AI解説
全文PDF: https://aclanthology.org/D19-1546.pdf(arXiv版 https://arxiv.org/abs/1910.02216) 情報源: ACL Anthology の全文PDF(本文・図1〜3・表1〜8)を精読。図はPDF該当ページから切り出して
figures/に格納(arXiv HTML版は取得できず 404)。本ノートはこの全文の範囲で記述する。
一言で
Jupyter ノートブックの NL(markdown)と code セルが交互に並ぶ履歴を文脈として、次の target code セルを生成する、という「対話的プログラミング(interactive computing, IC)」のコード生成タスクを定式化した論文。そのために、GitHub から集めた 約 150 万件の訓練データと、nbgrader 等の課題ノートブックから人手品質で作った 3,725 件の dev/test を備えた大規模データセット JuICe(Jupyter Interactive Computing) を構築・公開し、neural baseline(LSTM / Transformer)と retrieval baseline を評価した。
問題(problem)と課題(task)を分けて
- 問題(解きたい本質): NL からのコード生成研究は、これまで 単一の NL 発話 → 1行/特定ドメインのコード に偏っており(CoNaLa、Django、Hearthstone/MTG、CONCODE など)、(a) 過去の NL・コードの履歴に条件づけた生成や、(b) オープンドメイン(多様な python パッケージ・領域)の大規模設定が扱えていない。さらに、大規模データセットは訓練・テストを同じ noisy なスクレイプ元から無作為分割するため、高品質なテストセットを安価に作れないという積年の難しさがある。
- 課題(この論文がやること): IC パラダイムでのコード生成タスクを導入し、(1) オープンドメイン大規模な訓練データと (2) 人手品質の curated dev/test を両立する JuICe を作る。その上で 2 つの生成タスク(API シーケンス生成 / フルコードセル生成)で baseline を評価し、文脈量・訓練データ量が性能に与える効果を測る。
タスク定義
ノートブックの target セルの上にある文脈セル(NL または code)を距離 d(target からの近さ、d=1 が直上)で並べ、それらに条件づけて target セルを生成する。論文では target NL(直前の markdown)を必ず含む code セルだけを対象にする。2 つのタスク:
- (2) フルコード生成タスク: target セルの コードスニペット全体を生成。
s(i)= target セルのコードトークン列。 - (1) API シーケンスタスク: target セル内の コンストラクタ/メソッド呼び出しの列だけを生成(
a(i))。変数や引数までは作らず、より緩い設定で対話的補助として有用。rangeのような頻出キーワード関数は対象外。
モデルでは文脈の距離を最大 K セルに制限する。

Figure 1(論文 Figure 1): NL markdown と code セルが交互に並ぶ python ノートブック。左の d は target セルからの距離。「Create and train the model」という直前 NL と、それ以前の NL/code 履歴(X_train, y_train の定義など)から、青の target セル(DecisionTreeClassifier() と fit())を生成するのがゴール。直前 NL だけでは「決定木を使う」「どの変数を train/test にする」かは決まらず、履歴に条件づけた判断がこのタスクの中心的な難しさだと示す例。
データセット構築
訓練セット(distant supervision 側)
- 2019年5月以前に GitHub 上で公開された全 Jupyter ノートブックを集め、英語 markdown かつ Python 2/3 カーネルに絞る。NL の存在が品質と相関すると見て、code セル数が NL セル数の 3 倍を超えるノートブックを除外 → 約 659K ノートブック。各ノートブックは平均 39 NL/code セル、数千ドメインの python パッケージを使う。
- 各 code セルが訓練例候補。直前セルに NL markdown がある code セルだけを target とする。target は 構文的に妥当な Python かつ メソッド定義は高々 1 個。Iyer et al. (2018) に倣い文字列を canonicalize、最大 120 code トークンに truncate。
- これで 400 万件超の (target, context) 例が得られ、target+context が一意になるよう 150 万件にダウンサンプリング。
人手品質の dev/test セット
noisy なオンラインソースではなく、プログラミング課題ノートブックを使って高品質テストを安価に作る、というのが肝。
- nbgrader 課題: 教員が nbgrader で作る採点付き課題。各 code セルのメタデータに「配点・一意ID・自動/手動採点・boilerplate・教員解 or 学生提出」等が埋まる。GitHub からメタデータ付き nbgrader ノートブックを 13,905 件収集。問題IDと配点で同一プロンプトへの学生提出をまとめる(1 プロンプトあたり平均 8.9 提出)。メタデータが全テストケース成功を示す提出を正解とし、複数あれば無作為に 1 つ選ぶ。教員提供の boilerplate は target セルから抜いて文脈側へ移す。→ 1,510 件の nbgrader 課題問題。
- in-class exercise(授業内演習): タイトルに
solutionを含むノートブックを集め、同一リポジトリの exercise ノートブック(セルの 50% 超が一致し、タイトルに solution を含まない)と対にする。差分セルが解にあたる。教員解の妥当性は、同じノートブック・解が他の 2 リポジトリ以上に存在することで確認。170K の対が見つかり、ここから 2,215 件の演習問題を採用。 - 合計 1,510 + 2,215 = 3,725 件を無作為に dev/test へ分割。target セルには訓練と同じチェックを行い、Python 2 の解は Python 3 へ変換。

Figure 2(論文 Figure 2): 教員が用意した nbgrader 課題。先に読み込んだデータ(data = read_csv('globalterrorism.csv'))を使って学生が青セル(年ごとの集計+折れ線プロット)を埋める。解が埋め込まれた状態で GitHub に投稿されるものを利用し、高品質な dev/test を作る。
統計(表2)
| Train | Dev/Test | |
|---|---|---|
| # Examples | 1,518,049 | 1,744 / 1,981 |
| Avg Context Cells | 29.9 | 28.3 |
| Avg NL Tokens | 39.6 | 57.2 |
| Avg Code Tokens | 38.8 | 33.7 |
| # Unique NL Token | 851,127 | 11,142 |
| # Unique Code Token | 1,001,289 | 5,113 |
| % Use variables above | 45.3 | 58.6 |
| % Use methods above | 6.4 | 8.2 |
| % Contextual | 48.2 | 61.9 |
| % Multi-cell | 19.7 | 29.0 |
表2(論文 Table 2): 「Contextual」は上の文脈の変数/メソッドを使う例の割合(NL に出てこないものだけを数えて文脈推論を厳密に測る)、「Multi-cell」は 2 つ以上の異なる code セル由来の変数/メソッドを使う例。dev/test の方が NL が約 20 トークン長く、contextual/multi-cell の比率も高い。
表1(論文 Table 1, 図は本文の表のみで数値なし): JuICe を CONCODE / CoNaLa / ATIS / SequentialQA / SCONE と 「文脈依存・オープンドメイン・大規模・curated dev/test」の 4 軸で比較。履歴に条件づける既存データは小さく特定ドメイン、大規模データは単純な 1 行生成にしか人手 curated test を持たない——JuICe は 4 軸を同時に満たす唯一、という主張。
データの質・内容の分析
- NL 分析(dev 50 件, 表3): 43% が宣言/疑問形の高レベル抽象表現、27% が使う変数/関数を明示、20% が引数を明示、16% が行ごと対応。さらに 11% は同ノートブックの遠い markdown を参照、9% は入出力例で言語を補足、7% は数式で意図を形式的に指定。
- コード分析(dev 50 件, 表4): データサイエンス中心。Data Exploration 25% / Data Wrangling 23% / Machine Learning 20% / Miscellaneous 16% / Visualization 13% / Systems 3%。
- 品質評価(train/dev 各 50 件): 「NL と文脈だけで target を生成できる十分な手がかりがある」例を良質とすると、train は 68%、dev は 96% が解ける。train の noise の多くは target NL が別 code セルを指してしまう例。
- 文脈推論(50 件, 表5): 86% が何らかの文脈推論を要する。上で定義/使用した変数・関数を使う 48%、データの性質・構造の理解を要する 39%、ノートブック固有のコーディング作法/イディオムの再利用 25%、3 セル以上にまたがる multi-cell 推論 23%。
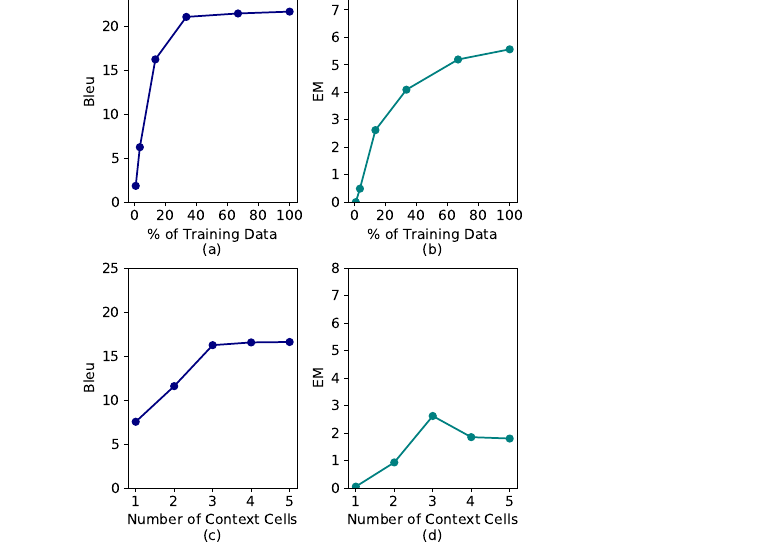
Figure 3(論文 Figure 3): (a)(b) は LSTM(3-ctx) で訓練データ量を増やしたときの BLEU/EM。データを増やすほど改善するが約 200K 例で頭打ち。(c)(d) は 200K 例で訓練した LSTM の文脈セル数の効果。3 セルまでは改善、その後は長文脈の扱いが難しく頭打ち〜悪化(入力長が平均 156 トークンを超えるあたり)。
問題定式化とモデル(baseline)
文脈は K=1(直前 NL のみ)と K=3 の 2 設定。各文脈セルは 75 トークンに truncate(ただし target NL セルはそのまま)。fairseq を使用。
- Retrieval: 直前 NL(
c1)だけで訓練コーパスから類似コードを引く。tf-idf ベクトルの cosine 類似度で測る。Ret-Train(直前 NL 下の code を全訓練集合から最類似で)と Ret-Context(文脈中の全cdから最類似 NL の下の code を)。retrieval は全文脈にアクセス可(K=|c|)。 - LSTM with Attention: n 層 BiLSTM エンコーダ + LSTM デコーダ(Luong 2015 の global attention)。文脈
c1..KをCODE/MARKDOWNの区切り記号で連結して入力。 - Transformer: Vaswani 2017。入出力は LSTM と同じ。
ハイパラ: 埋め込み 1024、NL/code 語彙を統合し BPE 10,000 merges、LSTM は 2 層 hidden 1024・dropout 0.5・40 epoch・Adam lr 0.001・beam 5。Transformer は 6 層・4 head・dim 512・FF 1024・lr 0.0005・warmup 2000・200 epoch。Seq2Seq は最初 100K 例で比較し、最良設定で全データ訓練。
評価指標
- フルコード生成: Exact Match(EM) と corpus-level BLEU(部分点の代理)。
- API シーケンス: 平均 API 列長が 3.8 と短く BLEU/EM が不適なので、予測 API を集合とみなした Precision/Recall を gold API 集合に対して計算。
主な結果
フルコード生成(表6, Dev/Test の BLEU/EM):
| Model | K | N | Dev BLEU | Dev EM | Test BLEU | Test EM |
|---|---|---|---|---|---|---|
| Ret-Train | - | 100,000 | 5.52 | 0.82 | 4.76 | 0.48 |
| Ret-Context | |c| | - | 3.42 | 0.12 | 3.24 | 0.00 |
| Transformer | 1 | 100,000 | 3.57 | 0.00 | 3.21 | 0.00 |
| Transformer | 3 | 100,000 | 10.90 | 0.27 | 11.08 | 0.38 |
| LSTM | 1 | 100,000 | 7.35 | 0.05 | 7.92 | 0.14 |
| LSTM | 3 | 100,000 | 15.88 | 1.42 | 17.03 | 1.33 |
| LSTM | 3 | 1,518,049 | 21.66 | 5.57 | 20.92 | 5.71 |
API シーケンス(表7, Precision/Recall):
| Model | K | N | Dev P | Dev R | Test P | Test R |
|---|---|---|---|---|---|---|
| LSTM | 1 | 100,000 | 34.15 | 29.19 | 30.38 | 26.98 |
| LSTM | 3 | 100,000 | 37.09 | 31.48 | 37.44 | 33.23 |
| LSTM | 3 | 1,518,049 | 51.34 | 44.83 | 52.60 | 46.46 |
- すべての LSTM が retrieval baseline を BLEU で 2% 以上上回る。文脈量(K=1→3)と訓練データ量を増やすと両タスクとも改善し、最良は LSTM・K=3・150 万例。
- 全文脈にアクセスできる retrieval が大きく劣るのは、文脈の code は target と異なることが多く、どの断片を取り込むかをモデルが推論する必要があることを示す。
- 人手性能の見積り(test の一部の学生解を利用): フルコード生成で BLEU 60% / EM 23%(識別子の canonicalize でさらに上がりうる)、API タスクで Precision 84% / Recall 85%。モデルとの差が大きく、改善余地が大きい。
エラー分析(表8, 最良モデルの dev 50 件)
Challenging NL Reasoning 39%(NL の意図を誤解し全く違うコード)、Arguments Missed 17%(位置引数の欠落)、Contextual Reasoning 26%(文脈理解不足)、Needs Longer Context 10%(3 セルでは足りない)、Partially Correct 26%(一部正しいが細部欠落, 例: 軸ラベル漏れ)、Semantically Equivalent 15%(意味的には等価だが表層が違う)。30% 超がより深い文脈推論を要する。将来は実行して出力比較や nbgrader テスト通過の検証が有効だが、現状 canonicalize している文字列を正しく生成する必要がある、と述べる。
まとめ・位置づけ
IC パラダイムでの文脈付きコード生成タスクを導入し、オープンドメイン大規模訓練(GitHub 由来 150 万例)と nbgrader/in-class 由来の高品質 dev/test(3,725 例)を両立する JuICe を公開。distant supervision(大規模訓練)と文脈の両方が効くが、現行手法には大きな改善余地が残る、というのが結論。ATIS の context-dependent semantic parsing と近いが、ATIS は過去クエリを改変して次を作れるのに対し、本タスクの code セルは過去のコードとほぼ disjoint な点が違うと整理している。
Q&A
(自分がAIに実際に質問したことだけを Q/A 形式で残す。まだなし。)
自分のコメント
(ここは自分で都度書く欄。まだなし。)