持=~3 倍、Q33)。ただし足りなくなりにくくする要素が 3 つある。(1) 3 レプリカは別サーバに分散するので、3 倍は 1 台に集中しない(300 レプリカ/30 サーバ=~10 レプリカ/サーバ。~1GB モデルなら ~10GB/サーバ)。(2) 原本は分散ストアにあり host RAM はキャッシュにすぎない。論文も “a simple node-level cache to limit storage and memory costs” と述べ、実装の ReadOperationIsOnCriticalPath フラグで先読みを諦めれば host RAM を節約できる(即時昇格との引き換え)。(3) 評価モデル(VGG/ResNet/BERT/GPT-2/Deep Speech 2)は数百MB〜数GBと控えめで、GPU サーバは通常 host RAM ≫ 合計 VRAM になる。だが限界も実在する。host RAM < 必要量 の spill/eviction/OOM やキャッシュ追い出し方針、host RAM を考慮した受け入れ/配置制約は本文未記載で、SR は GPU のみ。だから巨大モデルや高密度相乗りでは host RAM がボトルネックになりうる(Q39 の限界を定量化した形)。本文 §3 に反映済み。
Q51. inter-arrival time(IAT)とは? AlibabaTrace と PhillyTrace はバッチ型トレースなのに IAT があるのはどういうこと?
A. IAT は「あるタスクが到着(投入)してから、次のタスクが到着するまでの間隔」という待ち行列論の一般概念で、タスクの実行時間ではなくタスクとタスクの“間”の時間を指す(NotebookOS では中身の大半が think time)。バッチ型でも IAT が定義できるのは、「タスク(到着イベント)」が何を指すかがトレースごとに違うだけで、どのトレースも「ユーザが次々とタスクを投げてくる到着間隔」を測っているからだ。AdobeTrace のタスクはノートブックのセル実行(GPU を使う訓練/推論のセル。論文 “a cell task execution of GPU operations—such as model training and inference”)、AlibabaTrace / PhillyTrace のタスクはバッチ ジョブの投入(submission)。単位が「セル実行」か「バッチ ジョブ」かという粒度の違いだけで、論文自身もこれを「やや非対称な比較」と認めている。
測り方も重要だ。論文は 3 トレースとも IAT を「ユーザ セッションごとに独立して」測ると明記している。原文: “For all three traces, the IATs were measured within each user session independently, rather than the cluster-wide IATs of tasks submitted by any active user session, to ensure a fair comparison.” つまりクラスタ全体の到着間隔(全ユーザの投入をまぜたもの)ではなく、1 ユーザが連続して投げるタスクの間隔という同じ土俵で比較している。これにより「AdobeTrace=対話的で間隔が長い vs Alibaba/Philly=バッチ」の対照が公平になる(Figure 2(b) はこのセッション内 IAT の CDF を 3 トレース重ねたもの)。本文 背景・問題 に IAT の一般定義とトレース別の「タスク」単位を注記。
Q52. AlibabaTrace・PhillyTrace のときの GPU・CPU 使用率の図はないの?
A. ない。論文が GPU 使用率(Figure 2(c))や GPU・CPU 使用量(Figure 2(d))を報告しているのは AdobeTrace のみだ(両キャプションに “(AdobeTrace)” と明記)。Alibaba/Philly が登場するのは (a) タスク実行時間 CDF と (b) 到着間隔 IAT CDF の 2 つだけで、利用率・使用量の図には含まれない。理由は本文に明記がない。以下は解釈だが、Alibaba/Philly は「バッチで長時間」という対照を作るための比較用なので、(a)(b) で「実行が長く、間隔も詰まる」を示せば役目を果たす。一方 (c)(d) の利用率・使用量は「予約 GPU が 8 割以上アイドル」という本論文の中心的な問題提起の裏づけなので、主評価データ AdobeTrace(IDLT)で示せば足りる、という構成と読める。本文 Figure 2 直下に反映済み。
Q53. Batch でも worst の対話遅延が ~20s ということは、あまり GPU は混んでいない? ジョブ投入から実行開始まで ~20s ということ?
A. 定義の理解は正しい。対話遅延は execute_request 送信 → カーネルがコードを実行し始めるまで(Q37)なので、「投入 → 実行開始まで」で合っている。ただし「~20s = GPU が空いている」とは断定できない。Batch の対話遅延の中身は (1) オンデマンドのコンテナ起動、(2) FCFS で空き GPU を待つスケジューリング遅延(混雑依存の成分)、(3) 提出ごとの事前 I/O(モデル/データのロード、論文 “mandatory pre- and post-processing data I/O … for each submission”)で、このうち (1)(3) は GPU の空き具合に関係なく毎回かかる固定オーバーヘッドだ。混雑成分は (2) だけなので、~20s の大半が固定費なら GPU の空きとは言えない。とはいえ worst が分単位ではなく ~20s に収まる事実は、評価期間中に FCFS の待ち行列が極端に膨らむほどの深刻な GPU 枯渇は起きていない、と示唆する。ただし評価クラスタ(8GPU×30台)は auto-scaler が高負荷時に GPU サーバを増設する(Fig 8/10)ので、「もともと暇」ではなく「スケールアウトで混雑を吸収した結果」とみるのが自然だろう(この因果は本文に明示はなく解釈)。なお ~20s という値は Figure 9(a) の CDF から読んだもので、論文本文に数値の記載はない(本文は「Batch が最も遅延が大きい」と定性的に述べるのみ)。
Q54. セル実行ボタンを押してから実行結果が表示されるまでのシーケンス図がほしい。
A. 提案手法 の Figure 3 説明直後に、AI 生成のシーケンス図(figures/cell-execution-sequence.svg)を追加した。①Client→Jupyter Server→②Global Scheduler→③Local Scheduler→④3 レプリカ配送→選挙で R1 が executor(R2/R3 は yield_request 化)→⑥GPU 動的束縛+host→VRAM ロード+コード実行→⑤Raft で小 CPU 状態同期・⑦大オブジェクトを分散ストアへ非同期 checkpoint→GPU 即解放→execute_reply が ⑩Local→Global→Jupyter Server→Client と返って結果表示、という流れ。対話遅延(Fig 9a)は「①送信〜⑥実行開始」まで(標準 89.6% が即 GPU 確保=移行不要)、Raft 同期・大オブジェクト I/O は IAT(中央値5分)の隙間に隠してクリティカルパスから外す、という設計が一目で分かるようにした。番号は Figure 3 の①〜⑦と Figure 15/18 のE2E内訳に対応。
Q55. GPU 解放時に to_cpu と書いてあるけど、大オブジェクトも host RAM に置いているの?
A. はい。大オブジェクト(モデル)の実体は host RAM に置く。to_cpu() は PyTorch の .cpu() でモデルのパラメータを VRAM→host RAM へ移す操作で、続く empty_cache() で VRAM を空ける。つまり GPU 解放時は「モデルを消す」のではなく、「VRAM から host RAM へ退避して希少な VRAM だけ空ける」わけだ。モデルの居場所は 3 つ。VRAM(実行の瞬間だけ)、host RAM(待機中ずっと。standby も先読み保持=~3 倍)、分散ストア(durable な原本、Raft ログにはポインタだけ)(§2・Q22・Q28・Q33)。to_cpu(host RAM 退避)と ⑦ 分散ストアへの checkpoint は役割分担で、矛盾しない。前者は次のセル実行を速くするため(host にモデルが残れば再実行は host→VRAM コピーだけ)、後者は耐障害性+他レプリカの先読み/即時昇格のためだ。代償は ~3 倍の host RAM だが、潤沢で安い host RAM を払って希少で高い VRAM を空けるという意図的なトレードオフになっている(3 レプリカは別サーバ分散なので 3 倍は 1 台に集中しない。Q50)。シーケンス図のキャプションに「to_cpu=VRAM→host RAM 退避」を明記した。
Q56. いつ host RAM で・いつ分散ストアで管理しているのかが分からない。これもシーケンス図で説明して。
A. §2 のモデル居場所図の直後に、1 回の実行サイクル(実行N → think time → 実行N+1)でモデルの居場所がどう動くかを示すシーケンス図(figures/model-location-sequence.svg)を追加した。答えを一言でいうと、host RAM は「常時」管理する場所(各レプリカが保持するワーキングコピー)で、実行の直前に VRAM へ載せ、直後に VRAM から戻すための出入り口になる。分散ストアは実行のたびに更新する durable な原本で、executor が実行後に書き戻し(checkpoint, write)、standby がそれを読み込んで(read)自分の host RAM に先読みするためのレプリカ間伝播の経路だ。Raft ログにはポインタ(ModelPointer)だけが載る。タイミングは、① 実行直前 host→VRAM(クリティカルパス, 数百ms)、② 実行直後 to_cpu で VRAM→host 退避+ストアへ checkpoint(非同期)、③ think time 中に Raft commit+standby がストアから host RAM へ先読み(非同期, IAT に隠す)、④ 次の実行で昇格レプリカが host→VRAM、という流れ。クリティカルパスに残るのは host⇄VRAM の数百ms だけで、ストア read/write や Raft 同期は IAT(中央値5分)の隙間に隠す(実装では Read/WriteOperationIsOnCriticalPath フラグで切替可)。
Q57. まだ分からない。ユーザがセル実行ボタンを押してから実行結果を返すまでのシーケンス図にして。実行N→セルN に変えて。
A. Q56 のシーケンス図を、ユーザ視点(ボタン→結果表示)を主軸にして描き直した(figures/model-location-sequence.svg、ラベルも実行N→セルN に変更)。混乱の元は「ストアへの書き戻しのタイミング」で、実は ⑧ 分散ストアへの checkpoint は ⑦ 結果表示の後に非同期で起きる(ユーザはそれを待たない)。図は 2 つの帯で色分けした。赤帯がユーザの待つ ②〜⑦(選挙→host→VRAM→セルN 実行→to_cpu 退避→応答)=クリティカルパス、黄帯が結果を返した後に裏で行う ⑧〜⑪(ストアへ書き戻し→Raft commit→standby が原本を download して host RAM に先読み)=IAT 中央値5分の隙間に隠す部分だ。だから「いつ host RAM、いつストア」は、実行のためには常に host RAM⇄VRAM(赤帯)、ストアは結果を返した後の永続化と standby への伝播(黄帯)、という時間関係になる。本文 §2 の図とキャプションを差し替え済み。
Q58. allocatable GPU と reserved GPU って何が違うの?
A. Figure 2(d)・Figure 14 に出てくる 3 段階の GPU 数で、関係は常に Allocatable ≥ Reserved ≥ Utilized になる。Allocatable(割当可能)はクラスタが払い出せる GPU の総供給量、つまり上限(プロビジョニング済みの天井)。Reserved(予約済み)はそのうちセッションが確保して握っている数(予約方式では計算していない think time も寿命いっぱい握る。論文 “sessions hold … for their entire duration, regardless of active use”)。Utilized(実使用)はそのうち今まさに計算に使っている数。つまり allocatable と reserved の違いは「供給の上限」と「そのうち需要側(セッション)が押さえた分」で、駐車場でいえば総区画数と予約札の入った区画の関係だ。予約方式の問題は Figure 2(d) の通り、Reserved が Allocatable に迫るのに Utilized は >81% アイドル(終盤 ~15%)という「予約 ≫ 実使用」の巨大ギャップにある。NotebookOS は「セル実行中だけ束縛+オーバーサブスクライブ」で Reserved を Utilized に近づけ、必要な Allocatable も減らす(Figure 14(a) は予約方式より少ない Allocatable で回せることを示す。Allocatable はオートスケールで時間変化する)。本文 Figure 2(d) の読み方に反映済み。
Q59. host RAM→VRAM は本当に数 ms でロードできるの? なぜ? どれくらいのサイズで・どれくらいの帯域・速度?
A. まず訂正すると、論文の表現は「数 ms」ではなく “a couple hundred ms”(数百 ms、~200ms 前後)だ。本文・各シーケンス図でもそう書いている。許容できる理由は「速いから」ではなく、ユーザの思考時間(IAT 中央値5分)に比べれば無視できるから(§2)。なぜ数百 ms で済むのか(サイズや帯域、速度の内訳)は、論文に一切記述がない。論文は数字を述べるだけだ。以下は論文外の一般的背景(GPU の物理)で、AI解説本体には入れない。host→VRAM は PCIe(または NVLink)越しの単純な連続メモリ転送で、PCIe Gen3 x16 ≈ 12GB/s(1GB で ~80ms)、Gen4 ≈ 25GB/s(~40ms)、NVLink は数百 GB/s(数 ms)。「a couple hundred ms」からの逆算だと、数 GB 級モデルを PCIe Gen3〜4 で載せる規模感だろう(あくまで推測)。速いのは、遅い分散ストア I/O(読み 3.95s、書き 7.07s、Figure 11)を IAT の裏に隠してあり、クリティカルパスに残るのが host RAM→VRAM の DMA コピー 1 回(帯域律速)だけだから、という設計の帰結だ。
Q60. レプリカが 2 じゃダメな理由がわからん。
A. Raft が過半数(quorum)で合意するからだ。過半数=floor(N/2)+1 で、N=2 の過半数は「2」になる。すると 2 つ問題が出る。(1) 故障耐性ゼロ。2 台中 2 台の同意が要るので、1 台でも落ちると過半数を作れず合意も選挙も止まる(冗長化したのに 1 台死で停止)。(2) タイブレーク不能(split-brain)。1 対 1 で割れたとき「多い側」が存在せず決着しない。つまり 2 は「冗長性を足したのに耐故障は N=1 と同じ(=0)」で、コストだけ増える。3 なら過半数(2)を 3 台中 2 台で満たせ、1 台落ちても続行できる最小構成になる(耐故障1)。偶数より奇数が効率的だ(4 でも過半数3、耐故障1 で 3 と同じ)。本文 §1「なぜ 3 なのか」に対応。
Q61. Raft を全く知らないからわからない。Raft の背景にあるものは何? 他の技術との関係は? 選挙の仕組みはがっつり Raft が関わる?(※下記の Raft 一般論は論文外の周辺知識)
A. 大元の問題は「分散合意(distributed consensus)」、つまり「複数台に同じデータ/決定を、一部が壊れても矛盾なく持たせたい」だ。1 台だと落ちたら終わりなので複製するが、複製すると「今の正しい値は誰が持つ?」が問題になる。この系譜に 2 相コミット(2PC)→Paxos(1998, Lamport, 難解)→Raft(2014, 理解しやすく再設計)→ZooKeeper/ZAB などがぶら下がる。Raft は「マシンは黙って落ちうるが嘘はつかない」前提(非ビザンチン)だ。中身は ① リーダー選挙 ② ログ複製 の 2 本柱で、両方が過半数を要求する(→ Q60)。NotebookOS は「1 カーネルを 3 台に複製」した瞬間に分散合意が必要になり、既製部品として Raft を差した(論文の新規性ではなく土台の流用)。選挙は確かに Raft が土台だが、「GPU が空いているレプリカを executor に選ぶ」という当選条件は標準 Raft にはなく、論文が Raft の上に独自実装した拡張だ(標準 Raft は“誰でもいい 1 台”を選ぶだけ)。
Q62. Raft は k8s とか kvs の分野で使われてる? いつくらいのアルゴリズム?(※論文外の周辺知識)
A. 合っている。Raft は「複数台で状態を一致させたい基盤ソフト」の心臓部で広く使われる。k8s は正確には本体ではなく状態保存の etcd が Raft で、分散 KVS(etcd や Consul、TiKV)はど真ん中の用途。ほか TiDB/CockroachDB(分散 DB)、Kafka(KRaft)、MongoDB(選挙)などがある。アプリ層でなくインフラ層の部品だ。発表は 2014 年(Ongaro & Ousterhout, “In Search of an Understandable Consensus Algorithm”)で、1998 年の Paxos が難解すぎる問題への「理解しやすい後継」という位置づけ。比較的新しい(10 年強)。
Q63. Global Scheduler と Local Scheduler の実態は? web サーバ? ZMQ をプロキシしてる? Local Scheduler の存在理由がわからん、いらなくない?
A. 実体は(実装 ds2-lab/NotebookOS で確認)、Global Scheduler = Cluster Gateway(クラスタに 1 つ、gRPC サーバ既定 8080)、Local Scheduler = Local Daemon(各 GPU サーバに 1 つ常駐するデーモン)だ。web サーバ(HTTP)ではなく制御は gRPC(HTTP&WebSocket はユーザ⇄Jupyter Server の所だけ)。「ZMQ をプロキシ」は半分正解で、二層に分かれる。制御プレーンが gRPC(StartKernelReplica 等の命令)、データプレーンが ZMQ 転送(Jupyter のセル実行メッセージを Global→Local→対象レプリカへ中継、ここがまさに ZMQ プロキシ)。Local Scheduler が要る理由は、各マシンの手足だからだ。コンテナ起動(ローカルの Docker デーモン)、GPU 実状態の取得(NVML)、レプリカへの ZMQ ローカル接続は、そのマシン上で動くプロセスにしかできない。中央 1 個の Global からリモート全マシンの Docker や GPU を直接いじれない。これは分散システムの定石で、中央の頭脳+各ノードの常駐エージェントという形。k8s の kube-scheduler/api-server(頭脳)+各ノードの kubelet(現地エージェント)とちょうど同じ関係だ(kubelet が要らなくないのと同じ理由で Local Scheduler も要る)。
Q64. provisioner が Global Scheduler に gRPC でコンテナ起動や GPU 割り当てを命令する、ということ? provisioner の実体は何? どこでどう動く? CPU サーバと GPU サーバがあるんだっけ?
A. 「命令」よりは「カーネルを起こしてくれと依頼を投げる入口」だ。provisioner が出すのは StartKernel RPC(=「このカーネルを起動して」)だけで、GPU 割当や 3 レプリカの配置、選挙を決めるのは Global Scheduler 側になる。指揮系統は provisioner ─StartKernel→ Global ─StartKernelReplica→ Local ─→ コンテナ起動(注文の窓口/割当を決める頭脳/現地で作る手足)。provisioner の実体は、独立サーバではなく Jupyter Server プロセス内にロードされる Python クラスだ(Jupyter 標準の Kernel Provisioning フレームワーク、KernelProvisionerBase 継承)。標準の LocalProvisioner は同ホストに子プロセスで fork するが、NotebookOS の GatewayProvisioner は「ローカル起動」を「gRPC でリモート起動を依頼」に差し替えてある。CPU/GPU サーバの物理二分は論文に明示されていない。主役は GPU サーバ群で、GPU を持たない Jupyter Server がフロントに別途居るとは言えるが、「CPU 状態/GPU オブジェクト」は状態の所在の話であってサーバ種別ではない(混同しやすい点)。本文の Provisioner 説明+ LocalProvisioner と GatewayProvisioner の比較図 に反映済み。
Q65. Raft の処理はどこでやってる? Raft ログってどこにある? ポインタ複製の発火は誰がどうやってする?
A.(実装 ds2-lab/NotebookOS で確認)Raft の処理は 3 つのカーネル レプリカ(コンテナ)の中で行い、3 レプリカがピアツーピアで直接合意する(Global/Local Scheduler は合意の参加者ではなく、転送と資源会計の係)。executor が Leader、standby 2 つが Follower だ。Raft ログは 3 レプリカそれぞれが自分のコピーを保持し(複製ログが Raft の要)、中身は小 CPU 状態+ポインタ(ModelPointer/DatasetPointer)だけ(モデル実体はログに入らず分散ストア)。ポインタ複製の発火連鎖はこうだ。① executor が実体を分散ストアへ書く → ② executor(Leader)が ModelPointer を Raft ログに propose(提案)=発火の起点(Leader だけが提案できる)→ ③ Raft が follower へ複製、過半数 ack で commit → ④ commit 時に全レプリカで __model_committed コールバックが発火 → ⑤ 提案元でない standby が __load_model_from_remote_storage で実体を download し host RAM に先読み。本文 §3 + Raft の処理場所・ログ・ポインタ複製の発火図 に反映済み。
Q66. 3 つのレプリカは別々のサーバにあるんだよね。N 台のサーバのうちいずれか 3 台にレプリカが作られるはず。そのアルゴリズムは?
A. その通りで、N 台の GPU サーバから 3 台を選び、1 サーバ 1 レプリカで分散する(論文 §3.2.1 に明記)。アルゴリズムは 2 段階だ。(1) 候補(viable candidate)の絞り込み。Global Scheduler が全サーバを走査し、ユーザの resource request(CPU=millicpu/メモリ=MB/GPU 数/VRAM=GB)を満たす容量があるサーバを候補にする(“If a server meets the requirements, this server becomes a candidate.”)。加えてオーバーサブスクライブ会計上、クラスタ全体 SR ≤ 1 を崩すサーバは弾く。(2) 候補が 3 より多ければ(N>3)pluggable ポリシーで 3 台選抜する。既定は least-loaded(“the least-loaded hosts—those with the fewest actively used GPUs—are chosen”=今アクティブに使用中の GPU が最少のサーバ)。選んだ各サーバの Local Scheduler に StartKernelReplica RPC を 1 つずつ発行する。候補が 3 台に満たなければ pluggable handler 経由でスケールアウトし(“initiate a scale-out operation to provision however many additional servers are required”)、サーバを増設してから配置する。要するに bin-packing でもランダムでもなく、least-loaded(負荷分散寄り)が既定で、ポリシーは差し替え可能だ。least-loaded を選ぶのは「実行時に各レプリカが GPU を取れる確率を上げ、移行なしの即時 executor 化(標準 89.6%)を狙う」ためと整合する。本文 §1 + レプリカ配置アルゴリズム図 に反映済み。
Q67. GPU サーバのスケールアウト/スケールインのアルゴリズムをもっと詳しく。auto-scaler のフローが分からないのでフローチャートを描いて。(scale-out と 1.05 は同じものを制御するイメージ?)
A. ほぼその通り。ΣG' = f·ΣC(f=1.05)は 1 つの「目標プロビジョニング容量」で、ΣC は今 commit 中=実行中の GPU 数(瞬時の実需要)だ。auto-scaler(Global Scheduler 内の、設定インターバルでポーリングするリアクティブ閉ループ、予測なし)は毎周 ΣC を測って ΣG'=1.05·ΣC を出し、現在のプロビジョニング容量と比較する。現在 < ΣG' なら scale-out(容量 ≥ ΣG’ まで増設)、ΣG' < 現在 なら scale-in(idle サーバ=アクティブ訓練レプリカ無しを 1〜2 台ずつ、条件が消えるまで反復)。だから「scale-out と 1.05 が別々」ではなく、ΣG'=1.05·ΣC という同じ目標に現在容量を追従させ、下回れば out、上回れば in する(容量ベースの out/in は同じ目標の表裏)。ただし scale-out には 1.05 を通らない 2 本目の経路があり、レプリカ配置失敗(候補が 3 台揃わない)瞬間にイベント駆動で即 out する(§3.4.2 のトリガ (1))。elasticity 観点の未記載点としては、予測なし(完全リアクティブ)、明示的 hysteresis/cooldown なし(減衰は 1〜2 台ずつのみ)、scale-in 時の standby 退避手順、1 回の増設台数、既定インターバル未記載、f=1.05 は経験則、といったあたりが挙がる。フローチャートを本文 §4 に追加(autoscaler-flowchart.svg)。
Q68. auto-scaler の設定インターバルは何秒?(GitHub にも書かれてない?)
A. 論文には記載がないが、実装(ds2-lab/NotebookOS)には既定値がある。30 秒だ。common/scheduling/constants.go に DefaultScalingIntervalSeconds = 30、options.go の既定も ScalingIntervalSec: 30 で、未設定(≤0)なら 30 にフォールバックする(GetScalingIntervalSec())。設定キーは scaling-interval(秒)で、説明は “Interval to call validateCapacity, in seconds. Set to 0 to disable routing scaling.” インターバルごとに validateCapacity(=容量チェック、ΣG’ 比較)を呼ぶ周期そのもので、0 にするとオートスケール無効になる。配布サンプルの実値は docker 単機サンプルが 15 秒、helm/ansible 既定が 30 秒。論文 §3.4.2 は “runs on a configurable interval” としか書かないが、実装の既定は 30 秒だ。なお同じ constants.go に DefaultMaxSubscribedRatio = 7.0 がある(SR の実装上限の既定は 7.0 で、理論の「≤1 で衝突なし」より攻めた設定)。elasticity 観点では、この 30 秒という制御ループのサンプリング周期が論文側で定量化・感度分析されていないのが穴といえる。
Q69. ΣC の定義がわからん。
A. ΣC は §3.4.2 で “the total number of GPUs actively committed (∑C) to kernel replicas (that are actively executing GPU code)” と定義され、「今まさに GPU コードを実行中(commit 中)のレプリカに束縛されている GPU 数」をクラスタ全体で合計した値だ。standby レプリカの GPU や空き GPU は含まない。区別すべきものが 3 つある。ΣS(予約・subscribed)=要求 GPU の総和(SR の分子、物理超えうる)、ΣC(実行中・committed)=今走っている GPU 数(auto-scaler が追従、IDLT では ΣC ≪ ΣS)、ΣG’(目標)=1.05·ΣC。本文 §4 のフローチャート付近に定義図(sigma-c-definition.svg)を追加。なお旧「数式・アルゴリズム」節は §4 と重複するため削除した。
Q70. ノードの起動時間によりセル実行が遅くなるってのはないのかね?
A. ある。ただし限定された局面でだ。通常のセル実行は「3 レプリカのどれかが即 GPU を確保(標準 89.6%)」か、ダメでも「既存の空きサーバへのレプリカ マイグレーション」で済み、新規ノード起動は絡まない。ノード起動が効くのは、3 レプリカを置ける候補サーバがクラスタに 1 つも無く scale-out が走る最悪局面だ。このとき論文は “the placement of the corresponding kernel replicas is paused”(配置を一時停止=待つ)と明記しており、新サーバが立ち上がるまでカーネルの配置(≒その初回実行)は待たされる。緩和策として “Resources are immediately reserved for the paused kernel replicas on newly provisioned servers, i.e., before the servers are fully added to the NotebookOS server cluster”(完全に参加する前に資源を先行予約)を置くが、サーバ起動時間(boot/cold-start)の数値も、scale-out 全体の所要時間も論文は一切示していない。だから「飽和時のカーネル配置はノード起動レイテンシを被りうるが、定量化されていない」が正確な答えになる。これは予測スケーリングや暖機ノード プールで先回りできるはずの所で、ElasticHub 的には「リアクティブゆえに飽和時の配置がコールド ノード起動を待つ」弱点として対置できる(§4)。
Q71. 「SR>1=オーバーサブスクライブ」「ΣC≪ΣS だから実際にはぶつからない」が分からない。図で解説して。
A. オーバーサブスクライブとは、物理にある以上の GPU を「予約」として配ることだ(飛行機の overbooking =座席 100 なのにチケットを 110 枚売る、と同じ。SR>1 がこの状態)。破綻しない理由は、IDLT のデューティ比が低いからだ。タスク実行は中央値 ~2 分だが次の実行までの間隔(IAT)は中央値 ~5 分なので、1 カーネルが実際に GPU を使うのは時間のごく一部にすぎない。予約した多数のカーネルは大半が think 中(GPU 不要)なので、どの瞬間で時間軸を縦に切っても「今実行中の数(ΣC)」は物理 GPU 数に収まる(ΣC ≪ ΣS、ΣS=予約総数)。実際にぶつかるのは同じ瞬間に物理 GPU 数を超えて実行したくなった時だけで、そのときは溢れたレプリカを空きサーバへマイグレーションし、無ければスケールアウトで吸収する。IDLT は同時実行が疎なのでこの衝突は稀だ(標準 89.6% は移行なしで即実行)。時間軸の図(8 カーネルが物理 2 GPU を分け合い、t=5 の瞬間に実行中は K3・K4 の 2 つだけ)を本文 §4 に追加(oversubscription-timeline.svg)。要は、予約は時間方向に重ねて配る(overbooking)が、瞬間ごとには物理に収まり、たまの衝突だけ移行/増設で救う、という構図だ。
Q72. 対話遅延・TCT・IAT の関係の図を、Figure 9 に出てくる言葉に揃えて。
A. Figure 9 の用語((a) 対話遅延 interactivity delay、(b) TCT task completion time、9(b) の軸ラベルは “Latency”、IAT inter-arrival time)に合わせて delay-tct-iat.svg を作り直した。1 セルのタイムライン上で、(a) 対話遅延は execute_request 送信→実行開始(実行時間は含まない、x 軸=秒、=Fig 9(a))、(b) TCT は送信→完了(=execute_reply まで。実行時間+事前・事後 I/O を含む、軸ラベル “Latency”、=Fig 9(b))、次の実行までの think time が IAT。関係は TCT = 対話遅延 + 実行時間 + 事後処理。Raft 同期や大オブジェクト I/O はこの IAT の隙間に隠して対話遅延に出さない。本文 Figure 9 直下に反映。
Q73. Figure 9(b)(TCT)で、NotebookOS が baseline の Reservation より良く見える範囲があるのはなぜ?
A. 結論から言うと、論文は「NotebookOS が Reservation より良い」とは主張していない。§5.3.3 の原文は “NotebookOS achieves a TCT distribution comparable to Reservation, with slightly higher TCTs from the 38th to the 90th percentile“、つまり「Reservation と同等、ただし 38〜90 パーセンタイルだけ少し遅い」だ。その範囲が遅い理由も明記されている。オーバーサブスクライブでサーバの GPU が満杯になると別サーバへマイグレーションし、さらに暖機コンテナを使い切ると新規コンテナをコールドスタートするためだ。Reservation は GPU をセッション中ずっと予約していて束縛オーバーヘッドがゼロ、しかも Figure 8 で全方式中いちばん多く GPU を確保していて GPU 待ちも起きないので、TCT の構造的な下限(ベスト)になる。よって NotebookOS が Reservation を系統的に上回ることはない。0〜38・90%tile 超では両者はほぼ重なる(comparable)ので、そこで NotebookOS が一瞬左(速い)に見えても、それは「同等」の重なりの中での実行ごとのばらつきであって、設計上の優位ではない。
この「ばらつき」の出どころも書いておく。Figure 9 はシミュレーションではなく実機(プロトタイプ)の結果だ(§5.2 Prototype Evaluation 配下。AWS EC2 8GPU×30 台で実際の DL 訓練を 17.5 時間、モデル/データは S3 から取得。シミュレーションは §5.5 の別物)。論文自身も “Executing the same workload on NotebookOS multiple times will generate approximately the same results, with small differences resulting from scheduling decisions and other random factors” と実行ごとの差を認めている。源は主に、(1) タスク構成がランダムなこと(ワークロード ドライバが各クライアントにアプリ領域→データセット→モデルをランダム割り当て。§5.1.2。方式ごとに別実行なら短/長ジョブの混ざり方が変わり CDF がズレうる)、(2) 実 GPU 訓練時間のゆらぎ、(3) S3/ネットワーク I/O のレイテンシ変動、(4) コンテナ起動・選挙・スケジューリングのタイミング ジッタ。論文の主張は「Reservation 並みを、ずっと少ない GPU で達成」であって、「Reservation に勝つ」ではない。本文 Figure 9 の読み方に反映。
Q74. Batch について。delay では NotebookOS との差はせいぜい ~30s(しかもなぜ 0%tile 付近でそんなに遅い?)なのに、latency では 0%tile 付近で桁違いに大きい差になるのはなぜ?
A. 「なぜ Batch は最速でも ~30s か」というと、Batch は提出のたびにカーネル/コンテナをオンデマンドでコールド起動し、FCFS で空き GPU を待つからだ(NotebookOS は長命レプリカを使い回すので ms)。差が delay と latency で大きく変わるのは 3 要因の重なりによる。(1) 軸が違う。(a) delay は線形・秒(0〜270s)、(b) TCT は対数・ミリ秒(10⁴〜10⁶ ms)。対数軸では 1 目盛り=10 倍なので、線形で 30s の差が対数では桁違いに見える。(2) 測る区間が違う。delay は「実行が始まるまで(起動+GPU待ち)」だけ。TCT はそこに、delay に入らない「提出ごとに必須のモデル/データ I/O(事前ロード+事後書き戻し)」(§5.3.3: “mandatory pre- and post-processing data I/O … for each submission”)が上乗せされる。NotebookOS はモデルを host RAM に温存し、I/O を IAT に隠すのでこれが TCT に乗らず、差が開く。(3) 短いタスクほど固定費が支配的になる。低パーセンタイル=実行時間が短いタスクで、Batch の固定オーバーヘッド(起動+I/O)が短い実行を飲み込み、NotebookOS ~10⁴ms に対し Batch ~10⁵ms と約 1 桁開く。本文 Figure 9 の読み方に反映。
Q75. レプリカが 1 だとダメな理由は? モデルを host RAM に置いておくなら 1 でもいいのでは? 単に空いている確率を上げるだけ?
A. 「確率を上げるだけ」ではない。ポイントは「モデルが host RAM にある」と言っても、それは”どのサーバの” host RAM か、というところだ。R=1 だとモデルが温まっているのはそのカーネルが載る 1 台の host RAM だけで、そのサーバの GPU が満杯なら、他サーバに空き GPU があっても即使えない(他サーバの host RAM にモデルが無い)。使うにはマイグレーション、つまり小 CPU 状態を移しモデルをストアから新サーバの host RAM にロード(数秒の遅い I/O)が必要で、これが毎回クリティカルパスに乗り対話性が壊れる。R=3 なら Raft commit 時に standby も __load_model_from_remote_storage で自分の host RAM にモデルを先読み済みなので、3 台のうち空き GPU のあるサーバのレプリカはモデルが既に温まっており、host→VRAM(数百ms)だけで即実行できる(移行もストア読みも不要)。つまりレプリカの役割は、空き GPU と”温まったモデル”を同一サーバに同居させておくことにある。確率を上げる効果もあるが、より重要なのは見つけた空き GPU を移行 I/O 抜きで即使えるようにすることだ。加えて R=1 は冗長性ゼロだ(そのサーバ/レプリカが落ちればセッション喪失、Raft 合意も不成立)。Q17 の「都度移行ではダメ」と同じ論点。
Q76. 「89.6% が即 GPU 獲得」と書いてあるが、delay の CDF だと x≈0 で 70% くらいに見える。違わない?
A. 矛盾ではなく、別々の量を見ている。89.6% は §5.3.2 の “commits GPUs … immediately upon receiving an execution request”、つまり要求時に移行なしで GPU を割り当てられた割合(スケジューリング成功率)で、delay CDF の x=0 の y 切片ではない。即 commit のタスクも遅延 0 ではなく、選挙(数十ms)+host→VRAM(数百ms)がかかるので、小さい遅延(〜1 秒未満)に分布する。だから x≈0(≒70%)はほぼ遅延ゼロのタスク割合で、そこから選挙+ロードのぶん右に進んで約 89.6% に達する(残り約 10.4% は移行/コールドスタートで右の裾〜270s へ)。なお、ノートに「90%ile で約 50ms」と書いていたが、これは論文に無い数字だったので削除した(論文が言うのは「選挙はせいぜい数十ms」というステップ単体の値のみ)。
Q77. 「実行要求を受信するとすぐに GPU をカーネルレプリカに割り当てます(89.6%)」の「すぐ(immediately)」の定義は?
A. ここでの「すぐ」は、「実行要求が届いた時点で、追加の待ちなし(マイグレーションやスケールアウトで GPU が空くのを待たずに)GPU を束縛できた」という意味だ。具体的には「3 レプリカのうち少なくとも 1 台に空き GPU があり、その場で commit できた=移行不要だった」という条件になる。反対の約 10.4% は「どのレプリカのサーバにも空き GPU が無く、マイグレーション/コールドスタートで待った」ケース。注意したいのは「すぐ」=「遅延ゼロ」ではないことだ。即 commit でも選挙(数十ms)+host→VRAM ロード(数百ms)はかかる。つまり 89.6% は資源確保が”待ち 0”(移行不要)という意味で、実行開始までの時間が 0 という意味ではない(Q76)。
Q78. Figure 8 で NotebookOS の線(水位)はなぜ変動がこんなに小さいの? GPU はセル実行時にだけ provision しているのでは?
A.(※当初「セッション数に比例」と書いたが誤りだったので全面訂正する。standby はオーバーサブスクライブの原則どおり GPU を握らないので、provisioned GPU は「3×セッション数」にはならない。)まず縦軸ラベルは “Provisioned GPUs”=GPU 数(node 数ではない)。ただしプロビジョニングはサーバ単位で起こる(1 台で 8 GPU 分まとまって増える)ので、「起動サーバ数×GPU数」を GPU 数で合算した値だ。次に線の正体は、オートスケーラが維持するプロビジョニング容量 ΣG′ = 1.05·ΣC(§4)。ΣC はその瞬間にクラスタ全体で実行中(commit 中)の GPU 数の瞬時値で、1.05 はバースト用 5% バッファだ。つまり線は全ユーザの同時実行数の合算 ΣC に追従しており、セッション数でも個々のセル実行でもない。変動が小さい理由は 2 つある。(1) 統計多重(推論)。ΣC は「実行 ~2分/間隔 ~5分」の低デューティ比カーネルを数百個ぶん合算した量なので、1 人ぶんは鋭いパルスでも誰かが始め誰かが終わり、合算はほぼ一定になる(プール効果で ΣC(t) 自体が滑らか)。(2) スケールインを鈍らせている(論文明記)。scale-in は idle サーバを 1〜2 台ずつしか解放しないうえ 5% バッファ込みなので、バーストが引いても水位がカクッと落ちない。対照的に Batch はバッファ無しで実行が終わるたび即手放す(質問者の想像どおりの挙動)ため、より Oracle 近くまで落ちてギザギザに追随する。なお、長命レプリカの常駐は「Batch より少し高い位置(オフセット)」の理由ではあっても、滑らかさの主因ではない(Q40・§実験・結果)。
自分のコメント
(ここは自分で都度書く欄。例:「3 レプリカ+実行時だけ GPU 束縛」のモデルが、自分のクラウドバースティング/資源スケジューリングの設計にどう接続できるか確認したい。)